
ICBU可控文本生成技术详解
简介: 文本生成(Text Generation)是自然语言处理(Natural Language Processing,NLP)领域的一项重要且具有挑战的任务。顾名思义,文本生成任务的目的是生成近似于自然语言的文本序列,但仍可以根据输入数据进行分类。本文我们聚焦于输入文本生成文本的 Text-to-Text 任务,具体地包括神经机器翻译、智能问答、生成式文本摘要等。

来源 | 阿里技术公众号
一 文本生成技术
文本生成(Text Generation)是自然语言处理(Natural Language Processing,NLP)领域的一项重要且具有挑战的任务。顾名思义,文本生成任务的目的是生成近似于自然语言的文本序列,但仍可以根据输入数据进行分类。比如输入结构化数据的 Data-to-text Generation,输入图片的 Image Caption,输入视频的 Video Summarization,输入音频的 Speech Recognition 等。本文我们聚焦于输入文本生成文本的 Text-to-Text 任务,具体地包括神经机器翻译、智能问答、生成式文本摘要等。
随着深度学习的发展,众多新兴的技术已被文本生成任务所采用。比如,为了解决文本生成中的长期依赖、超纲词(Out-of-Vocabulary,OOV)问题,注意力机制(Attention Mechanism),拷贝机制(Copy Mechanism)等应运而出;网络结构上使用了循环神经网络(Recurrent Neural Networks),卷积神经网络(Convolutional Neural Networks),图神经网络(Graph Neural Networks),Transformer 等。为了顺应“预训练-精调”范式的兴起,在海量语料上自监督地训练出的大体量预训练语言模型(Pre-trained Language Model;PLM),也被广泛应用在文本生成任务中。
为了展示上述结构、模型、机制在文本生成任务上的应用,本章第一小节会简要梳理主流文本生成模型的结构,在第二小节会对于文本生成的评价指标的方案进行归纳。
1 文本生成模型的结构
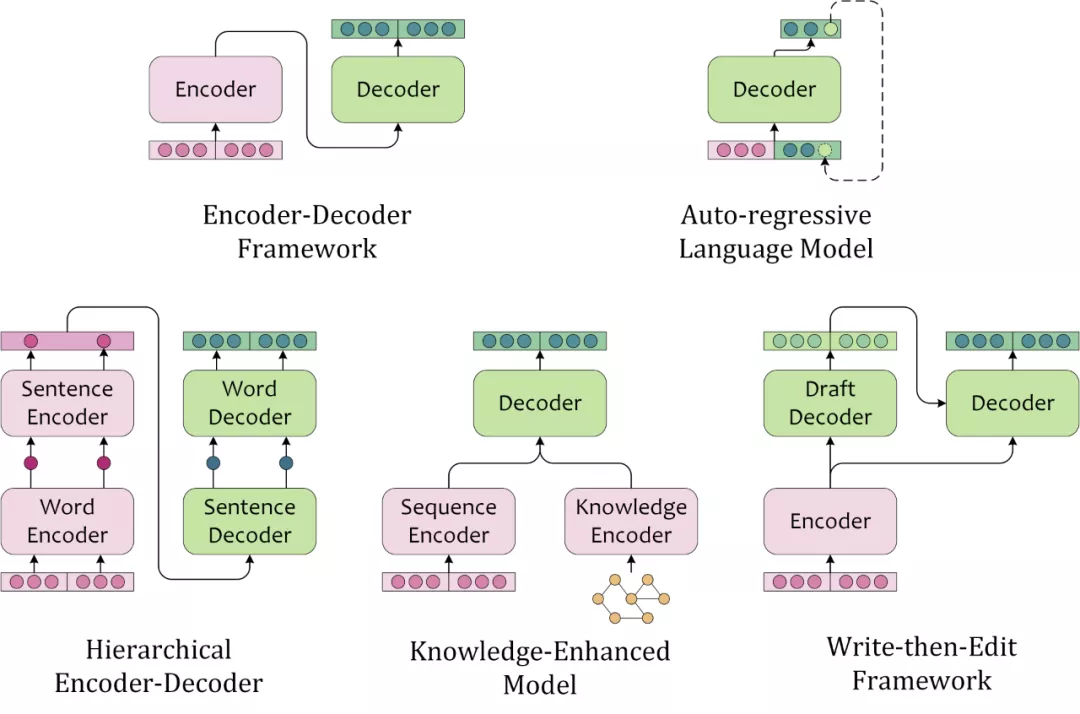
文本生成模型的结构常来自于人类撰写文本的启发。此处按照模型结构的特征,将主流文本生成模型分为如下几种:
Encoder-Decoder Framework
“编码器-解码器框架”首先使用 encoder 编码文本,再使用 decoder 基于原文编码和部分解码输出,自回归地解码(Autoregressively Decoding)出文本。这类似于,人类首先理解素材(源文本、图片、视频等),然后基于对原文的理解和已写出的内容,逐字地撰写出文本。也是目前序列到序列任务中应用最广泛的框架结构。
Auto-regressive Language Model
标准的 left-to-right 的单向语言模型,也可以根据前文序列逐字地解码出文本序列,这种依赖于前文语境来建模未来状态的解码过程,叫做自回归解码(Auto-regressive Decoding)。不同于编码器-解码器框架”使用 encoder 编码源文本,用 decoder 编码已预测的部分序列,AR LM 用同一个模型编码源文本和已解码的部分序列。
Hierarchical Encoder-Decoder
对于文本素材,人类会先理解单个句子,再理解整篇文本。在撰写文本的过程中,也需要先构思句子的大概方向,再逐字地撰写出内容。这类模型往往需要一个层次编码器对源文本进行 intra-sentence 和 inter-sentence 的编码,对应地进行层次 sentence-level 和 token-level 的解码。在 RNN 时代,层次模型分别建模来局部和全局有不同粒度的信息,往往能够带来性能提升,而 Transformer 和预训练语言模型的时代,全连接的 Self-Attention 弱化了这种优势。
Knowledge-Enriched Model
知识增强的文本生成模型,引入了外部知识,因此除了针对源文本的文本编码器外,往往还需要针对外部知识的知识编码器。知识编码器的选择可以依据外部知识的数据结构,引入知识图谱、图片、文本作为外部知识时可以对应地选用图神经网络、卷积神经网络、预训练语言模型等。融合源文本编码与知识编码时,也可以考虑注意力机制,指针生成器网络(Pointer-Generator-Network),记忆网络(Memory Networks)等。
Write-then-Edit Framework
考虑到人工撰写稿件尚不能一次成文,那么文本生成可能同样需要有“修订”的过程。人工修订稿件时,需要基于原始素材和草稿撰写终稿,模型也需要根据源文本和解码出的草稿重新进行编解码。这种考虑了原文和草稿的模型能够产生更加合理的文本内容。当然也会增加计算需求,同时生成效率也会打折扣。

2 文本生成的评价指标
针对文本生成的评价指标,已有多年研究。根据不同的维度,可以对现有评价指标有着不同的分类。比如,部分评价指标仅考虑所生成的文本,来衡量其自身的流畅度、重复性、多样性等;另一部分指标还考虑到了源文本或目标文本,来考察所生成的文本与它们之间的相关性、忠实度、蕴含关系等。
此处,我们从执行评价的主体类型进行分类,来梳理当前常用的文本生成的评价指标:
Human-centric evaluation metrics
