
重磅直播|林宙辰、程明明、邓成领衔的CSIG-CVPR2020图像语义分割&跨模态学习专题报告会来了

| 极市线上分享 第58期 |


今年CVPR 2020会议将于6 月 14-19 日在美国西雅图举行, 目前会议接收论文结果已公布,从 6656 篇有效投稿中录取了 1470 篇论文,录取率约为 22% 。极市平台特推出了CVPR 2020专题直播分享,往期分享请前往
上月,极市平台独家直播了CSIG –广东省CVPR2020预交流报告会,受到了大家的一致好评,在线观看人数达1.8万人,这次极市平台将继续为大家带来一顿丰富的学术大餐。
6月6日(星期六),极市将独家直播由中国图象图形学学会(CSIG)主办的CSIG-CVPR 2020图像语义分割和跨模态学习专题学术报告会。
直播地址:http://live.bilibili.com/3344545
CSIG-CVPR 2020论文专题学术报告会为了给相关领域研究者、技术开发人员和研究生介绍计算机视觉前沿理论、方法及技术的一些最新进展,邀请了程明明和邓成两位领域专家分别介绍图像语义分割和跨模态学习前沿进展,国内此领域部分优秀团队的青年学子介绍他们今年CVPR 2020录用论文的最新研究成果,不仅如此,报告会还特地设置了圆桌讨论环节,大家可以期待一下教授大牛和青年学子们精彩的思想碰撞。
01 直播信息
时间:2020年6月6日 (周六)09:30~16:35
主题
CSIG-CVPR 2020论文专题学术报告会 | 图像语义分割和跨模态学习专题
02 嘉宾介绍

程明明研讨主题:图像语义分割前沿进展南开大学教授,计算机系主任,国家“万人计划”青拔、“优青”获得者。主要研究方向为计算机视觉和计算机图形学,在图像场景理解、视觉显著性物体检测等方面取得了多项具有国际影响力的创新性成果。在相关领域顶级(CCF A类)国际期刊和会议上发表学术论文50余篇,入选Elsevier 2016-2018中国高被引学者榜单。多项技术被普林斯顿大学、布朗大学等国际著名大学的图形学和视觉课程列为课程内容。

邓成研讨主题:跨模态学习前沿进展西安电子科技大学教授、博士生导师。中国图像图形学会高级会员、中国计算机学会高级会员。主要研究方向为多模态数据协同计算理论与方法。在国际一流期刊T-NNLS、T-CYB、T-IP、T-MM等和国际顶级会议ICML、NeurIPS、ICCV、CVPR、KDD、AAAI、IJCAI等上发表论文70余篇。现担任国际知名期刊Pattern Recognition、Neurocomputing副编辑;担任多个国际学术会议的高级程序委员/程序委员,如ICML、NeurIPS、ICCV、CVPR、KDD、AAAI、IJCAI等。
03 会议流程
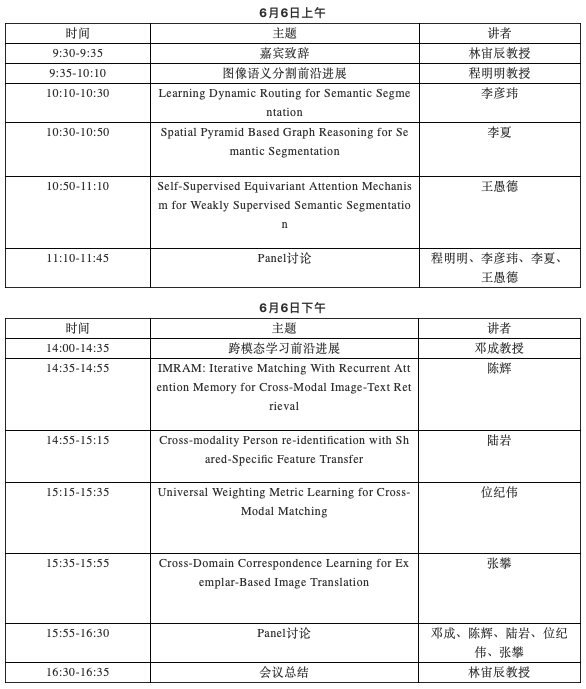

