
基于可微存储的时空视频自编码器

SPATIO-TEMPORAL VIDEO AUTOENCODER WITH DIFFERENTIABLE MEMORY


Abstract:本文提出了一个新型的视频时空自编码器,包括一个空间上的图像自编码器和一个内嵌的时域自编码器。时域的编码器是一个由Conv-LSTM单元组成的可微的视觉存储器,其集成了视频在时间上的变化。本文的目标在于通过一个具有强撸版性的时域解码器来捕捉视频中的运动变化,其由光流预测模块和图像采样器组成作为内置的反馈循环。在每个时间步上,系统接收一个视频帧作为输入,通过当前的观察以及LSTM存储单元的信息预测得到代表稠密变化信息的光流图,随后基于预测的光流和当前帧来生成下一帧,通过最小化预测帧以及对应的ground truth之间的重构误差来无监督地训练整个系统,提取出有利于动作估计的特征。最后本文给出了模型的一个直接应用,那就是利用光流信息实现标签的传播以对视频进行弱监督的语义分割。
1 Introduction&Inspiration
本文的主要灵感来源于视频的编码和压缩方法,我们知道存储一个视频的时候没有必要存储整个视频序列的每一帧图像,而只需存储帧间的主要差异信息以便于能够通过给予之前的帧重建出整个视频即可 。基于以上考虑本文采用了经典的卷积图像编解码器,同时在其中内嵌了conv-LSTM存储单元做为时域上的编码器,而时域上的解码器则采用了光流预测模块结合图像采样器,用于及时反馈预测得到的光流图。
2 Model Architecture
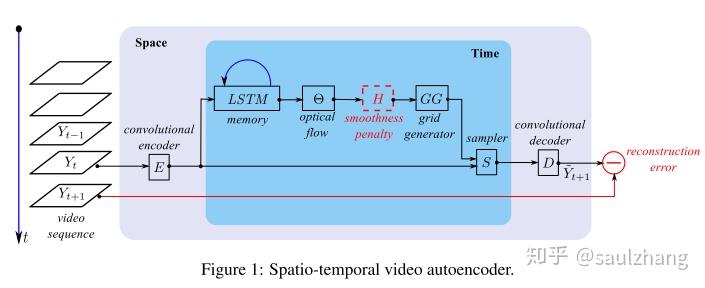

本文提出的模型的主要结构包括一个空间上的自编码器其中还内嵌了一个时间上的自编码器。
2.1 空间自编码器E和D
E是一个传统的CNN,包括cnov、tanh以及pooling层,D则与E的结构相对称,其反卷积采用的是基于最近邻的空间上采样的方法。其变换过程可以简述为 Y_t\stackrel{E}{\longrightarrow}x_t\stackrel{D}{\longrightarrow}\hat{Y}_{t+1} ,其中 x_t 的尺寸为 d\times h\times w ,d为特征的数量。
2.2 时间自编码器
2.2.1 LSTM Memory Module
LSTM模块是整个架构的核心,其扮演着时间编码器的角色。其目标是构建一个短期的视觉记忆(VSTM),以保留布局和位置的相关信息,确保快速的访问。当整个网络的输入为 x_t 时,LSTM单元的公式可以表示为:
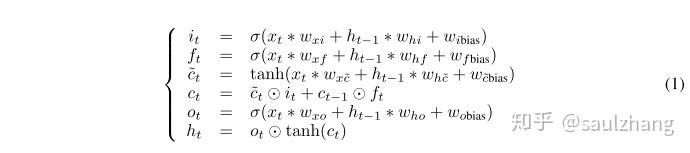

该模块的输入的特征维度为 d\times h\times w 输出的特征维度为 d_m\times h\times w ,其中 d_m 是时域编码器学习到的时域特征的数量,循环连接只作用在时间维度上。
2.2.2 光流预测 \theta 以及Huber惩罚 H
光流预测模块通过对光流进行预测得到光流图 \tau ,其与memory的输出具有相同的高和宽(深度为2,代表每个像素在x和y方向上的位移)。利用光流图 \tau的信息便可以将之前的帧图像通过弯曲等变换得到下一帧。本文的光流预测模块主要包括两个卷积层且具有较大的卷积核(15×15),用于将memory的输出映射到流向量的特征空间。为了确保局部的平滑性,本文还对光流图的局部的梯度 \nabla\tau 进行惩罚,通过该惩罚可以对 H 之前的模块进行调整。此处采用的Huber损失,公式如下:
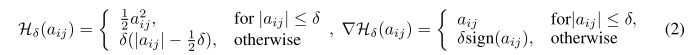

其中 a_{ij} 表示 \nabla \tau中的元素,\delta = 10^{-3} 。
2.2.3 网格生成器 GG 以及图像采样器 S
网格生成器GG以及图像采样器S利用 \Theta 预测得到的光流信息对当前帧对应的特征图 x_t 进行变形预测得到的下一帧的特征图 \tilde{x}_{t+1} 。本文采用了和STN中相似的网格生成器和采样器,但不同的是,本文没有直接对图像进行仿射变换,而是直接通过预测的光流图决定输出 \tilde{x}_{t+1} 中 (x_o,y_o) 处应该用输入的特征图 \tilde{x}_t (d×h×w)中 (x_s,y_s)位置上尺寸为 d \times 1 \times 1 的特征来填充。
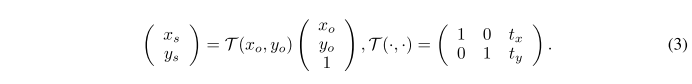