文本生成的目标是获得人类能够理解的自然语言。因此,邀请专家或受训练的标注者来对生成内容进行评价,或者比较多个模型的输出文本,是最直观的评价方式。人工评价在机器难以判别的角度也能发挥作用,比如:衡量生成文本句间的连贯性(Coherence),衡量生成文本近似于自然语言程度的通顺度(Fluency),衡量生成文本中的内容是否忠实于原文的事实正确度(Factuality),以及风格、格式、语调、冗余等。此外,为了衡量人工打标的可靠性,可以让多个标注者对进行同一样本打标,并使用 IAA(Inter-Annotator Agreement)来对人工评价结果进行评估。常用的是 Fleiss' ,以及 Krippendorff's 。
Unsupervised automatic metrics
基于规则统计的无监督自动指标,能够适应大体量测试集上的文本评价。最常见的就是 ROUGE-N(Recall-Oriented Understudy for Gisting Evaluation)和 BLEU-N(BiLingual Evaluation Understudy),这两个指标考虑了 N-gram overlapping 的召回率和精确率,能够衡量文本的通顺度及与源文本的字面一致性。通常,为了衡量文本用词的多样性,Distinct-N 计算仅出现过一次的 N-gram 占生成文本中总 N-gram 个数的百分比。
Machine-learned automatic metrics
为了衡量输出文本在语义上的属性,常需要用训练好的判别模型。比如,为了建模目标序列与预测序列之间的相似度,可以使用 BERTScore 先利用 BERT 给出两个文本序列的语境化向量表征,再进行相似度矩阵的计算;GeDi 中使用 RoBERTa 训练出一个 Toxicity Classifier 来判别模型生成的文本是否包含恶意中伤的内容;自然语言推理任务中的文本蕴含(Textual Entailment)模型也可以用于衡量生成的摘要与原文之间在内容上的忠实程度。
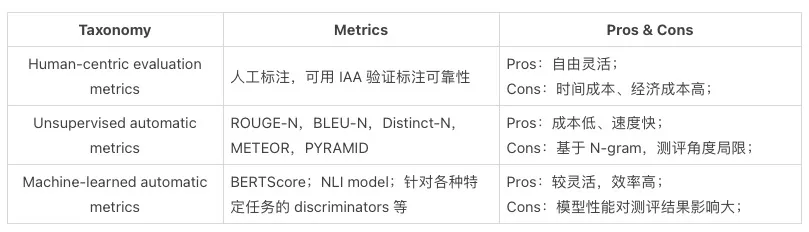
从上表我们可以看出,人工评价指标虽然灵活,不适合用于对海量样本评价。而无监督的自动评价指标,虽然能低成本地解决评测问题,但能够完成评价的角度甚少。“用模型来衡量模型”则是效率和灵活性之间的 trade-off。
但前提要保证判别模型本身的性能,才能保证测评结果的可靠性。Amazon 的工作证明开箱即用的 NLI 模型并不能保证内容忠实度评测的良好效果,由此看来,该类型的评价指标仍需要向 task-specific 和 data-specific 的方向上深挖,来弥合训练域与应用域之间的鸿沟。
二 可控文本生成
可控文本生成的目标,是控制给定模型基于源文本产生特定属性的文本。特定属性包括文本的风格、主题、情感、格式、语法、长度等。根据源文本生成目标序列的文本生成任务,可以建模为P(Target|Sourse);而考虑了控制信号的可控文本生成任务,则可以建模为P(Target|Sourse,ControlSignal)。
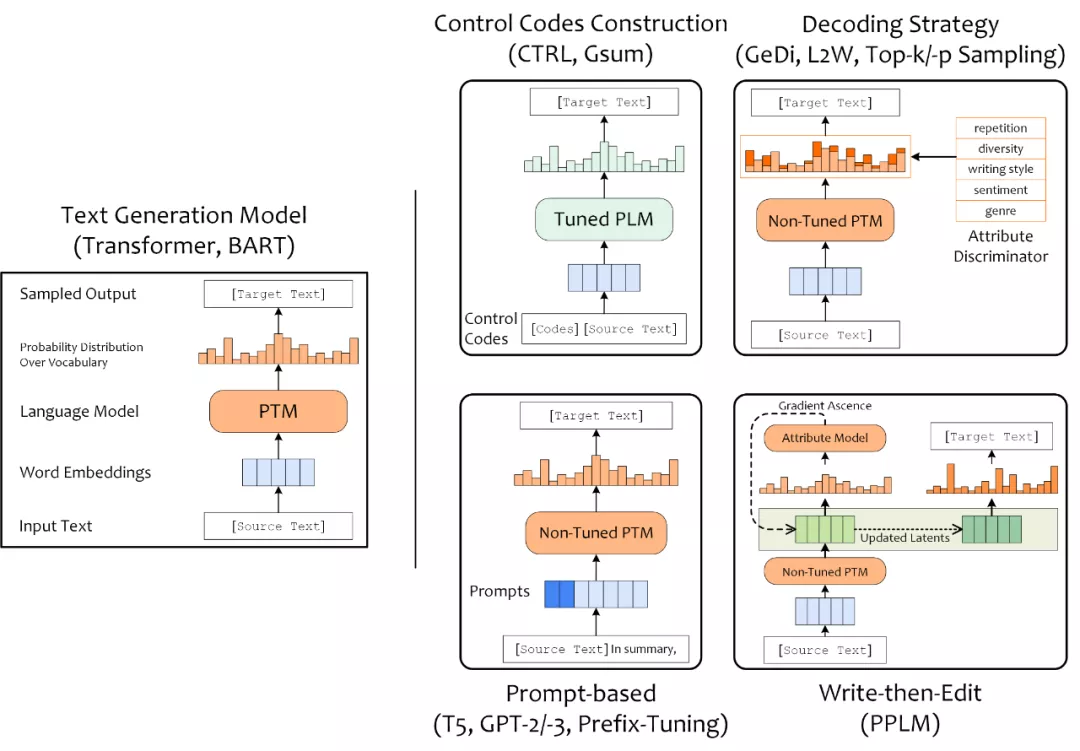
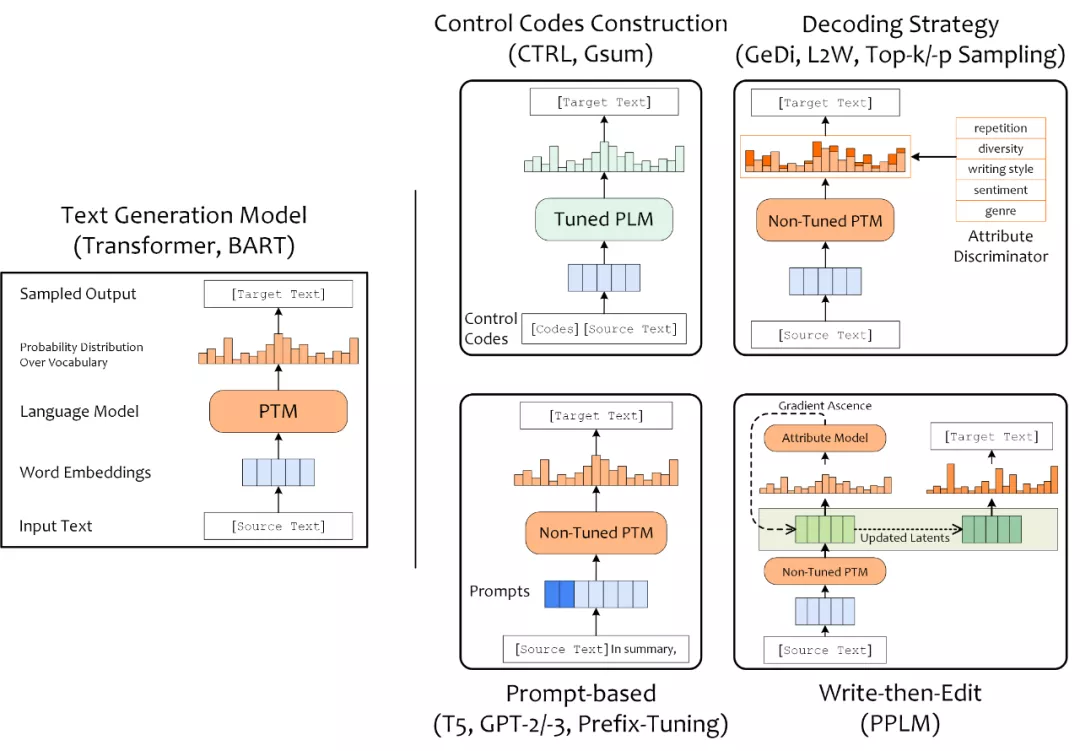
目前可控文本生成已有大量的相关研究,比较有趣的研究有,SongNet(Tencent)控制输出诗词歌赋的字数、平仄和押韵;StylePTB(CMU)按照控制信号改变句子的语法结构、单词形式、语义等;CTRL(Salesforce)在预训练阶段加入了 control codes 与 prompts 作为控制信号,影响文本的领域、主题、实体和风格。可控文本生成模型等方案也多种多样,此处按照进行可控的着手点和切入角度,将可控文本生成方案分为:构造 Control Codes、设计 Prompt、加入解码策略(Decoding Strategy),以及 Write-then-Edit 共四类。
构造 Control Codes 指的是引入一些符号或文本作为条件,训练条件语言模型;为预训练语言模型设计 Prompt 也能实现对 PLM 所执行文本任务的控制;通过在解码阶段使用采样策略,也能够采样出具有特定属性的文本;最后,Write-then-Edit 指的是 PPLM 引入属性判别模型来根据产生的草稿计算梯度并反向传播,基于更新后的隐含状态来产生最终文本序列。
此处,我们尝试从时间维度来分析可控文本生成技术的发展过程和趋势。
首先,在预训练语言模型的热度高涨之前,使用解码策略来控制文本属性的方案较为流行,比如,引入多个判别器影响 Beam Search 中的似然得分的 L2W,以及改进解码采样策略的 Nucleur Sampling(2019)。
随着 GPT-2(2019)、T5(2019)的提出,使得基于 Prompt 来控制同一预训练语言模型来完成多种任务成为可能。因其能够更有效地利用模型在预训练阶段习得的知识,Prompting LM 的方式受到了学术界的重视,Prefix-Tuning(2021)等也推动基于 Prompt 的文本生成向前一步。
而针对于如何基于预训练语言模型做可控文本生成,学术界也一直往“低数据依赖、低算力需求、低时间消耗”方向上推进。CTRL(2019)凭借海量数据和大体量结构成为文本生成领域的代表性模型;PPLM (2019)则引入属性判别器,仅需精调小部分参数起到了“四两拨千斤”的效果;而 GeDi(2020) 为了解决 PPLM 多次反传导致的解码效率低下,直接在解码阶段加入属性判别器来控制解码输出;CoCon(2021)同样仅精调插入 GPT-2 中的 CoCon 层来提高训练效率,并通过精巧的目标函数的设计来增强可控性能。
在本章,我们将针对上述提到的方案思路和模型细节,进行详细的介绍。
1 设计 Prompt
由于预训练任务与下游任务之间存在差距,为了充分利用模型在预训练阶段习得的知识,可以通过设计 prompt 的方法,将下游任务建模为预训练任务。下面是 Prompting PLM 在非生成任务上的应用,可以清晰地理解 prompt 相对于 fine-tuning 的价值。
我们对在 Masked Language Model 任务上预训练出的 BERT进行精调,做实体类型识别(Entity Typing)任务。常规地,需要向 BERT 输入[CLS]He is from New York.,然后用分类器根据[CLS]的隐含状态对 New York 的实体类型做分类。然而,精调过程中的知识迁移无法避免地会造成知识损失,另外,为了训练新引入的分类器需要大量的训练样本,不适应 few-shot 场景。
将训练数据嵌入 prompt,下游的分类任务即可被转化为预训练的 MLM 任务。通过向模型输入He is from New York. In this sentance, New York is a [MASK].,利用模型更能胜任的 MLM 任务预测[MASK]对应的单词,即判断生成 New York 的实体类型。通过设计好的 prompt,可避免 fine-tuning。即不必调整 PLM 的结构和参数,完整保留预训练阶段的知识。也可以通过 prompt 的设计规避将下游任务训练样本的依赖,更适合 few-shot 和 zero-shot 场景。
Prompting 在非生成类任务上常用 Cloze-style 的 prompts 来适应用 MLM 预训练任务。而对于生成类任务,更常用的是 Prefix-style 的 prompts。相对于前者更侧重于充分利用 PLM,后者还能够对文本生成的任务实现可控。
GPT-2 作为通用的多任务模型,不仅要考虑源文本的信息,还要考虑将执行的任务,故被建模为P(Taget|Sourse,Task)。比如,将源文本嵌入模板[Sourse]TL;DR:作为 GPT-2 的输入,模型能够知晓下游任务是文本摘要,进而根据源文本自回归地续接出摘要。
T5 希望将多个自然语言处理任务整合成 text-to-text 的形式,来统一模型在预训练、精调阶段的任务。为了向 T5 模型明确所需执行的任务,源文本需要被嵌入模板。比如,输入summarize:[Sourse]来生成摘要,或输入translate English to German:[Sourse]来生成翻译等。T5 论文提到,任务前缀也是超参数,它们的 word,structure 对于下游任务的性能有潜在影响。这近似于预言了后来 prompting 的研究方向,Prompt Designing 也成为研究热点。通常对于不同的任务和数据集针对性设计 prompts 来适应,图2中展示了针对各生成相关任务的常用 prompts:

2 构造 Control Codes
此处,Control Codes 指的是输入模型的控制信号。控制信号的数据类型选择非常广泛,包括符号、单词、文本段落等。为了使得模型在训练阶段能捕捉并拟合控制信号的作用,进而能泛化到推理阶段,控制信号需要与目标序列高度相关。
构造训练数据
GSum(Guided Summarization)引入了四种控制信号,包括重要句子、关键单词、显著实体三元组,以及检索到的相关摘要。结构上,GSum 基于 Transformer 改进。源文本和文本类型的控制信号共享编码器,在编码器顶层两者各自有一层专属编码器。解码器部分包含两个 Multihead Cross Attention 分别关注源文本编码和引导信号编码。
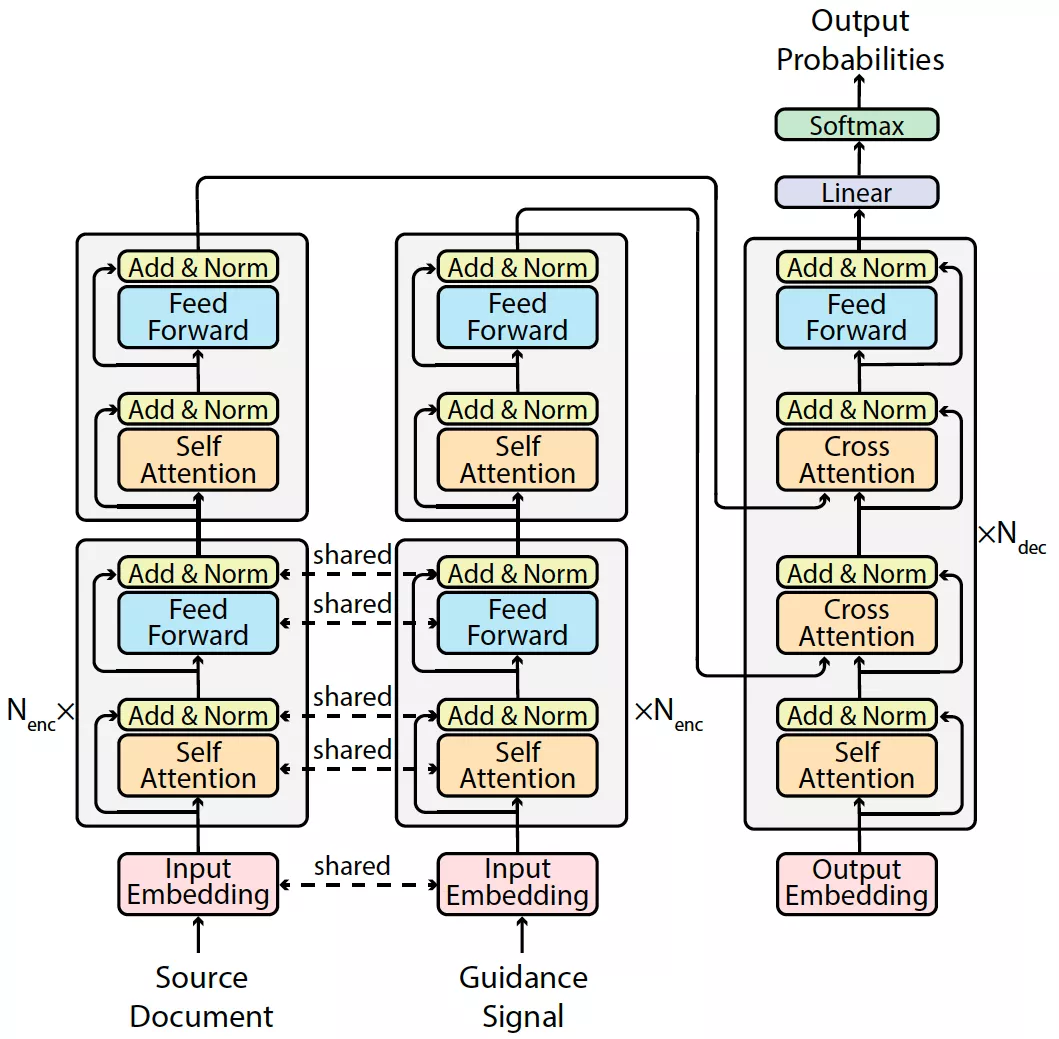
图4:GSum 模型结构图
为了保证控制信号与目标序列中存在可被捕捉的联系,实现摘要内容的可控,如何获取控制信号就显得尤为重要,即所构造的控制信号必须与目标序列高度相关。GSum 的训练和测试数据集中的控制信号的获取方式如下表所示:

通过构造与目标序列高度相关的控制信号作为训练数据,模型实现了内容上的可控。然而,如果将训练数据集中控制信号的构造方法替换为上述测试集的方法,导致模型性能下降。究其原因是相较于训练阶段的控制信号的构造方法,推理阶段的方案获得的控制信号与目标序列之间的联系更弱了。更强的控制信号与目标序列属性之间的相关性,可能带来更好的控制性能。
类似地,CTRLsum 为了控制输出摘要的和内容长度,也考虑了如何在控制信号中体现目标序列的长度属性。针对内容可控,CTRLsum 首先根据原文中的句子与目标序列之间的 ROUGE 得分抽取出关键句子,然后筛选出关键句子与目标序列中的最长公共子序列,去除重复和停用词后获得关键词作为控制信号。
但 CTRLsum 并没有显式地给定控制信号,而是通过关键词的个数来“暗示”。首先,将训练集中的样本按照目标摘要的长度排序后平分为 5 桶;然后,统计各桶中的平均关键词个数。
在训练样本中,仅保留目标摘要所在桶所对应个数的关键词作为控制信号,测试阶段即可利用所输入关键词的个数来控制摘要长度,利用关键词的内容来控制摘要内容。
设计损失函数
通过设计损失函数来建模控制条件与目标输出之间联系的典型例子,是 CoCon(Content Conditioner)。结构上,CoCon 在 GPT-2 medium 的前 7 层和后 17 层之间一个 CoCon block,包括 Layer Normalization、Multihead Cross Attention 和 Feed Forward Networks。模型整体接受源文本输入后,利用 CoCon 模块引入控制条件信息,再做自回归解码以生成文本。
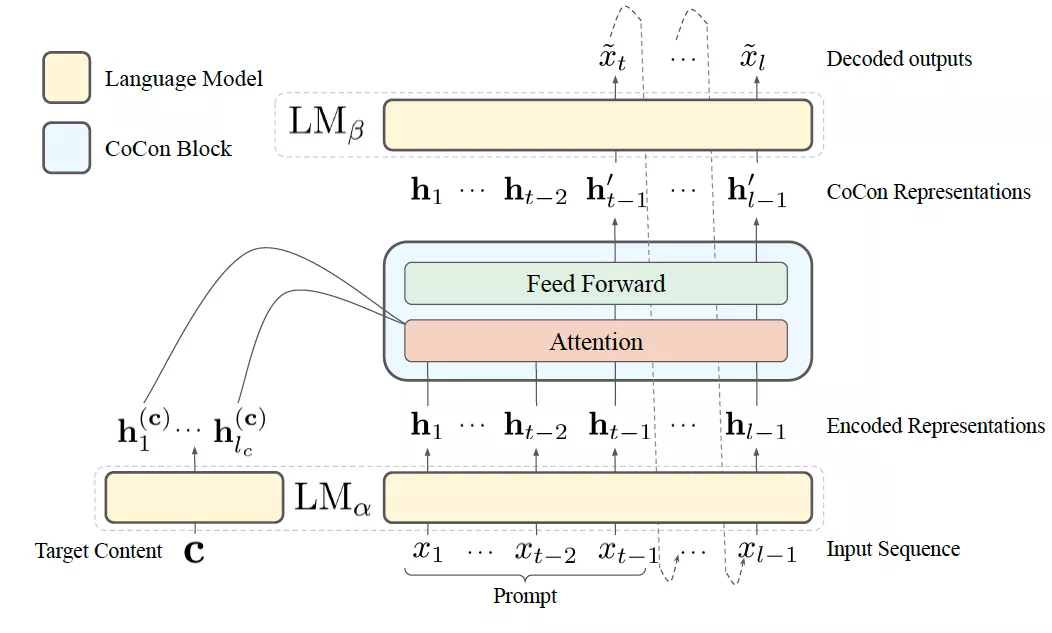
为了构造训练数据,CoCon 从 GPT-2 Output Dataset 中采样出 30 wordpieces 长度的样本,从第 8 到 12 的位置上将文本切分为两段。CoCon 建立控制条件文本与目标文本之间关系的方式,由以下三个巧妙设计的损失函数来实现。为了方便介绍,我们考虑两个文本样本x,y,分别被切分为x1,x2和y1,y2。
- Self Reconstruction Loss
此处将前半段x1作为源文本,后半段x2作为条件,损失函数基于预测输出与x2之间的负对数似然。之所以使用相同的后半段作为控制条件和目标序列,是为了让模型能够捕捉并利用控制控制条件中的信息。
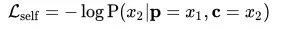
![]()
- Null Content Loss
将控制条件替换为符号ø,模型退化为非可控文本生成模型,训练出 CoCon 作为单向语言模型的性能。
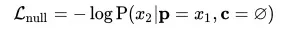
- Cycle Reconstruction Loss
首先将y1作为源文本,将x2作为条件输入 CoCon,生成文本zy1,x2 。然后使用x1作为源文本zy1,x2作为条件,希望模型能够生成x2。这就要求模型 1)在生成的结果zy1,x2中尽可能保留控制条件x2中的信息;2)在生成过程中尽可能利用上控制条件中保留的信息,即依据zy1,x2中保留的x2的信息复原x2。

3 加入 Decoding Strategy
不动预训练语言模型的参数与结构,仅通过解码阶段的策略入手,也能够影响解码输出的结果。切入点有两个,即 Beam Search 中似然得分的计算以及采样策略。
改进采样策略
Beam Search 是文本生成任务绕不开的话题。它介于局部最优的 Greedy Search,以及全局最优的 Global Search。Beam Search 在生成完整的预测文本序列的过程中,在每一个解码步都仅维护k个似然得分最高的 track 及其得分。在k个 track 的基础上进行下一步解码,获得k的平方个 track,再根据各自的似然得分进行采样,保留k个 track,直到解码过程终止。
其中,Beam Search 中每个 track 的似然得分计算方式如下:
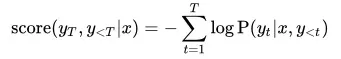
为了控制输出的文本长度,可以在似然得分上对于文本长度做惩罚,增加一个参数长度惩罚系数α:
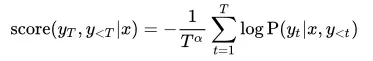
另一类解码策略从单词采样阶段入手,通常通过改变单词表上的概率分布,或根据规则限制候选集合的大小来实现。
单词表上的条件概率分布P(yt|x,y<t)由解码状态映射到单词表容量的维度后,经过 softmax 进行归一化所得。可通过影响 softmax 函数来控制当前解码时刻单词表上的概率分布,进而影响 Beam Search 中的似然得分以及采样结果。常见方案有 softmax with temperature,即在 softmax 上增加一个温度系数T:
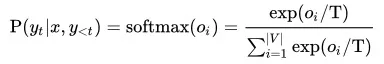
除了操控候选集合上的概率分布之外,还可以筛选候选集合中的成员。Top-K Sampling 通过设置候选集容量 k,仅保留单词表中概率最大的k个单词,缓解了因采样了不置信的长尾单词对输出结果的影响。Nucleus Sampling 通过设置一个概率值p,仅保留最少数量的累积概率达到p的候选单词。相较于 Top-K Sampling,Nucleus Sampling 的候选词表的维度即可动态地扩展或压缩。
两种采样方式也可以和 Softmax-with-temperature 结合起来使用,通常K<100,p∈[0.9,1.0)且T>0.7。
引入外部反馈
L2W(Learn to Write)模型根据格莱斯准则(Grice's Maxims),从 Quantity、Quality、Relation、 Manner 四个维度各引入了判别器,影响解码阶段的 Beam Search 中的似然得分。下表中介绍了 L2W 所引入的四种判别器,及其背后的动机。
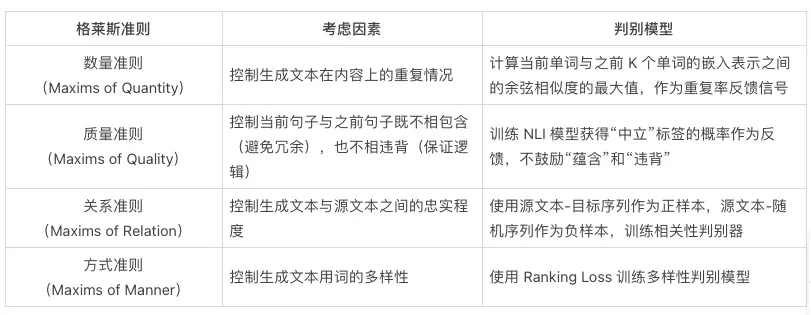
通过在解码阶段,L2W 通过各个判别器来衡量当前采样的候选结果,影响 Beam Search 的似然得分,鼓励模型生成较少重复、不自相矛盾、忠实于原文,并且用词丰富的文本。
由于训练语料未经严格过滤,预训练语言模型能够学会生成仇恨、偏倚或伤人的负面内容。GeDi(Generative Discriminator)的目标就是为预训练语言模型解毒(Detoxification)。诸如 CTRL 的可控文本生成模型可以学会“生成什么”,但不知道“不生成什么”。GeDi 可以通过计算单词表上的概率分布时,用正反两个类别的概率分布做标准化,从而明确模型鼓励或抑制的内容。
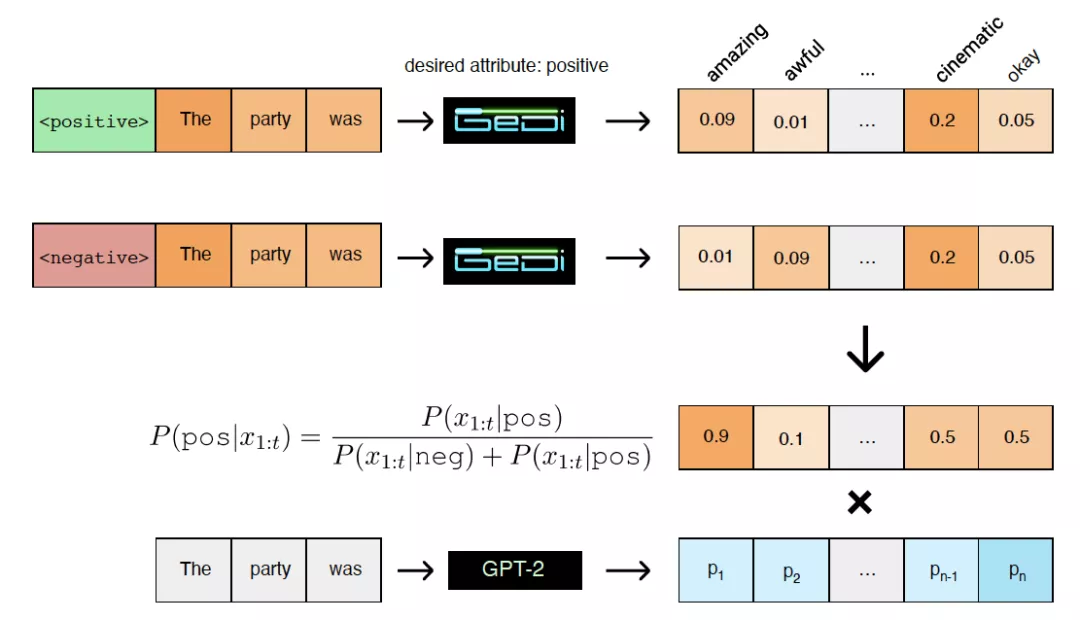
条件语言模型可以建模为P(xt|x<t,c)∝P(xt|x<t)P(c|xt,x<t)w。其中,GPT-2 作为语言模型可以给出公式右侧的PGPT2(xt|x<t)。GeDi 训练出一个类别条件语言模型 CCLM 来建模PGeDi(xt|x<t,c)。考虑到 GeDi 的训练样本中 control code和 control code 总成对出现,则根据贝叶斯定理可获得公式右侧的分类概率:
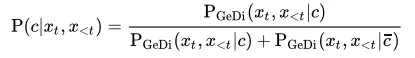
如此,即可通过类别条件语言模型 GeDi 来引导语言模型 GPT2 进行条件生成,即控制模型向类别c生成。除了用 positive、nagative 标签影响情感极性之外,还对于四个主题使用 [True] + 主题词、[False] + 主题词分别作为 control code 和 anti-control code 来训练类别条件语言模型 GeDi,实验结果也证明 GeDi 模型能够泛化到训练集中四个主题之外的领域上,实现主题可控。
4 Write-then-Edit 类
受到 CV 领域 PPGN(Plug and Play Generative Networks)的启发,通过插入属性判别模型来引导模型生成特定属性的文本的 PPLM 应运而生。PPLM 作者按照场景将语言模型进行如下分类:
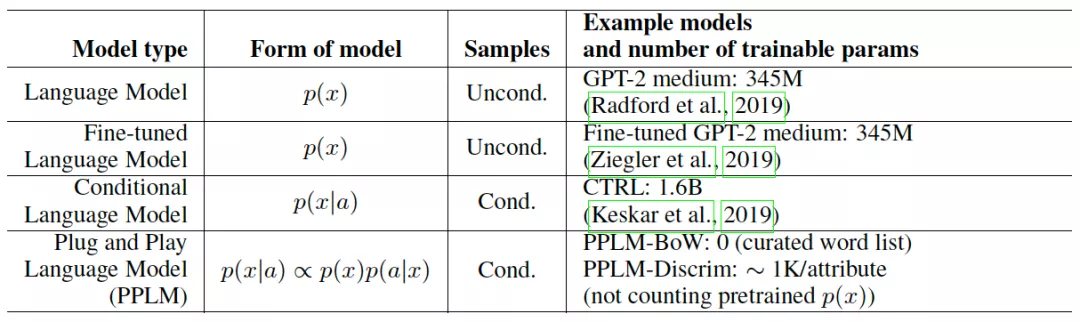
可以看到,为了适应下游任务的需求通常需要对预训练语言模型进行 fine-tuning,比如 GPT2。并且为了构造条件语言模型,还需要在条件语料上进行训练,比如 CTRL。而 PPLM 通过使用生成模型p(x),以及属性判别模型p(a|x),来建模条件生成p(x|a)∝p(a|x)p(x),理论依据同 GeDi 一样都是贝叶斯定理。如此,我们就不需要在海量包含属性条件的标注数据上,将大体量的预训练语言模型训练为p(x|a)。只需要训练出一个小体量的属性判别模型P(a|x),即可引导语言模型P(x)做条件生成,起到“四两拨千斤”的效果。
PPLM 使用 GPT-2 Medium 作为基础语言模型,并引入两种属性模型。其一是为各个主题构造词袋模型(Bag of Words,BoW)。对于词袋中的每个单词,将模型输出的其对数似然概率进行求和作为损失;其二是固定住语言模型后在上层添加单层判别器,获得目标类别的似然概率作为损失,对属性模型进行训练。
在推理阶段,使用梯度上升(Gradient Ascending)沿着语言模型p(x)的更高似然(体现语言建模性能)和属性模型p(a|x)的更高似然(体现类别可控性能)的两个梯度之和来影响历史隐含状态,而不改变模型参数。
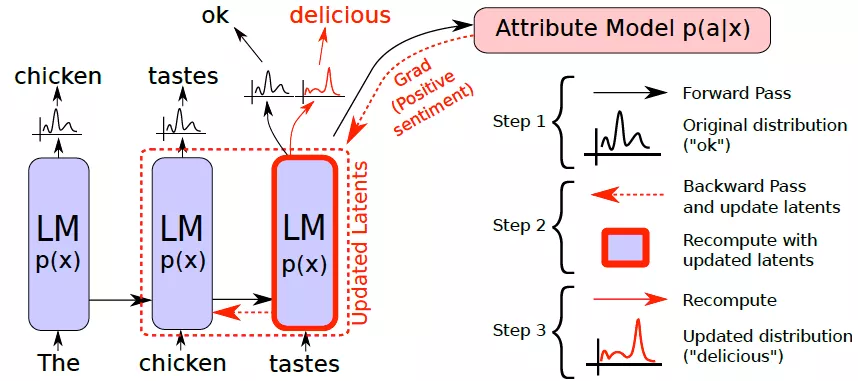
通过如上图所示的多次“预测-反传-修正”的迭代,即可获得最终的单词表上的概率分布。实验结果表示,PPLM 可以保证在不严重损失语言模型的通顺性的情况下,实现属性可控。
三 技术总结
1 可控的思路
对于控制信号,可以像 L2W 和 PPLM 选择属性判别器的似然概率;也可以同 CTRL 一样设计 Prompts 和 control codes;或者可以像 GSum 引入句、词、段落、三元组等多种形式的内容。对于将控制信号反馈给模型的方式,可以如 PPLM 般基于梯度上升,也可以像 GeDi 直接修改单词表上的概率分布,或者同 Hafez 一样从 Beam Search 入手,将判别器给出的得分反馈到似然得分上。
然而,即使合理地引入了控制信号,也无法保证可控性能。还必须要确保训练数据集中控制信号与目标序列的确存在着某种联系。控制信号作为自变量,输出文本作为因变量,自变量与因变量之间存在相关性,才可能用函数(可能是深度模型)进行拟合。
从 GSum、CTRLSum 的训练数据的构造方式,以及 CoCon 训练目标的设计思路都可以看出:为了实现推理阶段生成文本的属性受控制信号影响,就需要让模型在训练阶段就能够捕捉控制信号,并且能够建模控制信号与目标序列之间的联系。哪怕是像 CTRLSum 中为训练集中的摘要长度分桶后,用桶的标签作为控制信号,这也算是一种隐含的联系。
由此,我们可以总结可控的基本思路是:选择合理的控制信号,以合理的方式将控制信号输入模型,进而对模型造成影响。
2 发展的趋势
从时间上来看,Salesforce 在 2019 年发布的可控文本生成的代表性模型 CTRL,纯依赖于数据来训练条件语言模型。CTRL 首先它学了个 250k 的 BPE 词表,模型层数增加至 48 层,隐层维度为 1280,前馈层内部维度 8192,预训练语料足足 180 Gb,因而训练成本高昂。
同年,UberAI 认为训练完整的条件语言模型代价太大,因此推出了使用小体量的判别器来引导大体量预训练语言模型的 PPLM 来实现可控生成,理论基础是贝叶斯定理。但 PPLM 的问题在于解码过程中多次梯度反传影响隐含状态导致效率太低。
后继在 2020 年,Salesforce 推出的 GeDi 同样根据贝叶斯定理,将条件语言模型分解为语言模型和属性判别模型,属性判别模型直接影响单词表上的概率分布,解决了 PPLM 解码速度慢的问题。