04 报告题目及中文摘要
➤报告1. Learning Dynamic Routing for Semantic Segmentation(面向语义分割的动态路由学习)
摘要:最近,大量手工设计和搜索得到的网络被应用于语义分割。然而,之前的工作大多在预先定义的静态网络结构中处理各种尺度的输入,如FCN、U-Net和DeepLab系列等。本文研究了一种概念上的新方法来缓解语义表示中的尺度差异,并将其命名为动态路由。我们所提出的框架会生成与数据相关的路由,以适应每个图像的尺度分布。为此,我们提出了一个可差分的门函数,称为软条件门,用于动态选择尺度变换路径。此外,通过对门函数进行预算约束,可以进一步降低计算成本。我们进一步放宽了网络级路由空间,以支持多路径传播和每次转发中的跳接,并带来了可观的网络容量。为了证明动态特性的优越性,我们与几种静态网络结构进行了比较,这些结构可以作为路由空间中的特殊情况进行建模。在Cityscapes和PASCAL VOC 2012上进行了广泛的实验,以说明动态框架的有效性。论文链接:https://arxiv.org/pdf/2003.10401.pdf代码链接:https://github.com/yanwei-li/DynamicRouting
报告人:李彦玮(中科院自动化所研究生)
➤报告2.Spatial Pyramid Based Graph Reasoning for Semantic Segmentation(面向语义分割的基于空间金字塔的图推理算法)
摘要:全局建模对于密集的预测任务(如语义分割)来说是基本操作,但传统卷积运算受到有限感受野的限制。本文中,我们将图卷积应用到语义分割任务中,并提出了一种改进的Laplacian。图推理算法直接在组织为空间金字塔的原始特征空间中进行。与现有的方法不同,我们的Laplacian是依赖数据的,并且我们引入了一个注意力对角线矩阵来学习一个更好的距离度量。它摆脱了映射和再映射的过程,使得我们提出的方法成为一个轻量级模块,可以很容易地插入到当前的计算机视觉网络架构中。更重要的是,直接在特征空间中执行图推理可以保持空间关系,使得空间金字塔可以从不同尺度上探索多种远距离的上下文模式。在Cityscapes、COCO Stuff、PASCAL Context和PASCAL VOC等数据集上的实验证明了我们提出的方法在语义分割上的有效性。我们在计算和内存开销方面具有性能优势。
论文链接:https://arxiv.org/pdf/2003.10211.pdf
报告人:李夏(北京大学研究生)
➤报告3.Self-Supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation(基于自监督等效注意力机制的弱监督语义分割)
摘要:图像级弱监督语义分割是近年来深入研究的一个具有挑战性的问题。大多数先进的解决方案都利用了类激活图(CAM)。然而,由于全监督和弱监督之间的差距,CAM很难作为物体掩码。在本论文中,我们提出了一种自监督等效注意力机制(SEAM)来发现额外的监督并缩小差距。我们的方法基于如下观察,即等价性是全监督语义分割中的一个隐含约束,其像素级标签在数据增强过程中采取与输入图像相同的空间变换。然而,这种约束在通过图像级监督训练的CAM上会丢失。因此,我们提出了对来自不同变换图像的预测CAM进行一致性正则化,以提供网络学习的自监督。此外,我们提出了一个像素相关模块(pixel correlation module,PCM),利用上下文信息,通过相似的近邻来细化当前像素的预测,进一步提高CAMs的一致性。在PASCAL VOC 2012数据集上的大量实验表明,我们的方法在相同的监督水平下,其性能优于最先进的方法。该代码已经在网上发布。论文链接:https://arxiv.org/pdf/2004.04581.pdf代码链接:https://github.com/YudeWang/SEAM
报告人:王愚德(中科院计算所博士生)
➤报告4.IMRAM: Iterative Matching With Recurrent Attention Memory for Cross-Modal Image-Text Retrieval(基于循环注意力记忆的迭代匹配算法-跨模式检索)