\theta 对于每个像素的位置都会输出两个预测参数 (t_x,t_y) 表示 位置(x,y) 在x和y两个方向上的位移量。对于网格生成器 GG 的前向传播过程则可以采用公式(3)进行表示(注意,这里是一个Output→Source的映射,个人理解是Source和Output之间不一定是双射的关系,所以为了保证输出是完整的,那么只需要针对Output的每个位置去Source总找一个Pixel来填充便可填满整个Output的feature map)。
2.3 损失函数
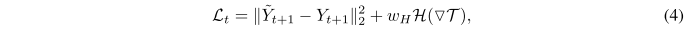

损失函数包括重构误差和Huber乘法两项。 w_H 用于调整Huber惩罚项的权重,本文实验中设置为 10^{-2} 。
2.4 网络参数
本文的模型中一共包含1,035,067个可训练的参数。其中空间自编码器中有16个 7 \times 7 卷积层,存储器LSTM模块由64个 7 \times 7 的卷积核,光流回归器 \theta 有2个 15 \times 15 的卷积层和一个 1× 1 的卷积层。
3 训练
首先为了实验网格生成器 GG 和图像采样器 S 预测得到的光流的效果,本文先屏蔽其他模块只对该模块进行独立实验,即直接采用Sintel数据集的图像作为输出,预测得到该图像序列上的光流信息对原图像进行变换以得到下一帧。以下为实验结果,光流图采用下图中右上角的颜色编码方式进行表示(颜色代表移动方向,亮度代表速度的大小)。实验中平均每个像素点的预测误差值为0.004(像素值归一化到[0,1])。图中看到预测的下一帧出现了一些伪影,主要原因是该数据集上面光流的位移变化较大,但作者相信通过引入空间自编码器可以在高维的空间上缓解该问题。


3.1 无监督实验
为了定性和定量地评估本文的模型,作者在合成的以及真实的数据集上面进行了实验。
合成数据集
该部分采用Moving MNIST数据集进行实验,10K个训练作为训练集,3K的序列作为验证集,下图3展示了部分数据样本。


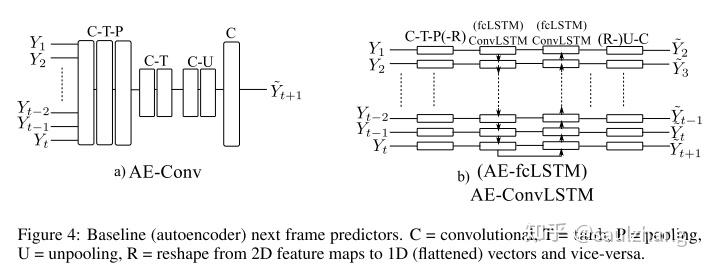
为了对模型中的不同模块进行充分地对比,本文采用了几个不同的模型进行对比(图4)。

以下表1中展示了各种不同模型的参数规模以及在逐像素的平均测试误差。
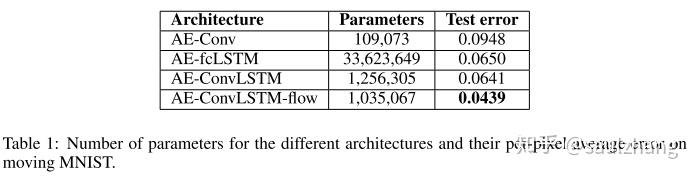

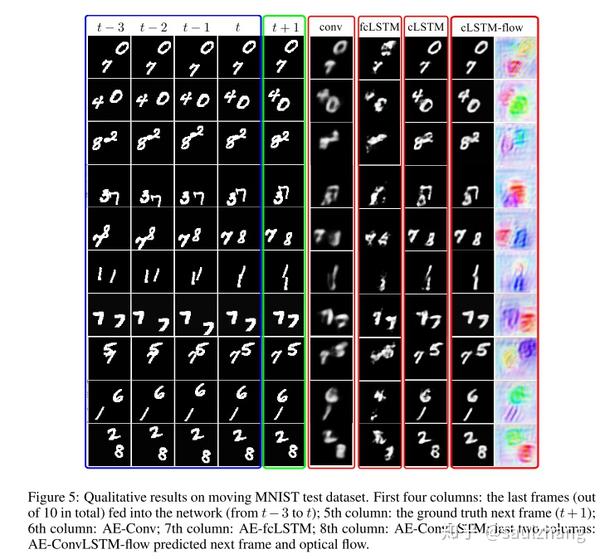
图5中展示了部分的定性分析的结果。所有采用了LSTM模块的网络均取得了较好的实验效果,其表明了利用帧间时域依赖信息的重要性。

真实数据集
该部分实验中训练集采用HMDB-51数据集,测试集采用PROST和ViSOR数据集。图6展示了部分测试集上的定性分析结果。图中表明网络可以正确地区分图片中移动的元素以及背景信息。然而预测的光流准确率仍然与基于监督学习的光流估计方法具有较大的差距(这也很好理解,传统的光流估计方法是一致两帧图片,估计两帧之间的光流,而本文的方法是一致一个序列预测最后一帧到其后一帧的光流)。


3.2 无监督视频语义分割中的应用
...
4 总结与未来工作
作者提到未来的一个重要工作就是将存储模块与注意力机制和长期存储模块的形式集成在一起,以实现完整的存储系统。最后本文提出的LSTM存储器模块以及内置的循环反馈单元拥有运用到视频压缩算法中的潜力。