2021 年,NTU 提出的 CoCon,为了通过“文本”作为可控生成的条件。结构上,在 GPT-2 中插入了一层 CoCon Block 来编码文本条件,并设计了四种巧妙的损失函数来训练 CoCon 层的可控性能,而不修改预训练语言模型的参数。
总结来看,这个发展的过程中的目标是:1)对于海量标注数据的依赖;2)精调阶段对计算资源的高需求;3)推理阶段高时耗;4)控制信号的种类限制。
除了最初的 CTRL 需要训练语言模型的全部参数之外,PPLM 固定 GPT2 Medium 的参数,仅训练属性模型;GeDi 中固定语言模型 GPT-XL 的参数,仅训练 GPT2 Medium 作为 CCLM 来引导生成;CoCon 仅训练插入到 GPT2 的前 7 层和后 17 层之间的 CoCon Block,而不调整 GPT2 的参数。并且各工作在实验中也常针对可控生成在不同领域的泛化性进行研究。
可以看出,可控文本生成研究的趋势,并不是针对某个领域、某个主题、某种控制条件,训练出一个完整的条件语言模型做可控生成。而是,不仅要从效率和性能两个角度更好地利用预训练语言模型,更要强调可控的效果和泛化性。
当然,Prompt 相关方案的提出,也是为了拉近预训练阶段的任务与下游任务之间的关系,从而使得在不必精调的情况下,获得下游任务性能的提升。这个思路,同样是为了更有效率地利用预训练语言模型,并以期能够挖掘到“预训练”本身具有而“精调”无法带来的性能增益。
四 ICBU 详情页底纹可控生成
基于搜索日志中 Item-query 之间点击行为来获得的详情页底纹,无法为没有流量访问的长尾商品关联到 query 作为搜索底纹。为了解决长尾商品的数据冷启动问题,这次暑期实习项目中,我们将可控文本生成技术应用于 Query 生成任务,来为基于点击行为来关联商品-query 的方案兜底,并形成了如下的技术框架。
该技术框架其中分为三个模块,首先是基于 BART 训练条件语言模型,使得模型能够根据 control codes 来生成对应实体的 query,实现实体类型可控;其次是召回数量可控,在 Beam Search 采样阶段不仅考虑候选集中元素的似然得分,并考虑上各元素的长度惩罚,使得模型能够采样出更相关、更符合表达习惯且更精炼的 query,从而能够带来更多召回;最后是 Query 价值判别模型,将生成的 Query 输入判别模型获得价值得分后反馈给生成器,从而生成潜在转化价值更高的 query。
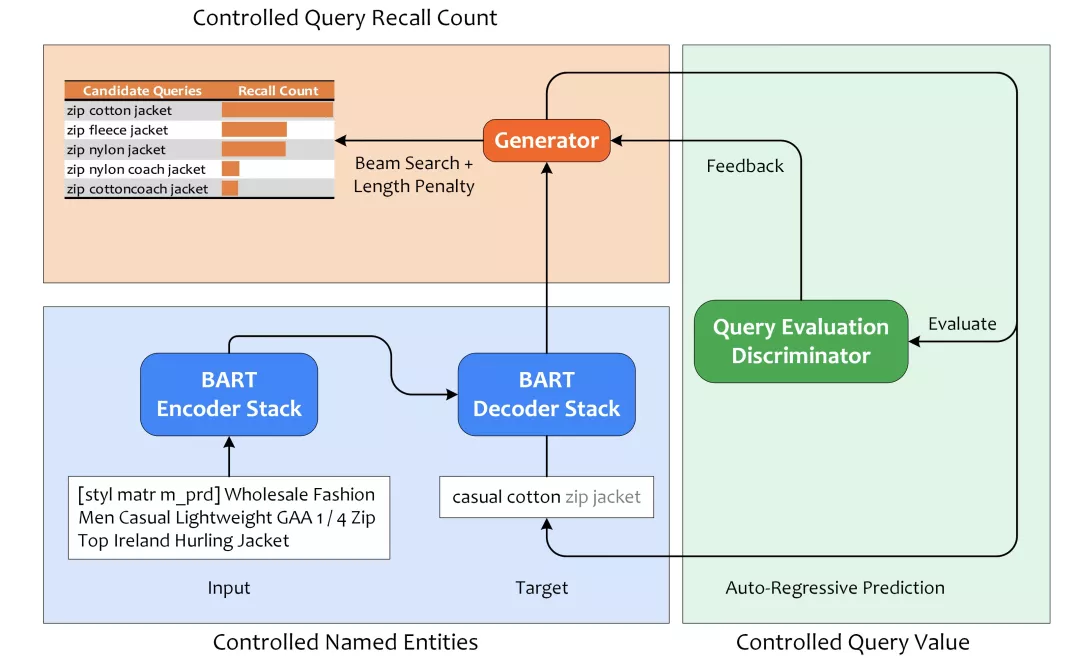
我们做可控 Query 生成的动机是:用户在搜索不同类目下的商品时所使用的搜索词中,实体类型的分布不同。用户在搜索电子产品的时候,搜索词中出现型号类型的实体更多;而搜索美妆产品的时候会更侧重于使用方式。此外,针对同一行业,不同类目下的实体类型偏好分布也不同。服装行业下,搜索裙装类目时用户更关注产品的风格,搜索婚纱类目时用户更偏好于材料。
因此,我们考虑,用户看到更符合她/他输入习惯的搜索词后更愿意点击,从而提升详情页搜索底纹模块的渗透率。我们不仅希望为商品生成的 Query 中的实体类型符合用户对该类目的偏好。此处的可控我们考虑两点,一方面是生成 Query 中的实体类型可控,一方面是生成 Query 中实体顺序可控。
此处我们在数据集构造上入手,建立控制信号(实体类型序列)与目标 query(实体序列)之间在类型和顺序上的对应关系。为了加强这种关系,还对训练数据进行了数据增强,包括随机 drop 实体,打乱实体顺序等。在实体内容层面上,考虑不多不少不重不漏的精确匹配率进行评测;在实体顺序层面上,我们使用 Levenshtein Distance 来评价。
此外,我们还考虑获得表达更精简的 Query,能够在倒排索引阶段召回更多商品,供给排序侧能够将更相关的产品推给用户。该需求通过解码阶段的 Beam Search 上增加 Length Penalty 来实现,不仅考虑了似然得分(与标题的内容相关性),还考虑了长度惩罚(Query 表达简洁性);
另外,我们设计了一个 Query 价值判别模型,为生成内容的潜在价值进行评估。此处考虑了搜索日志中 Query 的点击转化、询盘转化、CVR、CTR 等指标,基于该数据训练了 XLNet-Base 来判别 Query 价值。可以在生成阶段对 Query 价值进行反馈,采样出潜在价值更高的 Query。
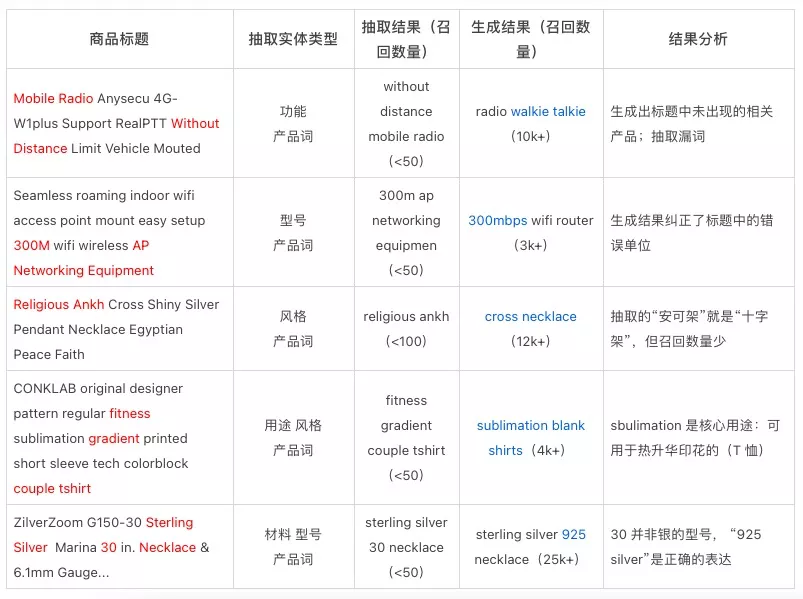
此处,我们展示了一些可控 Query 生成的例子,并且与抽取式基线模型进行对比。可以看出,生成的 Query 具有联想相关产品、纠正表达错误、生成常用表达、生成专业表达、明晰实体搭配等特性。我们的可控 query 生成模型能够为行为类方案覆盖不到的商品提供高质量的生成式 Query。
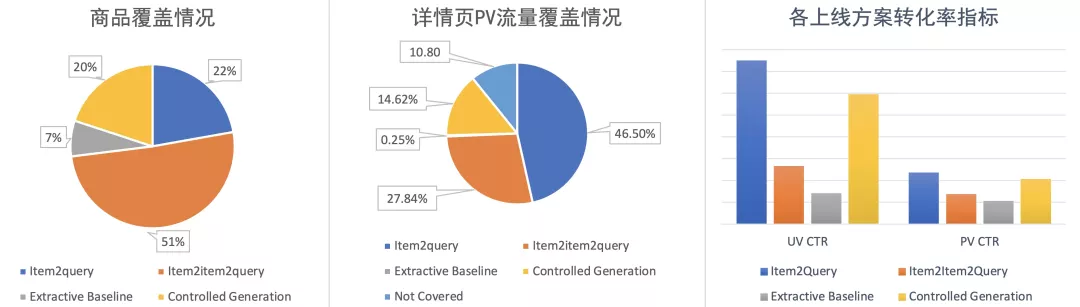
目前,详情页底纹推荐模块上线的四种方案包括,Item2Query 基于点击行为使用 TF-IDF 关联商品的重要 Query 作为底纹,Item2Item2Query 基于主图相似度关联到的相似商品共享底纹,按照热门实体类型从标题中抽取实体的抽取式基线模型,以及我们的可控 Query 生成模型。上线后的指标也显示,在 CTR 指标上,可控生成提供的 Query 的转化率仅次于 Item2Query 基于行为关联到的 Query。
