
【深度学习】最优化方法
基本优化算法:
一、SGD
1.含义:
随机抽取m个小批量样本,计算梯度平均值,再进行梯度的更新。
2.算法:

3.学习率衰减:
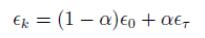 ,α=k/τ
,α=k/τ
说明:初始以ε0的学习率进行线性衰减,直到τ次迭代,τ次迭代之后学习率稳定在ετ。
4.参考:
https://blog.csdn.net/bvl10101111/article/details/72615436
二、momentum
1.含义:
通过累积前t-1次的动量,来影响本次的梯度更新,使得前进方向相同时,加速收敛,方向相反时,抑制震荡。
2.算法:

3.参考:
https://blog.csdn.net/bvl10101111/article/details/72615621
三、Nesterov(牛顿动量)
1.含义:
与momentum类似,不同是先计算临时点,然后在临时点计算梯度。
2.算法:

3.参考:
https://blog.csdn.net/bvl10101111/article/details/72615961
https://blog.csdn.net/tsyccnh/article/details/76673073
自适应参数的优化算法:
四、AdaGrad
1.含义:
设置全局学习率,每个参数的学习率不同,为全局学习率/历史梯度的平方和的平方根,注意是逐元素的。
2.算法:
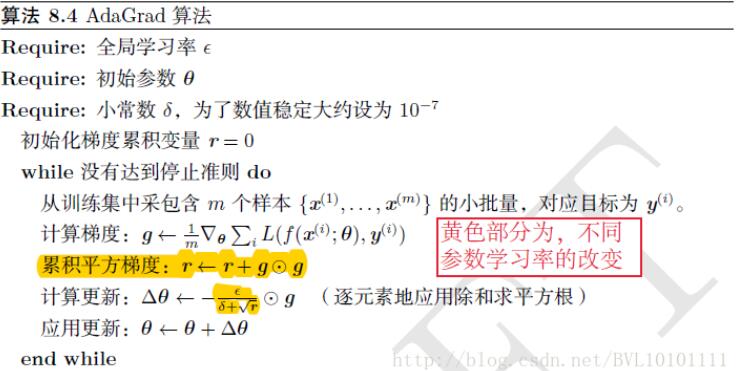
3.参考:
https://blog.csdn.net/bvl10101111/article/details/72616097
五、RMSProp
1.含义:
对AdaGrad的改进,加入对历史的衰减。
2.算法:

3.参考:
https://blog.csdn.net/bvl10101111/article/details/72616378
六、Adam
1.含义:
Momentum+RMSProp的结合,然后再修正其偏差。既利用了历史的动量,又对使得每个参数学习率不同。
2.算法:

3.参考:

