
VDSimilar: 基于代码相似性的漏洞检测


Paper
VDSimilar: Vulnerability detection based on code similarity of vulnerabilities and patches,Hao Sun, Lei Cui,C&S(B)。
Abstract
现有的研究将漏洞检测视为一个分类问题,在捕获语义和语法相似性的同时需要大量的标记数据。本研究认为漏洞的相似性是漏洞检测的关键,本文准备了一个由漏洞和相关补丁组成的相对较小的数据集,并尝试比较漏洞之间的相似性、漏洞补丁之间的差异性来实现漏洞检测。为此,使用Siamese网络+BiLSTM+Attention作为检测模型。在OpenSSL和Linux的876个漏洞和补丁的数据集上,提出了模型VDSimilar,在OpenSSL的AUC值上达到了约97.17%,优于目前基于深度学习的漏洞检测SOTA方法。
Introduction
现有的基于代码相似性的漏洞检测方法普遍是基于代码段语法和语义的相似性来进行的,但是两份语法语义相似的代码很可能因为一丁点差别而一个有漏洞一个没有漏洞,因此,本文希望找到一个能从漏洞角度捕获相似性的方法。另外,基于深度学习的方法总是需要大量的数据,比如VulDeepecker需要61638个code gadget,准备这样的数据集需要花费巨大的人力资源,本文希望找到一个可以在小数据集上使用的深度学习检测方法。
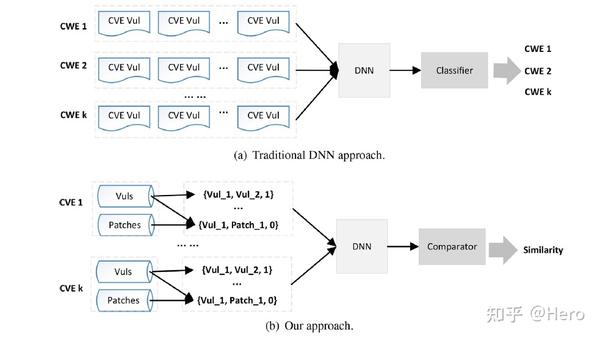

本文提出了一个基于度量学习的代码漏洞检测方法,学习了一个应用于漏洞和补丁数据集上的代码相似性检测器。首先,准备一个CVE brunch的数据集,每个CVE brunch包含与一个CVE相关的多个漏洞函数和补丁函数,如上图所示,这些CVE函数可以从不同版本的软件中获得,它们遵循两个规则:
- 对于同一个CVE中两个版本的漏洞函数,漏洞片段保持不变
- 对于一个漏洞函数和一个补丁函数,漏洞片段一定消失
因此,每个CVE brunch都可能提供一个CVE漏洞特征。其次,从漏洞的角度来看,不同版本的两个漏洞函数应该被视为相似的,即使版本迭代过程中存在代码更改;另一方面,由于补丁代码中漏洞片段已经消除,因此即使漏洞函数与补丁函数语法和语义相似,也应视为不同。本研究在本文提出的数据集上与之前的方法比较,证明了VDSimilar的有效性。
本文认为,相比整个漏洞函数,漏洞代码片段是漏洞检测的关键,如下图所示,显示了t1_lib.c 的 tls_decrypt_ticket函数的代码片段,该函数在OpenSSL的三个版本中演进。该功能被报告为一个漏洞(CVE-2014-3567),影响0.9.8zb和1.0.1i,然后在更高版本的1.0.1l中修复,下图中第二个函数应该是1.0.1i。
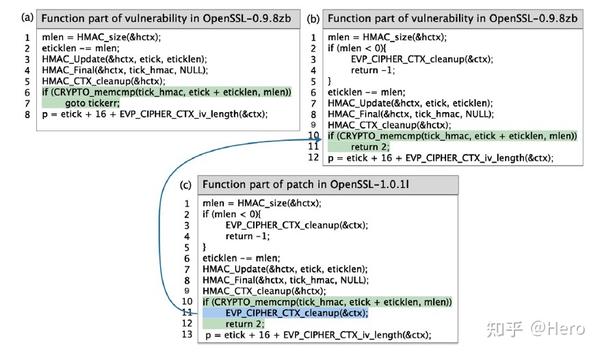

可见,相比第一版,第二版增加了4行,改变了一行,都是漏洞函数。第三版相比第二版只增加了一行,和第一版相比更接近于第二版,但第三版确是补丁函数。OpenSSL程序不断发展,其中一个函数可能会由于诸多原因修改,如修复bug、优化性能或重构代码。两个版本的相同函数在语法和语义上可能会有很大的差异,而对于需要修复的漏洞,补丁可能只涉及几行甚至一行代码,因此跨连续版本的漏洞函数和补丁函数在语法上是高度相似的。
因此,一种好的基于代码相似度的漏洞检测方法应该更多地关注漏洞片段的相似度,而不是整个函数的代码语法和语义的相似度。
Method
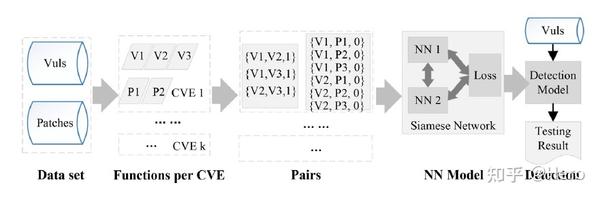

上图是VDSimilar的整体framework,数据集包含了很多的CVE漏洞,每个CVE漏洞由几个版本的漏洞函数和补丁函数组成。由于训练样本过少,本文采用度量学习的方式训练计算相似性的分类器,对于漏洞-漏洞函数对,标记为相似label为1,对于漏洞-补丁函数对,标记为不相似label为0,训练Siamese网络,训练过程中引入Attention,最终计算测试函数和漏洞库函数的相似性,相似性高于一定阈值被认为存在漏洞。
- 数据准备
为了准备数据集,本文从CVE Details数据库中收集了一组CVE,如下图所示,漏洞一般可以通过两种途径得到。一种是直接下载product,然后根据漏洞详细信息中描述的文件名和函数名提取漏洞函数;另一种是直接从外部链接中引用的补丁中提取漏洞;由于有些外部链接并不可用,因此本文采用第一种方式。
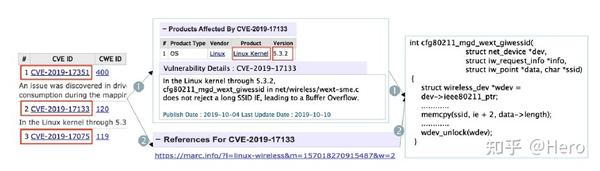

为了获得补丁,假设最新的有漏洞版本之后的Linux和OpenSSL版本漏洞已经修复,通过从多个版本的程序中提取漏洞和补丁函数,生成一组相似对({V, V, 1})和差异对({V, P, 0})。使用网络爬虫Scrapy框架爬取CVE Details中的程序版本、漏洞函数名、文件名和补丁等等信息,可以为每个CVE获取一个元组,即(CVE、软件、漏洞版本、补丁版本、文件名、函数名)。
对于每一个CVE,根据上文提取的详细信息,使用LLVM解析源代码,提取出一组漏洞函数和补丁函数。使用hash的方式去除重复函数、修正可能出现的漏洞标签错误信息。然后生成相似对和差异对,在该过程中扩大数据集,方便训练。
- 检测模型
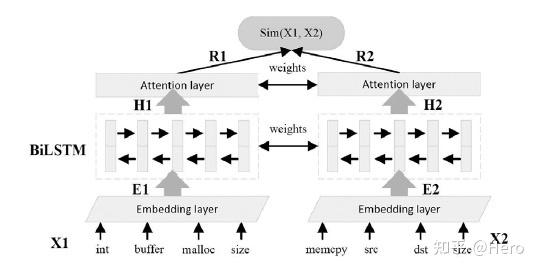
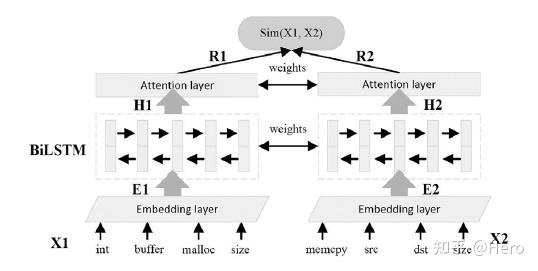
本文的检测模型Siamese架构如上图所示,首先进行embedding,然后输入BiLSTM中得到输出,经过一层Attention后计算相似度即可。值得一提的是该Attention是self-attention,类似transformer一样,由H成参数矩阵生成Q,K,V,然后进行Attention计算,该Attention过程的作用是将注意力聚集在漏洞代码片段而不是整个函数上。
Siamese网络是一个共享权重的孪生网络,模型训练过程中最大化漏洞函数之间的相似度,最小化漏洞函数和补丁函数的相似度。在测试过程中计算每个目标函数与已有漏洞函数的相似度,如果接近1则有漏洞,如果接近0则没有漏洞,算法伪代码如下。