五 可控文本生成相关数据集
- StylePTB:细粒度文本风格迁移基准数据集:
- SongNet:格式可控的宋词生成任务:
- GPT-2 Output:可用于构造可控文本生成数据集的大体量语料库:
- Inverse Prompting:公开领域的诗文生成,公开领域的长篇幅问答数据集:
- GYAFC (Grammarly’s Yahoo Answers Formality Corpus):雅虎问答形式迁移语料库:
六 参考文献
- Li, Junyi, et al. "Pretrained Language Models for Text Generation: A Survey." arXiv preprint arXiv:2105.10311 (2021).
- Raffel, Colin, et al. "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer." Journal of Machine Learning Research 21 (2020): 1-67.(Original BART Paper)
- Lewis, Mike, et al. "BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension." Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.(Original T5 Paper)
- Zhang, Jingqing, et al. "Pegasus: Pre-training with extracted gap-sentences for abstractive summarization." International Conference on Machine Learning. PMLR, 2020.(Original Pegasus Paper)
- Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI blog 1.8 (2019): 9.(Original GPT-2 Paper)
- Zhu, Chenguang, et al. "A Hierarchical Network for Abstractive Meeting Summarization with Cross-Domain Pretraining." Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings. 2020.(Original HMNet Paper)
- Liu, Chunyi, et al. "Automatic dialogue summary generation for customer service." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.(Original Leader-Writer network Paper)
- Jin, Hanqi, Tianming Wang, and Xiaojun Wan. "Semsum: Semantic dependency guided neural abstractive summarization." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 05. 2020.(Original Semsum Paper)
- Zhu, Chenguang, et al. "Boosting factual correctness of abstractive summarization with knowledge graph." arXiv e-prints (2020): arXiv-2003.(Original FASum Paper)
- Xia, Yingce, et al. "Deliberation networks: Sequence generation beyond one-pass decoding." Advances in Neural Information Processing Systems 30 (2017): 1784-1794.(Original Deliberation Networks Paper)
- Wang, Qingyun, et al. "Paper Abstract Writing through Editing Mechanism." Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018.(Original Editing Mechanism Paper)
- Celikyilmaz, Asli, Elizabeth Clark, and Jianfeng Gao. "Evaluation of text generation: A survey." arXiv preprint arXiv:2006.14799 (2020).
- Lin, C. "Recall-oriented understudy for gisting evaluation (rouge)." Retrieved August 20 (2005): 2005.(Original ROUGE Paper)
- Papineni, Kishore, et al. "Bleu: a method for automatic evaluation of machine translation." Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 2002.(Original BLEU Paper)
- Li, Jiwei, et al. "A Diversity-Promoting Objective Function for Neural Conversation Models." Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016..(Original Distinct-N Paper)
- Zhang, Tianyi, et al. "Bertscore: Evaluating text generation with bert." arXiv preprint arXiv:1904.09675 (2019).(Original BERTScore Paper)
- Falke, Tobias, et al. "Ranking generated summaries by correctness: An interesting but challenging application for natural language inference." Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.(Amazon uses NLI tools to evaluate summarization)
- Li, Piji, et al. "Rigid formats controlled text generation." Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.(Original SongNet Paper)
- Lyu, Yiwei, et al. "StylePTB: A Compositional Benchmark for Fine-grained Controllable Text Style Transfer." Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021.(Original StylePTB Paper)
- Keskar, Nitish Shirish, et al. "Ctrl: A conditional transformer language model for controllable generation." arXiv preprint arXiv:1909.05858 (2019).(Original CTRL Paper)
- Liu, Pengfei, et al. "Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing." arXiv preprint arXiv:2107.13586 (2021).
- Dou, Zi-Yi, et al. "GSum: A General Framework for Guided Neural Abstractive Summarization." Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021.(Original GSum Paper)
- Chan, Alvin, et al. "CoCon: A self-supervised approach for controlled text generation." arXiv preprint arXiv:2006.03535 (2020).(Original CoCon Paper)
- Holtzman, Ari, et al. "The curious case of neural text degeneration." arXiv preprint arXiv:1904.09751 (2019).(Original Nucleus Sampling Paper)
- Holtzman, Ari, et al. "Learning to Write with Cooperative Discriminators." Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018.(Original L2W Paper)
- Krause, Ben, et al. "Gedi: Generative discriminator guided sequence generation." arXiv preprint arXiv:2009.06367 (2020).(Original GeDi Paper)
- Dathathri, Sumanth, et al. "Plug and play language models: A simple approach to controlled text generation." arXiv preprint arXiv:1912.02164 (2019).(Original PPLM Paper)
本文为阿里云原创内容,未经允许不得转载。

