零基础怎么入门Python自然语言处理?

自然语言处理(natural language processing,NLP)是指与语言有关的各种计算技术。这是一个广泛的领域,但我们这里只介绍几种相关的技术,它们简约却不简单。
1. 词云
在第 1 章(点击蓝字可直接跳转阅读)中,我们曾经计算过用户兴趣词汇的数量。为了使单词及其数量可视化,一种方法是使用词云,它不仅能够以艺术化的形式展示单词,而且还能使单词的大小与其数量呈正比。
但是,一般情况下,数据科学家并不看重词云,这在很大程度上是因为单词的布局没有任何特殊意义,顶多意味着“这里还有一些空,可以放上一个单词”而已。
当你不得不生成一个词云的时候,不妨考虑一下能否透过词的坐标传达某些东西。举例来说,假如你收集了一些与数据科学相关的流行语,那么对于每一个流行语,你可以用两个介于 0 至 100 之间的数字来描述,第一个数字代表它在招聘广告中出现的频次,第二个数字是在简历中出现的频次:

词云的做法,只不过就是利用很酷的字体把各个单词布置到页面上罢了(图 21-1)。

图 20-1:由热门术语组成的词云
这看起来虽然整洁,但并没有告诉我们任何事情。一个更有趣的方法可能是将它们分散开来,利用水平位置表示其在招聘广告中的流行度,用垂直位置表示其在简历中的流行度,这样就能形象地传达一些信息(图 21-2):

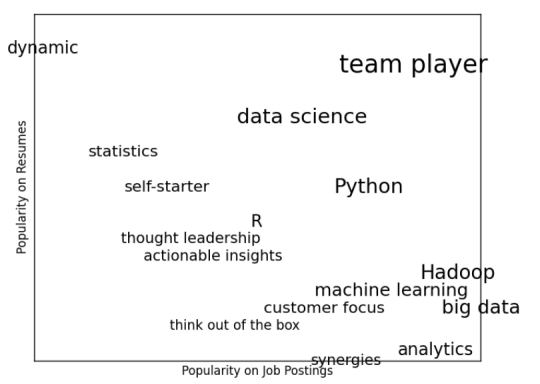
图21-2。一个更有意义(如果不那么有吸引力)的词云
2. n-grams模型
DataSciencester 负责搜索引擎营销的副总突发奇想,要创建数以千计的数据科学方面的Web 页面,以便人们在搜索与数据科学有关的词语时,我们的网站能够在搜索结果中的排名更加靠前。(你试图向他解释,由于搜索引擎的算法已经足够聪明了,所以这种做法很难奏效,但是他根本就不听这一套。)
当然,他既不想亲自编写数以千计的网页,也不打算雇用一批“水军”来做这件事情。相反,他向你咨询是否可以通过编程方式来生成这些网页。为此,我们需要寻找某种方法来对语言进行建模。
这种方法当然是有的,比如首先搜集一批文档,然后利用统计方法得到一个语言模型。在我们的例子中,我们将从 Mike Loukides 的文章“什么是数据科学?”着手。
就像在第 9 章中所做的那样,我们将使用一些 Web 请求命令(requests)和BeautifulSoup来检索数据。不过,这里有几个问题需要引起我们的注意。
第一个问题是,文本中的单引号实际上就是 Unicode 字符 u"\u2019"。我们可以创建一个辅助函数,用正常的单引号来取代它们:

第二个问题是,在获得了网页的文本之后,我们需要把它做成一个由单词和句号组成的序列(这样我们就可以知道句子的结尾在哪里)。为此,我们可以借助于 re.findall() 函数来完成:


当然,我们可以(也应该)进一步清理这些数据。文档中依然存在一些多余的文字(例如,第一个字“Section”就多余),同时,我们是利用句点来断句的(例如,遇到“Web2.0”就会出问题)。此外,文档中还散布了一些标题和列表。尽管如此,这个文档已经可以凑合着用了。
那么起始单词呢?实际上,我们只要从句点后面的单词中随机选择就行了。首先,让我们预先计算出可能的单词语次转变。回想一下,对于 zip 来说,只要输入中有一个已经处理完毕,它就会停下来,因此,我们可以利用 zip(document, document[1:]) 求出文档中有多少对连续元素:

现在,我们已经准备好生成句子了:

它产生的那些句子都是些无意义的数据,不过你可以把这些句子放到网站上,以让网站看起来更能与数据科学挂钩。举例来说:

如果我们使用三元模型(trigrams)的话,就能够降低这些句子无意义的程度。所谓三元模型,就是使用三个连续的词得到的模型。(更一般地讲,你还可以考虑由 n 个连续的单词得到的 n-grams 模型,不过对于我们来说,由三个词组成的就足够了。)
现在,这种语次转变将取决于前两个单词:

需要注意的是,现在我们必须将这些起始词单独记录下来。我们可以使用几乎相同的方法来生成句子:

这就可以产生更好的句子,比如:

当然,它们之所以看起来更好一些,是因为生成过程的每一步中,所面临的选择要更少一些,甚至有时候只有一种选择。这就意味着生成的句子(或至少是长短语)经常跟原始数据中的一字不差。更多的数据会有所帮助;此外,如果从多篇数据科学方面的文章中收集n-grams,收到的成效会更好。
3. 语法
还有一种语言建模方法,那就是利用语法规则(grammar)来生成符合要求的句子。在小学的时候,我们就已经知道了词的词类及其组合方式。例如,如果你有一个非常糟糕的英语老师,你必定会认为句子都是由名词后面跟动词构成的。这样的话,如果给你一个由名词和动词组成的列表,你就可以根据这种规则来造句了。
下面,我们将定义一个稍微复杂的语法:

我们约定,以下划线开头的名称表示语法规则,它们需要进一步展开;而其他名称是不需要进一步处理的终端符号。
例如,"_S" 是“句子”规则,其产生一个 "_NP"(“名词短语”)规则,后面紧跟一个 "_VP"(“动词短语”)规则。
动词短语规则可能会产生一个 "_V"(“动词”)规则,也可能会产生一个动词规则继之以名词短语规则。
请注意,"_NP" 规则所生成的规则中也包括其自身。我们知道,语法是可以递归的,因此,尽管这里这些语法非常有限,但是照样能够产生无穷多不同的句子。
那么,我们如何通过这些语法来生成句子呢?我们不妨从一个包含句子规则的列表 ["_S"]着手。然后,我们将不断展开每一项规则,即从该规则的产物中随机选择一个来代替它。当我们的列表元素全部变成终端符号时,我们就可以停下来了。
例如,这样的进展可能如下:

我们该如何实现这个目标呢?首先,我们将创建一个简单的辅助函数来识别终端:

接下来,我们需要编写一个函数,将一个标记列表变成一个句子。首先,我们需要找到第一个非终结符号标记。如果我们找不到这种标记,那就意味着我们已经有一个完整的句子,可以收工了。
如果我们真的找到了一个非终端符号,那么就在其中随机选择一个。如果选中的是个终端符号(即一个单词),那么直接用它替换相应的标记即可。除此之外,如果选中的是一个由空格符分隔的非终端符标记,那么则需要进行拆分,并将其拼接到当前标记中。总之,我们的工作就是在一组新标记上不断重复这个过程。
把这些放在一起,我们得到:

上述过程可以通过下列代码实现:

只要我们不断改变语法——例如添加更多的单词、添加更多的规则、添加各种词类等——就能得到足够多的网页来满足公司的需要。
实际上,当语法用于另一个方向时,会变得更加有趣。给定一个句子,我们就可以用语法来解析句子。这就能帮助我们识别主语和动词,从而理解句子的含义。
使用数据科学生成文本是一个巧妙的技巧;使用它来理解文本更神奇。(有关可为此使用的库,请参见“有关进一步探索”。)
4. 题外话:吉布斯采样
根据一些概率分布来生成样本是非常简单的事情。我们可以通过以下这行代码得到一些均匀分布的随机变量:

和正态随机变量,包括:

但某些概率分布却很难进行采样。当我们只知道一些条件分布时,可以通过吉布斯采样技术根据多维分布来生成样本。
例如,假设我们在掷两只骰子。这里用 x 表示第一骰子的点数,y 表示两个骰子的点数之和。假设我们要产生大量形如 (x, y) 的数据对,这种情况下,我们可以直接通过下列代码来轻松生成所需样本:


但是,这里假设你只知道条件分布。在已知道 x 的条件下求 y 的分布是很容易的:如果你知道了 x 的值,那么 y 就有同等机会等于 x+1,x+2,x+3,x+ 4,x+5,x+6:

如果将已知条件反过来,事情会变得更加复杂。举例来说,如果你知道 y 为 2,那么 x 必定为 1(因为只有当两个骰子的点数都为 1 的时候,点数之和才可能为 2)。如果你知道 y为 3,那么 x 有等同的机会为 1 或 2。类似地,如果 y 为 11,那么 x 要么为 5,要么为 6:

吉布斯抽样的方法是先从任意(有效)的 x 和 y 值入手,然后不断用 y 条件下随机选择的 x 值替换原来的 x,并用 x 条件下随机选择的 y 值替换原来的 y。
重复一定次数后,得到的x 值和 y 值就可以作为根据无条件的联合分布获取的样本了:

通过下列代码你会发现,这种取样方法与直接取样的效果相似:

我们将在接下来的部分使用这种取样方法。
5. 主题建模
在第 1 章我们建立“你应该知道的数据科学家”推荐系统的时候,我们只是根据科学家与读者的兴趣是否严格匹配来进行推荐的。
要想理解我们的用户,更高级的方法是识别这些兴趣背后的相关主题。有一种叫作隐含狄利克雷分析(latent dirichlet analysis,LDA)的技术,常用来确定一组文档的共同主题。我们会用它来分析包含每个用户的兴趣的那些文档。
这里的 LDA 与第 13 章中的朴素贝叶斯分类器有一些相似之处,它们都是用于处理文档的概率模型。我们将尽量避开一些数学细节问题,但对于该模型的某些假设却不得不说,如下所述。
• 存在固定数目的主题,即 K 个。
• 有一个给每个主题在单词上的概率分布赋值的随机变量。你可以把这个分布看作是单词w 在给定主题 k 中出现的概率。
• 还有另一个随机变量来指出每个文档在主题下面的概率分布。你可以将这个分布看作是文档 d 中各主题所占比重。
• 文档中各个单词的生成方式为,首先(根据文档的主题分布情况)随机选择一个主题,然后(根据该主题下面各单词的分布情况)随机选择一个单词。
特别地,我们要建立一个文档(documents)集合,其中每个文档都是一个单词的列表。同时,我们还要建立一个相应的 document_topics 集合,以便给每个文档中的每个单词都指定一个主题(这里用 0 到 K–1 之间的一个数字表示)。
这样的话,第 4 个文档中的第 5 个单词就可以表示为:

而这个选定的单词对应的主题可以表示为:

这非常显式地定义了每个文档在各个主题上的分布情况,同时也隐式地定义了每个主题在各个单词上面的分布情况。
我们可以估算出主题 1 产生一个特定单词的可能性,方法是将主题 1 产生该单词的次数除以主题 1 产生任意单词的次数。(类似地,我们在第 13 章中建立垃圾邮件过滤器时,也曾经用每个单词出现在垃圾邮件中的次数与这些单词出现在垃圾邮件中的总次数进行过相应的比较。)
这些主题都只是些数字,不过,我们可以用其权重最大的单词给它们取一个描述性的名称。接下来,我们只需设法生成 document_topics 即可。这时,吉布斯取样技术就派上用场了。
首先,我们以完全随机的方式给所有文档中的每个单词都赋予一个主题。现在,我们就以每次一个单词的方式遍历所有文档。对于给定的单词和文档,我们需要根据该文档中主题(当前)的分布情况以及相对于该主题各单词(当前)的分布情况来建立相应的权重。然后,我们会使用这些权重给这个单词选取新主题。如果将该过程迭代多次,我们就能利用主题—单词分布和文档—主题分布完成联合取样。
首先,我们需要一个函数来根据任意权重集随机选择一个索引:


例如,如果你给它的权重为[1,1,3],那么五分之一的时间它将返回0,五分之一的时间它将返回1,五分之三的时间它将返回2。让我们来编写一个测试吧:

我们的文档是我们用户的兴趣,具体如下:


我们将尝试找到:

个主题。为了计算采样权重,我们需要跟踪多个计数。让我们首先为它们创建数据结构。
•我们要统计每个文档中每个主题出现的次数,代码如下:

•我们要统计每个主题中每个单词出现的次数,代码如下:

•我们要知道每个主题中单词的总数,代码如下:

•每个文档中所包含的单词总数:

•不同单词的数量:

•另外,下列代码可以用来统计文档的数量:

一旦掌握了这些数据,我们就可以了解(比如说)documents[3] 中与主题 1 相关的单词的数量,具体代码如下所示:
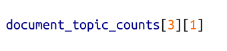
同时,我们还可以找出与主题 2 相关的单词 nlp 出现的次数,具体代码如下所示:

现在,我们已经为定义条件概率函数做好了准备。就像在第 13 章中那样,这里的每个主题和单词都需要有一个平滑项,来确保每个主题在任何文档中被选中的几率都不能为 0,同时保证每个单词在任何主题中被选中的几率也都不能为 0:


我们将使用这些方法来创建用来更新主题的权重:

上面的 topic_weight 之所以如此定义,背后是有坚实的数学理论作为依据的,不过其中的数学细节已经超出了本书的讨论范围。不过从直观的角度来看,如果已知一个单词和所在文档,那么该单词属于某主题的概率取决于两个方面,即该主题属于该文档的可能性以及该单词属于该主题的可能性。
这就是我们所需要的全部零部件。下面,我们开始将每个单词随机指派给一个话题,并计入相应的计数器:

我们的目标是获得一个主题的联合样本-单词分发和文档-主题分发。我们使用一种使用条件概率的吉布斯采样形式,它使用了前面定义的条件概率:

这些主题都是什么呢?它们只是些数字而已:0、1、2 和 3。如果我们要让它们拥有名称的话,必须亲自给它们取名。下面,让我们来找出权重较大的 5 个单词(见表 21-1),具体代码如下所示:

表21-1。每个主题中最常见的单词
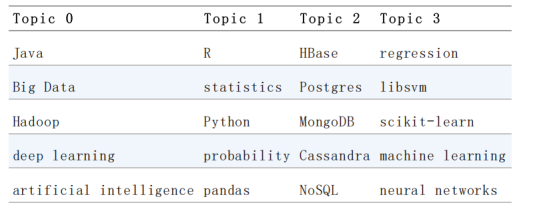
根据这些数据,我们就可以给主题取名了:

至此我们就清楚模型是如何将主题分配到每个用户的兴趣上面了:
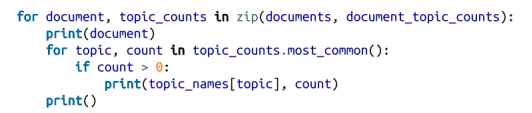
其中提供:

以此类推。鉴于一些主题名称中需要的“领域”,我们可能应该使用更多的主题,尽管很可能我们没有足够的数据来成功地学习它们。
6. Word 向量
NLP方面的许多最新进展都涉及到深度学习。在本章的其余部分,我们将使用第19章形成的机制。
一个重要的创新包括将单词表示为低维向量。这些向量可以被比较,加在一起,输入到机器学习模型中,或者任何你想用它们做的任何事情。它们通常具有良好的属性;例如,类似的词往往有相似的向量。也就是说,big的词向量非常接近large的词向量,所以在词向量上操作的模型可以(在某种程度上)免费处理像同义词这样的东西。
这些向量通常也会表现出令人愉快的算术性质。例如,在一些这样的模型中,如果你取了国王的向量,减去男人的向量,然后加上女人的向量,你最终会得到一个非常接近女王的向量的向量。思考这对向量实际上“学习”的含义是很有趣的,尽管我们不会在这里花时间。
想出大量词汇的这样的向量是一项困难的任务,所以我们通常会从文本语料库中学习它们。有几种不同的方案,但在高级级别上,任务通常是这样的:
1. 获取一堆文字。
2. 创建一个数据集,其目标是预测一个给定附近单词的单词(或者,预测给定一个单词的附近单词)。
3. 训练一个神经网络来完成这项任务。
4. 以训练过的神经网络的内部状态作为单词向量。
特别是,由于任务是预测一个给出附近单词的单词,发生在相似上下文中(因此有相似的附近单词)的单词应该具有相似的内部状态,因此具有相似的单词向量。
这里我们将使用余弦相似度来度量“相似度”,它是-1和1之间的一个数字,用来测量两个向量指向相同方向的程度:

让我们学习一些单词向量,看看这是如何工作的。
首先,我们需要一个玩具数据集。常用的单词向量通常是从数百万甚至数十亿单词的训练中得到的。由于我们的玩具库无法处理这么多的数据,我们将创建一个具有一定结构的人工数据集:

这将产生很多结构相似但单词不同的句子;例如,“绿色的船似乎很慢”。鉴于这种设置,颜色将主要出现在“类似的”的上下文中,名词也会出现,等等。所以如果我们能很好地分配单词向量,颜色应该得到类似的向量,等等。
注意
在实际使用中,你可能会有数百万个句子的语料库,在这种情况下,你会从句子中得到“足够”的上下文。在这里,只有50句话,我们必须让它们有些人工化。
如前所述,我们希望对我们的单词进行一次热编码,这意味着我们需要将它们转换为ID。我们将介绍一个词汇类来跟踪此映射:


这些都是我们可以手动做的事情,但是在课堂上使用它很不方便。我们应该测试一下:


我们还应该编写简单的辅助函数来保存和加载一个词汇表,就像我们的深度学习模型一样:

我们将使用一个叫做跳过图的单词向量模型,该模型以一个单词作为输入,并生成在它附近可能看到的单词的概率。我们将给它训练对(单词,nearby_word),并尽量减少最小最大熵损失。
注意
另一个常见的模型,连续的单词包(CBOW),以附近的单词作为输入,并试图预测原始单词。
让我们来设计我们的神经网络。它的核心将是一个嵌入层,它以一个词ID作为输入,并返回一个词向量。在已知条件下,我们可以只为此使用一个查找表。
然后,我们将将单词向量传递给线性层,其输出数量与词汇表中的单词相同。与以前一样,我们将使用softmax将这些输出转换为附近单词上的概率。当我们使用梯度下降来训练模型时,我们将更新查找表中的向量。完成训练后,该查找表就会提供单词向量。
让我们来创建那个嵌入层。在实践中,我们可能希望嵌入单词以外的东西,因此我们将构建一个更通用的嵌入层。(稍后我们将编写一个专门为词向量编写的TextEmbedding子类。)
在其构造函数中,我们将提供嵌入向量的数量和维数,以便它可以创建嵌入(最初是标准随机法):

在我们的例子中,我们一次只嵌入一个单词。然而,在其他模型中,我们可能想要嵌入一系列单词,并得到一系列单词向量。(例如,如果我们想训练前面描述的CBOW模型。)所以,另一种设计将采用单词ID序列。我们将坚持一次做一个,让事情更简单。

对于向后传递,我们将得到一个与所选嵌入向量对应的梯度,我们需要为self.embeddings构造相应的梯度,除了所选嵌入之外,每个嵌入都为零:

因为我们有参数和梯度,所以我们需要覆盖这些方法:

如前所述,我们将需要一个专门用于词向量的子类。在这种情况下,我们的嵌入数量由我们的词汇量决定,所以我们将其传递入:

其他内置方法将正常工作,但我们将添加一些比较适用于文本处理的方法。例如,我们希望能够检索一个给定单词的向量。(这不是Layer界面的一部分,但我们总是可以自由地向特定的Layer添加额外的方法。)

这个数据下的方法将允许我们检索使用索引的字向量:

我们还希望嵌入层能告诉我们最接近给定单词的单词:


我们的嵌入层只是输出向量,我们可以将其输入到一个线性层中。
现在,我们已经准备好收集培训数据了。对于每个输入词,我们将选择它左边的两个单词和它右边的两个单词作为目标词。
让我们先将句子转为小写形式,并将其分割成单词:

此时,我们可以构建一个词汇表:


使用我们建立的机制,现在很容易创建我们的模型:

使用第19章中的技术,可以轻松训练我们的模型:


当你看这列火车时,你可以看到颜色越来越接近,形容词越来越接近,名词越来越接近。
训练模型后,探索最相似的词语会非常有趣:

哪个结果(对我来说)会导致:

(很明显,床和猫并不是很相似,但在我们的训练句子中,它们看起来是,这就是模型捕捉到的。)
我们还可以提取前两个主要组件并绘制它们:

这表明类似的词语确实聚集在一起(图21-3):

图21-3 Word向量
如果你感兴趣,那么训练CBOW词向量并不难。你得做一点工作。首先,你需要修改嵌入层,以便使用ID列表并输出嵌入向量列表作为输入。然后,你必须创建一个新的Layer(总和?)它取一个向量列表,并返回它们的和。
每个单词都表示一个训练示例,其中输入是周围单词的单词Id,目标是单词本身的独热编码。
修改后的嵌入层将周围的单词转换为向量列表,新的Sum层将向量列表分解为单个向量,线性层可以生成分数,然后可以softmax以得到一个概率分布,这个分布表示“鉴于此上下文最有可能的单词”概率。
我发现CBOW模型比skip-gram模型更难训练,但我鼓励你尝试一下。
7. 递归神经网络
我们在前一节中开发的单词向量通常被用作神经网络的输入。这样做的一个挑战是句子的长度不同:你可以认为3个单词的句子为[3,embedding_dim]张量,10个字的句子为[10,embedding_dim]张量。为了将它们传递到一个线性层,我们需要对第一个变长维数做一些事情。
一种选择是使用Sum层(或取平均值的变体);然而,句子中单词的顺序通常对其意义很重要。举个例子,“狗咬人”和“人咬狗”是两个非常不同的故事!
另一种处理这一问题的方法是使用递归神经网络(RNNs),它在输入之间保持一个隐藏状态。在最简单的情况下,每个输入与当前隐藏状态组合以产生输出,然后将输出用作新的隐藏状态。这使得这些网络能够“记住”(在某种意义上)他们所看到的输入,并建立一个取决于所有输入及其顺序的最终输出。
我们将创建几乎最简单的RNN层,它将接受单个输入(例如,句子中的一个单词或单词中的一个字符),并在调用之间保持隐藏状态。
回想一下,我们的线性层有一个权重w,和一个偏差b。它接受了一个向量输入,并使用下面的逻辑产生了一个不同的向量作为输出:
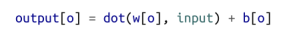
这里我们希望合并隐藏状态,因此我们将有两组权重—一组应用于输入,另一组应用于以前的隐藏状态:
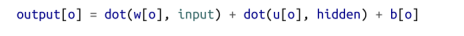
接下来,我们将使用输出向量作为隐藏值的新值。这并不是一个巨大的变化,但它将让我们的网络更好。

你可以看到,我们将隐藏状态作为全0的向量开始,我们提供了一个函数,使用网络的人可以调用来重置隐藏状态。
考虑到此设置,forword函数就相当简单(至少,如果你能记住并理解我们的线性层是如何工作的):


向后传递与我们的线性层中的一个相似,除了它需要计算一组额外的梯度:

最后,我们需要重载params和grads的方法:

注意
这个“简单”的RNN非常简单,因此你可能不应该在实践中使用它。
我们的SimpleRnn有一些不受欢迎的特性。一种是它的整个隐藏状态用于在每次调用输入时更新输入。另一种情况是,每次调用整个隐藏状态时都会被覆盖。这两种方法都使训练变得困难;特别是,它们使模型难以学习远程依赖关系。
由于这个原因,几乎没有人使用这种简单的RNN。相反,它们使用更复杂的变体,如LSTM(“长短期记忆”)或GRU(“门控单元”),它们具有更多的参数和用参数化的“门”,只允许每次更新一些状态(而某些状态被使用)。
这些变体并没有什么特别困难的;然而,它们涉及更多的代码,(在我看来)不会相应地更有启发意义。本章关于GitHub的代码包括一个LSTM实现。我鼓励你去看看,但这有点乏味,所以我们不会在这里进一步讨论。
我们实现的另一个奇怪之处是,它一次只需要“一步”,需要我们手动重置隐藏状态。一个更实际的RNN实现可以接受输入序列,在每个序列开始时将其隐藏状态设置为0s,并产生输出序列。我们的代码当然可以这样修改;同样,这将需要更多的代码和复杂性,而不会带来更深入的理解。
8. 示例:使用一个字符级的RNN
新聘请的品牌副总裁自己并没有想到达塔西安斯特这个名字,(因此)他怀疑一个更好的名字可能会给公司带来更多的成功。他要求你使用数据科学来提供被替代的候选建议。
RNNs的一个“很酷的”应用程序包括使用字符(而不是单词)作为输入,训练他们学习某些数据集中微妙的语言模式,然后使用它们从该数据集中生成虚构的实例。
例如,你可以训练一个RNN关于另类乐队的名字,使用训练过的模型为假的另类乐队生成新的名字,然后手工选择最有趣的乐队,并在推特上分享它们。真是太棒了!
看到这个技巧很多次后,你不再认为它非常聪明,你决定试试。
经过一番挖掘,你会发现启动加速器Y Combinator发布了其前100家(实际上是101家)最成功的初创公司的列表,这似乎是一个很好的起点。检查页面,你会发现公司的名称都生活在<b类=“h4“>标签中,这意味着很容易使用你的网络抓取技能来检索它们:

和往常一样,页面可能会更改(或消失),在这种情况下,此代码将无法工作。如果是这样,你可以使用新学习的数据科学技能来修复它,或者只是从书的GitHub网站获取列表。
那么,我们的计划是什么呢?我们将训练一个模型来预测名称的下一个字符,并给定当前字符和表示我们迄今为止看到的所有字符的隐藏状态。
与往常一样,我们将实际预测字符上的概率分布,并训练模型以最小化SoftmaxCrossEntropy损失。
一旦我们的模型被训练,我们可以使用它来生成一些概率,根据这些概率随机采样一个字符,然后将该字符作为下一个输入。这将允许我们使用学习到的权重来生成公司名称。
首先,我们应该根据名称中的字符构建一个词汇:

此外,我们将使用特殊令牌来表示公司名称的开始和结束。这允许模型了解哪些字符应该开始一个公司名称,也可以了解一个公司名称何时完成。
我们只使用正则表达式字符开始和结束,(幸运的是)它们不会出现在我们的公司列表中:

对于我们的模型,我们将对每个字符进行一次独热编码,通过两个SimpleRnns,然后使用线性层为每个可能的下一个字符生成分数:
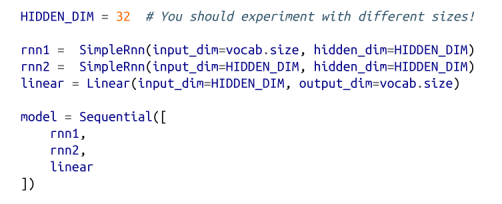
想象一下,目前我们已经训练了这个模型。让我们使用“主题建模”中的sample_from函数,编写使用它生成新公司名称的函数:


最后,我们已经准备好训练我们的角色级的RNN了。这将需要一段时间!


训练后,模型从列表中生成一些实际名称(这并不奇怪,因为模型具有相当多的容量而没有大量的训练数据),以及一些与训练名称(脚本、链接、诗歌)类似看起来真正有创意的名称(Benuus, Cletpo, Equite, Vivest),以及垃圾但仍然类似单词的名称(SFitreasy, Sint ocanelp, GliyOx, Doorboronelhav)。
不幸的是,就像大多数角色级的RNN输出一样,这些输出只是有点聪明,而品牌的副总裁最终无法使用它们。
如果我将隐藏的维度提升到64,我就会从列表中逐字得到更多的名字;如果我把它放到8,我得到的大多是垃圾。所有这些模型大小的词汇表和最终权重可以在该书的GitHub网站上找到,你可以自己使用load_weights和load_vocab来使用它们。
如前所述,本章的GitHub代码还包含一个LSTM实现,你可以作为公司名称模型中SimpleRnns的替换品。
9. 以供进一步探索
• NLTK是Python的一个流行的NLP工具库。它有自己的整本书,可以在网上阅读。
• gensim是一个用于主题建模的Python库,它比我们的从头开始的模型更好。
• spaCy是“Python中的工业强度的自然语言处理”的库,也很受欢迎。
• 安德烈·卡帕蒂有一篇著名的博客文章,“递归神经网络的不合理有效性”,非常值得一读。
• 我的日常工作包括建立AllenNLP,一个用于做NLP研究的Python库。(至少,在这本书出版的时候,它确实是这样的。)该库完全超出了这本书的范围,但你可能仍然会发现它很有趣,而且它有一个很酷的交互式演示界面,可以演示许多最先进的NLP模型。