Evaluation
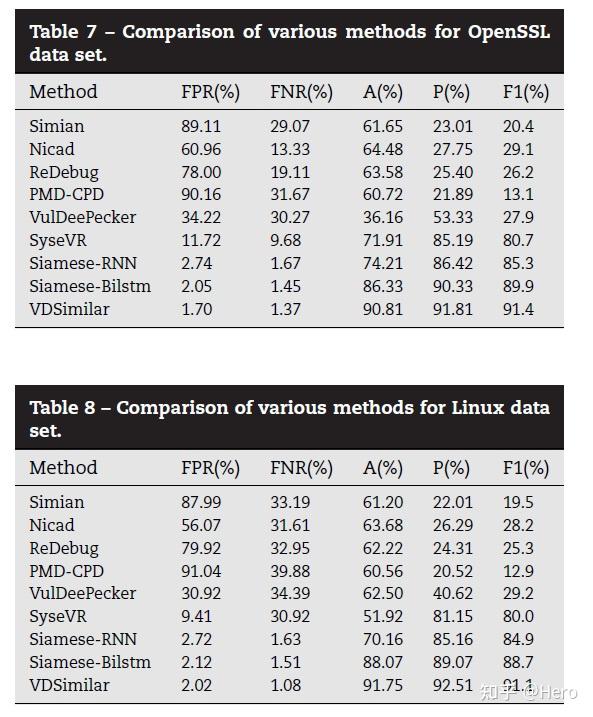
与Simian,Nicad,ReDeBug,PMD-CPD,SyseVR,VulDeePecker这几个方法做比较,本文的Siamese模型在Linux和OpenSSL数据集上取得了更高的检测准确率和F1值。

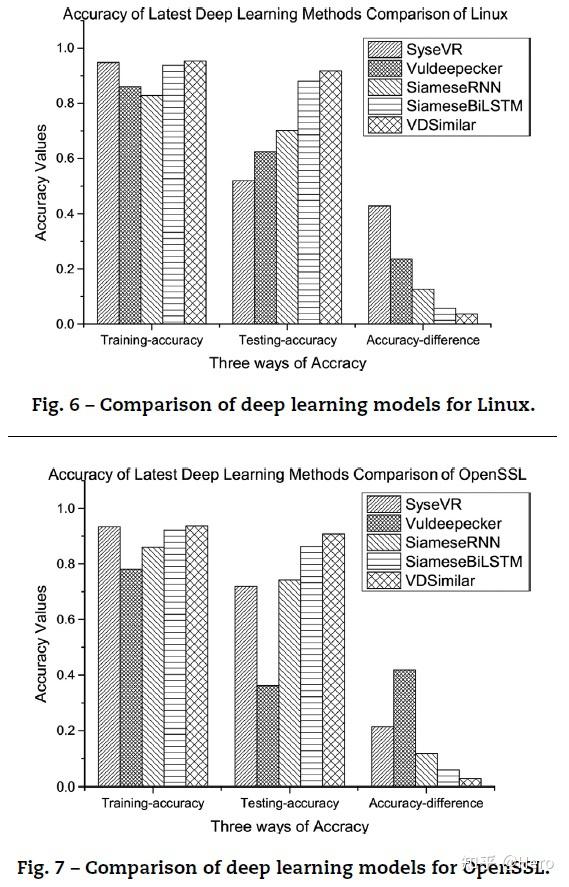
本文将VDSimilar和几个之前的深度学习模型做比较,发现Siamese+BiLSTM+Attention的VDSimilar模型具有最好的泛化性能。

Conclusion
本文提出了一个基于代码相似性的源代码漏洞检测方法,准备了一个由漏洞和相关补丁组成的相对较小的数据集,并尝试比较漏洞之间的相似性、漏洞补丁之间的差异性来实现漏洞检测。为此,使用Siamese网络+BiLSTM+Attention作为检测模型。在OpenSSL和Linux的876个漏洞和补丁的数据集上取得了良好的实验效果,证明了模型的有效性。
