迁移学习》第四章总结---基于模型的迁移学习

基于模型的迁移学习可以简单理解为就是基于模型参数的迁移学习,如何使我们构建的模型可以学习到域之间的通用知识。
1. 基于共享模型成分的迁移学习
在模型中添加先验知识。
1.1 利用高斯过程的迁移学习
正态分布的概率函数的均值为 \mu , 方差为 \sigma^2 :
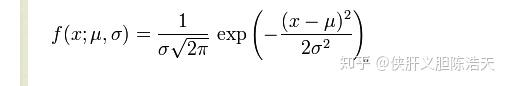

复习:如果一个随机变量 X 服从这个分布,写作 X \sim N(\mu, \sigma^2) , 如果均值为0,方差为1,则简化成:
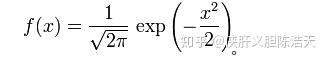
设有标签的数据集 X ,定义 隐变量 z 的高斯先验:
p(z|X,\theta) = N(0, K) . K 是协方差函数,或者说核函数。接下来的事同样也是构建似然函数,然后解答(借这个协方差矩阵)。
1.2 利用贝叶斯模型的知识迁移
顾名思义,还是逃不开贝叶斯的应用啊!
1.3 利用深度模型的模型迁移
知识蒸馏,也称为软标签。在基于模型的迁移学习中,通过计算类别 k 所有源样本的激励函数的 softmax 平均值,可以提取类别 k 的软标签 l . 基于软标签的类别间关系知识的损失定义如下:
L_{softlabel}(x_t,y_t;\theta_repr, \theta_c) = -\sum_{}^{}{l^k softmax(\theta_{c}^{T}f(x_T;\theta_repr) / \tau)}
到底软标签什么意思呢?其实很简单,举个例子我们的软标签 l 是一个 k 维向量,就是有 k 个类别,那么 l^{bottle} 水杯的类别可能就有:外观,颜色,长度,价钱等等。我们计算每一个类别的输出,经过softmax看一下那个权重占比是最大的。同样地我们可以看看bottle和cup,chair输出是多少,一对比就知道是杯子与瓶子更贴近。
2. 基于正则化的迁移
如何通过正则化来对共享知识进行迁移?
模型中标准的正则化形式: \tilde{J}(\theta;X,y) = J(\theta;X,y) + \alpha\Omega(\theta) 这个式子表明该正则化使用正则权重 \alpha 正则化 \theta . 其中 \theta_s = \theta_0 + v_s , \theta_t = \theta_0 + v_t . 利用任务间的不变特征(模型迁移学习中被迁移的部分、源域模型中的任务无关参数),提高目标模型的泛化性能。
2.1 基于SVM的正则化
在此基础上加上正则项进行优化。
2.3 Fine tune
往期文章:
