注意力机制整理
attention机制原多用于NLP领域,是谷歌提出的transformer架构中的核心概念。现在cv领域也开始越来越多的使用这种方法。本次分享对注意力机制进行了相关的梳理,旨在帮助大家入门attention机制,初步了解attention的结构以及背后原理。
1. attention概念
1.1 什么是attention
attention机制可以认为它是一种资源分配的机制,可以理解为对于原本平均分配的资源根据attention对象的重要程度重新分配资源,重要的单位就多分一点,不重要或者不好的单位就少分一点,在深度神经网络的结构设计中,attention所要分配的资源基本上就是权重了。
视觉注意力分为几种,核心思想是基于原有的数据找到其之间的关联性,然后突出其某些重要特征。
最近读了一些论文,目前接触过的有
- 通道注意力 (CBAM: Convolutional Block Attention Module)
- 时间注意力 (EDVR: Video Restoration with Enhanced Deformable Convolutional Networks)
- 空间注意力 (CBAM: Convolutional Block Attention Module)
- 软注意力 (Learning Texture Transformer Network for Image Super-Resolution)
- 硬注意力 (Learning Texture Transformer Network for Image Super-Resolution)
括号里是提出的论文,感兴趣的同学可以自己了解
1.2 为什么要用attention
attention会参考各个特征之间的关系,从而分配权重。对比起RNN网络attention能够并行化处理。
2. Self-Attention
2.1 Self-Attention的简单理解
可以理解位将队列和一组值与输入对应,即形成querry,key,value向output的映射,output可以看作是value的加权求和,加权值则是由Self-Attention来得出的。
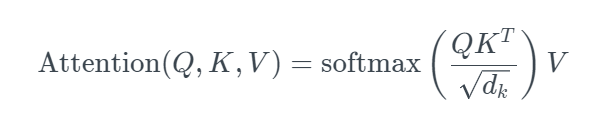
这个公式很难理解,首先将上述的这个公式简化为
然后我们可以一点点拆分这个公式进行分析
1.\(XX^T\)代表什么
一个矩阵\(X\)乘以它自己的转置\(X^T\),矩阵可以看作由一些向量组成,一个矩阵乘以它自己转置的运算,其实可以看成这些向量分别与其他向量计算内积。
向量的内积,其几何意义是什么?
答:表征两个向量的夹角,表征一个向量在另一个向量上的投影 ,投影的值大,说明两个向量相关度高。
向量之间相关度高表示什么?是不是在一定程度上(不是完全)表示,在特征A的时候,应当给予特征B更多的关注?
2.Softmax的意义
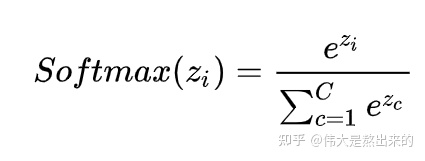
至此,我们理解了公式 中,
的意义。
我们进一步,Softmax的意义何在呢?