摘要:启用图像和文本的双向检索,对于理解视觉和语言之间的对应关系非常重要。现有的方法利用注意力机制,以精细的方式探索这种对应关系。然而,他们中的大多数方法都是平等地考虑所有的语义,从而将它们统一起来,而不考虑它们的多样复杂性。事实上,语义是多样化的(即涉及不同种类的语义概念),而人类通常遵循一种隐式结构将它们组合成可理解的语言。在现有的方法中,可能很难对这种复杂的对应关系进行优化捕捉。在本文中,为了解决这样的缺陷,我们提出了一种迭代匹配与循环注意力记忆(IMRAM)方法,在这种方法中,图像和文本之间的对应关系是通过多步对齐来捕获的。具体来说,我们引入了一种迭代匹配方案来逐步探索这种细粒度的对应关系。记忆蒸馏单元被用来细化从早期步骤到后期步骤的对齐知识。在三个基准数据集,包括Flickr8K、Flickr30K和MS COCO的实验结果表明,我们的IMRAM达到了最先进的性能,很好地证明了它的有效性。同时在KWAI-AD商业广告数据集上的实验进一步验证了我们的方法在实际场景中的适用性。
论文链接:https://arxiv.org/pdf/2003.03772.pdf代码链接:https://github.com/HuiChen24/IMRAM
报告人:陈辉(清华大学博士生)
➤报告5.Cross-modality Person re-identification with Shared-Specific Feature Transfer(基于共享特殊性特征转移的跨模态行人重识别)
摘要:跨模态行人重识别是智能视频分析的一项具有挑战性但又很关键的技术。现有的工作主要集中在通过将不同的模态嵌入到同一个特征空间中,然后学习共性表示。然而,仅学习共性特征意味着极大的信息损失,降低了特征差异性的上限。在这篇文章中,我们提出了一种新型的跨模态共享特征转移算法来解决上述局限性,探索模态共享信息和模态特异性特征对提高重识别性能的潜力。我们根据共享特征对不同模态样本的亲和性进行建模,然后在模态之间和跨模态之间转移共享和特定的特征。我们还提出了一种互补特征学习策略,包括模态自适应、对抗性学习和重构增强,分别学习各模态的判别性和互补共享特征和特定特征。整个算法可以通过端到端的方式进行训练。我们进行了综合实验,验证了整体算法的优越性和各组件的有效性。在两个主流基准数据集SYSU-MM01和RegDB上,提出的算法分别超出当前最好算法22.5%和19.3%的mAP。
论文链接:https://arxiv.org/pdf/2002.12489.pdf
报告人:陆岩(中国科学技术大学研究生)
➤报告6.Universal Weighting Metric Learning for Cross-Modal Matching(基于通用权重度量学习的跨模态匹配)
摘要:在视觉和语言领域,跨模态匹配一直是一个重要的研究课题。学习适当的挖掘策略,对信息对进行采样和加权,对于跨模态匹配的性能至关重要。然而,现有的度量学习方法大多是针对非模态匹配而开发的,不适合在具有异质特征的多模态数据上进行跨模态匹配。为了解决这个问题,我们提出了一个简单的、可解释的通用加权框架,为分析各种损失函数的可解释性提供了工具。此外,我们在通用加权框架下引入了一个新的多项式损失函数,分别定义了正负信息对的加权函数。在两个图像-文本匹配基准和两个视频-文本匹配基准上的实验结果验证了该方法的有效性。
报告人:位纪伟(电子科技大学博士生)
➤报告7.Cross-Domain Correspondence Learning for Exemplar-Based Image (针对示例图像的跨域对应性学习)
摘要:我们提出了一个基于示例的图像翻译的通用框架,它从一个不同领域的输入(例如,语义分割掩模,或边缘贴图,或姿势关键点)中,给定一个示例图像,合成一个照片逼真的图像。输出的风格(例如颜色、纹理)与示例中的语义对象一致。我们提出联合学习跨域对应和图像翻译,这两个任务相互促进,因此可以在弱监督下学习。来自不同域的图像首先被对齐到一个中间域,在这个中间域中建立了密集的对应关系。然后,网络根据示例中语义对应块的外观来合成图像。我们证明了此方法在一些图像翻译任务中的有效性。我们的方法在生成图像的质量方面明显优于最先进的方法,图像风格和示例图像具有很好的语义一致性。此外,我们还展示了此方法在多个应用中的实用性。
论文链接:https://arxiv.org/pdf/2004.05571.pdf代码链接(未来会开源):https://panzhang0212.github.io/CoCosNet/
报告人:张攀(中国科学技术大学博士生)
