
增强模型鲁棒性!博世提出元对抗训练方法

作者 | 孙裕道
编辑 | CV君
报道 | 我爱计算机视觉(微信id:aicvml)
介绍一篇对抗学习最新论文 Meta Adversarial Training ,作者来自德国博世公司。


引言
深度学习模型中一个很致命的弱点就是它容易遭到对抗样本攻击。在真实物理世界中,通用对抗样本可以低成本的对深度模型进行对抗攻击,这种对抗攻击可以在各种环境中欺骗模型。
到目前为止对抗训练是针对对抗攻击最有效的防御手段,但问题在于训练对抗模型是一件成本很高的事情,而且防御通用对抗样本难度会更大。
在该论文中作者提出了一种元对抗训练方式,它将对抗训练和元学习的结合在一起,不仅降低训练成本,而且大大提高了深度模型对通用对抗样本的鲁棒性。
背景介绍
通用对抗扰动于2017年的《Universal adversarial perturbations》中被首次提出。
通用对抗扰动与单一图片的对抗扰动有很大的区别。通用对抗扰动最大的一个特点就是该扰动与输入图片无关,它与模型本身和整个数据集相关;
而单一图片的对抗扰动只是针对于它的输入图片,对数据集其它的图片攻击性几乎没有。
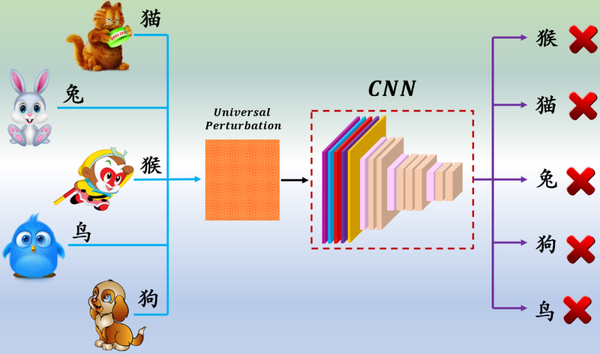

如上图所示,假如有一个动物数据集和经该数据集上训练得到神经网络分类器,经过对抗攻击生成了针对于该动物数据集和该模型的通用对抗扰动Universal perturbation。
将该对抗扰动加在选取出的猫,狗,兔子,猴子,鸟的图片,并输入到分类器中,分类器全部分类出错。
模型介绍
假定\mathcal{D}是d维向量数据点x \in[0,1]^{d}和相应标签y上的分布,\theta为待优化模型参数,\mathcal{L}为损失函数,\mathcal{S}为对抗扰动集合,\mathcal{F}为对数据点施加扰动\xi \in \mathcal{S}的函数,r \sim \mathcal{R}为随机扰动向量。 对于通用对抗扰动,对抗扰动的集合表示为
\left\{ \xi \mid||\xi||_\infty\leq\epsilon\right\}
\mathcal{F}(x, \xi, r)=\operatorname{Clip}_{[0,1]}[x+\xi] \\
对于通用Patch 扰动,函数\mathcal{F}(x, \xi, r)b表示为:
\label{1} \mathcal{F}(x, \xi, r)=(1-T(m, r)) \cdot x+T(m, r) \cdot T(\xi, r)\\
其中,mask为m \in\{0,1\}^{d},对抗扰动的空间为\mathcal{S}=[0,1]^{d_{\text {patch }}},随机变换T为T=T_{l} \circ \cdots \circ T_{0}。
根据公式([1]),作者重新定义了通用对抗损失为:
\label{2} \rho_{u n i}(\theta)=\max _{\xi \in \mathcal{S}} \underset{(x, y) \sim \mathcal{D}, r \sim \mathcal{R}}{\mathbb{E}} \mathcal{L}(\theta, \mathcal{F}(x, \xi, r), y)\\
目的是找到使通用对抗损失最小化的模型参数即\theta^{*}=\arg \min _{\theta} \rho_{u n i}(\theta),这与标准对抗训练的思路一致,即内部最大化(生成对抗样本),外部最小化(利用对抗样本更新模型参数)。
作者通用对抗扰动的初始值进行元学习,并使用基于梯度的元学习来处理优化问题\left\{\xi_{t_{i}}\right\}_{i=1}^{N},在更新对抗目标函数的外部最小化的\theta_{t}的同时,作还对对初始化\Xi_{t}进行元学习。这样做的好处在于用尽量少的梯度步长来近似\xi_{t+1}的内部优化问题。
为了鼓励元扰动生成集的多样性,对于每个元扰动,需要随机分配一个目标,并执行有针对性的I-FGSM攻击。这避免了许多扰动收敛到类似的模式,可以愚弄模型预测相同的效果,还需要将随机选择的固定步长\alpha分配给每个元扰动。较大的步长对应于元扰动,元扰动更全局地探索允许的扰动空间,而较小的步长导致更细粒度的攻击。
为了能够更加清晰的展示出该论文中关于元对抗训练的过程,综合上述的算法介绍,我将论文中的算法流程图进行了重新进行了整理,如下框图所示:


实验结果
鲁棒性评估
该论文中的鲁棒性评估方法其实是扩展了于2018年Madry等人在PGD论文中的鲁棒性评估的方法。具体公式如下所示:
\rho_{u n i}(\theta)=\max _{\xi \in \mathcal{S}} \rho(\theta, \xi) \\\rho(\theta, \xi)=\underset{(x, y) \sim \mathcal{D}, r \sim \mathcal{R}}{\mathbb{E}} \mathcal{L}(\theta, \mathcal{F}(x, \xi, r), y) \\
根据上式利用蒙特卡洛则有如下的估计公式:
\hat{\rho}(\theta, \xi)=\frac{1}{N} \sum_{i=1}^{N} \mathcal{L}\left(\theta, \mathcal{F}\left(x_{i}, \xi, r_{i}\right), y_{i}\right) \\
其中数据采样\left(x_{i}, y_{i}\right) \sim \mathcal{D},随机向量r_{i} \sim \mathcal{R}。另外作者将随机投影(S-PGD)的对抗扰动的公式定义为:
\xi^{(0)} \sim \mathcal{S} \\\xi^{(k)}=\Pi_{\mathcal{S}}\left[\xi^{(k-1)}+\alpha \operatorname{sgn}\left(\nabla_{\xi} \hat{\rho}\left(\theta, \xi^{(k-1)}\right)\right)\right] \\
定性定量结果
作者利用覆盖大约占比图像14%(24x24像素)的通用Patch来评估鲁棒性,并且对于每个Patch从图像中心最多随机平移26个像素。每个模型利用SGD训练75轮,初始学习率为0.033,学习衰减率设置为0.9,Batch_Size为128。
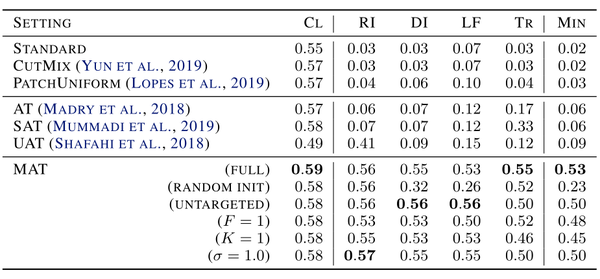
定量的结果如下图所示为对Tiny ImageNet(图片尺寸的大小为64x64,ImageNet的图片大小为256x256)分类器的攻击成功率。其中CL代表的是干净样本数据,RI是带有随机初始化的Patch的样本,DI是带有裁剪的Patch的样本,LF是低频滤波器样本,Tr是从其它模型中迁移过来的对抗样本。可以直观的发现,该论文中提出的MAT是在防御对抗攻击中效果最好的。

防御通用对抗Patch的定性的结果如下图所示,在AT,SAT,UAT,以及本文提出的MAT的对抗训练方法中,只用MAT起到了抵御对抗攻击的效果。


防御通用对抗扰动的定性的结果如下图所示,在AT,SAT,UAT,以及本文提出的MAT的对抗训练方法中,AT和MAT都完美的抵御对抗攻击。


整体综合来看,MAT在抵御通用对抗扰动中是最出色的。
论文标题:Meta Adversarial Training
论文链接:https://arxiv.org/abs/2101.11453
论文代码:http://github.com/boschresearch/meta-adversarial-training\