答:归一化
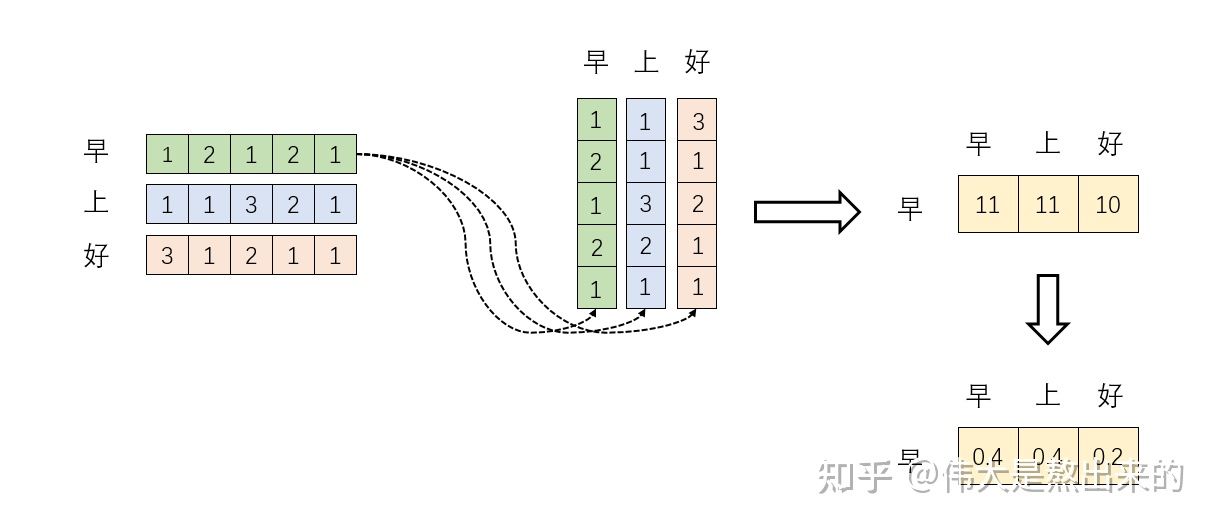
我们结合上面图理解,Softmax之后,这些数字的和为1了。我们再想,Attention机制的核心是什么?
加权求和
那么权重从何而来呢?就是这些归一化之后的数字。
在该图中,我们以一个“早上好”作为矩阵\(X\),并以此进行计算\(XX^T\),然后通过\(softmax\),得到每个字相关的权重。即当我们关注"早"这个字的时候,我们应当分配0.4的注意力给它本身,剩下0.4关注"上",0.2关注"好"。
2.2 Self-Attention的具体实施细节
下图就是Self-Attention的计算机制。已知输入的单词embedding,即\(x_1\)和\(x_2\),想转换成\(z_1\)和\(z_2\)。

step 1. 特征向量X
step 2. 计算Q,K,V
先把x1转换成三个不一样的向量,分别叫做q1、k1、v1,然后把x2转换成三个不一样的向量,分别叫做q2、k2、v2。那把一个向量变换成另一个向量的最简单的方式是什么?就是乘以矩阵进行变换了。所以,需要三个不同的矩阵Wq、Wk、Wv,即
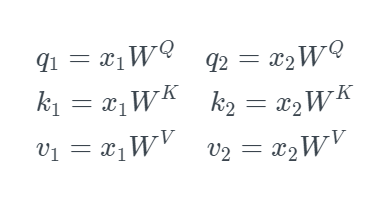

step 3. 计算组合权重
有了q1、k1、v11和q2、k2、v2,怎么才能得到z1和z2呢?计算过程是这样子的:我们用v1和v2两个向量的线性组合,来得到z1和z2,即

那怎么才能得到组合的权重 θ呢?有
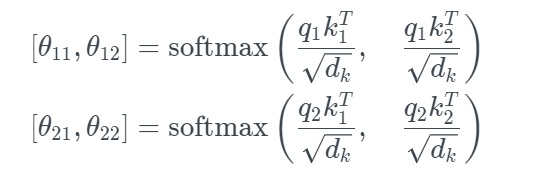
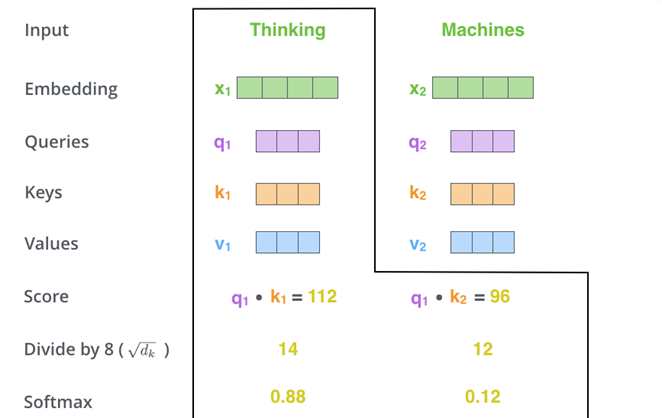
通过上述的整个流程,就可以把输入的x1和x2转换成了z1和z2。这就是Self-Attention机制。


Note
注意,上式中的\(d_k\)是向量q或k的维度,这两个向量的维度一定是一样的,因为要做点积。但是v的维度和向量q或k的维度不一定相同。上式为什么要除以\(d_k\)呢?因为为了防止维数过高时\(QK^T\)的值过大导致softmax函数反向传播时发生梯度消失。那为什么是\(\sqrt{d_k}\)而不是\(d_k\)呢?这就是个经验值,从理论上来说,就是还需要让\(QK^T\)的值适度增加,但不能过度增加,如果是\(d_k\)的话,可能就不增加了。
2.3 如何理解Q,K,V向量
讲到这里,你肯定很困惑为什么要有q、k、v向量,因为这个思路来自于比较早的信息检索领域,q就是query,k就是key,v就是值,(k,v)就是键值对、也就是用query关键词去找到最相关的检索结果。
举个例子,假设query是5G,然后k-v键值对有
k-v: 5G : Huawei
k-v: 4G : Nokia
那query(5G)和key(5G)的相关性是100%,和key(4G)的相关性是50%。这就是为什么用query,key,value这种概念。
2.4 attention 与 self-attention对比
以Encoder-Decoder框架为例,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention发生在Target的元素Query和Source中的所有元素之间。
Self Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的Attention。
两者具体计算过程是一样的,只是计算对象发生了变化而已。
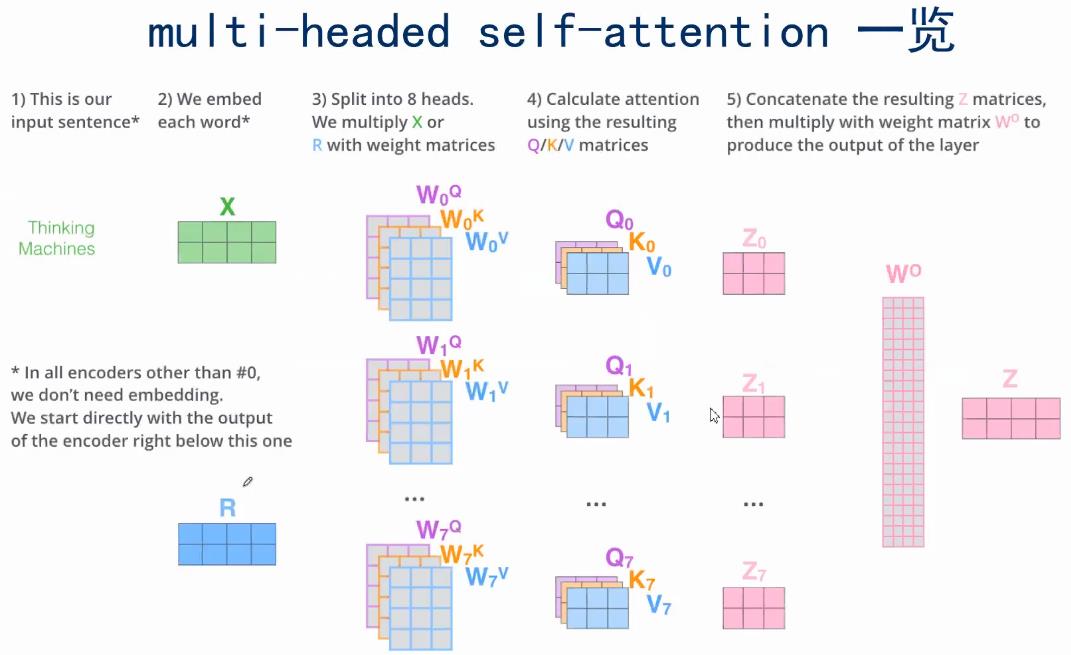
2.5. 扩展 Multi-Head Attention
如果用不同的\(W^Q\)、\(W^K\)、\(W^v\),就能得到不同的Q、K、V。multi-headed Attention就是指用了很多个不同的\(W^Q\)、\(W^K\)、\(W^v\)。

那这样的好处是什么呢?可以让Attention有更丰富的层次。有多个Q,K,V的话,可以分别从多个不同角度来看待Attention。这样的话,输入x,对于不同的multi-headed Attention,就会产生不同的z
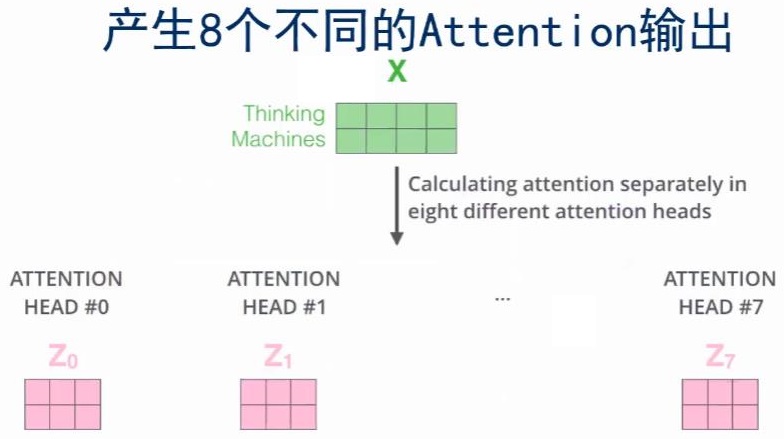
那现在一个x就有了多个版本的z,那该怎么结合为一个z呢?
那就将多个版本的z拼接称为一个长向量,然后用一个全连接网络,即乘以一个矩阵,就能得到一个短的z向量。
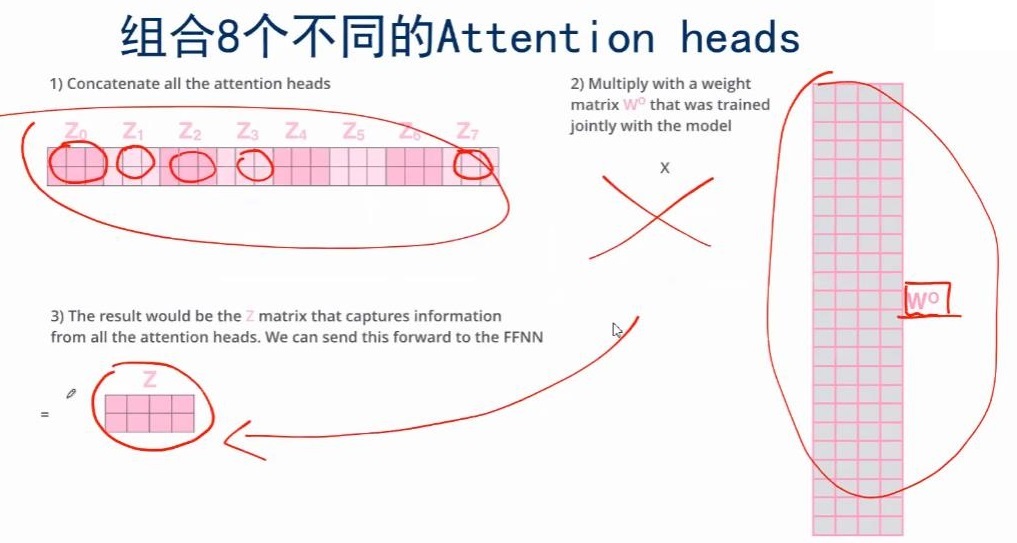
把multi-headed输出的不同的,组合成最终想要的输出的,这就是multi-headed Attention要做的一个额外的步骤。