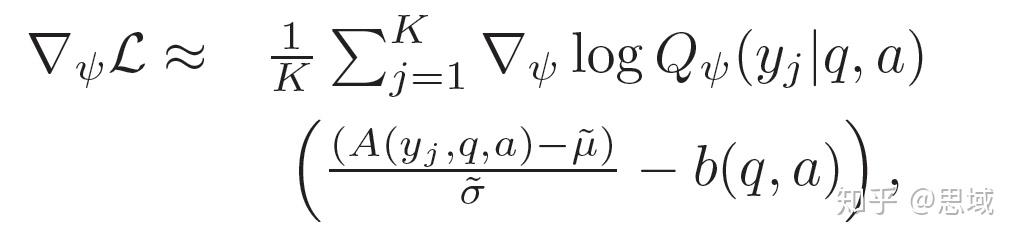在知识图谱上使用变分推断来问答--VRN

原论文:Variational Reasoning for Question Answering with Knowledge Graph
一、介绍
变分推断网络(VRN)解决只依据(问题-答案)在知识图谱上进行多跳推理。
VRN是一个端到端的QA系统,采用概率模型框架,使用变分推断获得目标函数下界,对下界进行优化(最大化),使用强化学习算法结合方法差减小技术训练模型。
二、问题定义
- 知识图谱(KG)
\mathcal{G}=(V(\mathcal{G}),V(\mathcal{G})) , E(\mathcal{G}) 表示3元组 (a_i^1,r_i,a_i^2) ,其中 a_i^1,a_i^2 表示实体, r_i 表示关系。 V(\mathcal{G}) 表示知识图谱中所有顶点的集合。
2、QA系统
q表示问题,a表示答案,训练数据集 D_{train}=\{(q_i,a_i)\}_{i=1}^N
三、整体结构
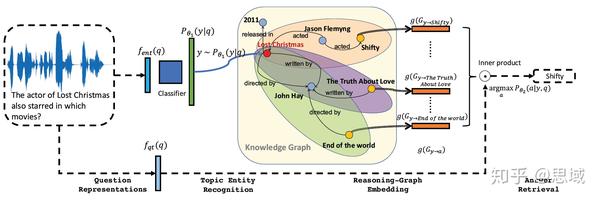

VRN模型可以分成两个模块:
1.topic entity提取模块
比如who acted in the movie Passengers中topic entity 是Passengers。用概率模型表述就是 P_{\theta_1}(y|q_i) ,其中 y 表示topic entity。
\begin{align} P_{\theta_1}(y|q) &= softmax(W_y^Tf_{ent}(q))\\ &=\frac{exp(W_y^Tf_{ent}(q) )}{\sum_{y^{'}\in V(\mathcal{G})}exp(W_{y^{'}}^T f_{ent}(q)) } \end{align} \tag{1}
其中 W_y \in \mathbb{R}^d,\forall y\in V( \mathcal{G}) 。
2. 逻辑推断模块
给定问题 q_i 和这个问题的topic entity y 找答案 a_i 。用概率模型表述成 P_{\theta_2}(a_i|y,q_i) 。推断模块从topic entity y开始,最多经过T跳到达 a_i (多个结果)。T被假设已经知道,一般比较小(如2,3,4),实际使用时可以枚举T。
模型具体构造方式:
\begin{align} P_{\theta_2}(a|y,q) &= softmax(f_{qt}(q)^Tg(\mathcal{G}_{y\rightarrow a})) \\&=\frac{exp(f_{qt}^Tg(\mathcal{G}_{y\rightarrow a}))}{\sum_{a^{'}\in V(\mathcal{G}_y)}exp(f_{qt}^Tg(\mathcal{G}_{y\rightarrow a^{'}})) } \tag{2} \end{align},
\begin{align} g(\mathcal{G}_{y\rightarrow a}) = \frac{1}{\#Parent(a)} \sum_{a_j \in Parent(a),\\ (a_j,r,a) or (a,r,a_j)\in \mathcal{G}_y} \sigma(V\times[g(\mathcal{G}_{y \rightarrow a_j}),e_r])\tag{3} \end{align} ,
r\in \mathcal{R},V\in\mathbb{R}^{d\times(d+|\mathcal{R}|)} , \sigma(.) 是非线性激活函数, e_r 是关系的one-hot编码。
3. 整个变分模型的最大化似然
\mathop{max}\limits_{\theta_1,\theta_2}\frac{1}{N} \mathop{\sum}\limits_{i=1}^{N} log\left(\mathop{\sum}\limits_{y\in V(\mathcal{G})}P_{\theta_1}(y|q_i)P_{\theta_2}(a_i|y,q_i)\right) \tag{4}
直接使用对公式(4)进行梯度更新是无法收敛的。原因是模型 P_{\theta_1}(y|q_i) 经过softmax后输出的是离散值,y是其中概率最大的值。这里假设输出的是 y_1 ,而最适合的是 y_0 。从 P_{\theta_2}(a_i|y,q_i) 获得的反向梯度实际上只会指导 y_1 概率变大或者变小,对 y_0 的影响是不确定的。当然一种对应的想法是经过足够多的更新次数,使 y_1 的概率变得比 y_0 小,这在二分类,或者类别极少的情况下可能有用,在多类别情况下是不一定会收敛的。(这是我直观的感受,不严谨)
所以,使用变分法对公式(4)求下界,最后算法通过优化下界来优化模型。这里先构造了一个概率模型 Q_\psi :
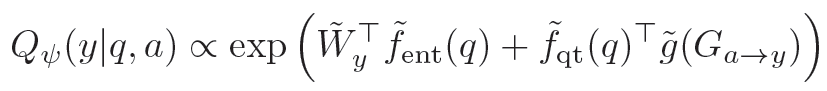

4. 求下界
\begin{align} & \mathop{\sum}\limits_{i=1}^{N} log\left(\mathop{\sum}\limits_{y\in V(\mathcal{G})}P_{\theta_1}(y|q_i)P_{\theta_2}(a_i|y,q_i)\right)\\ =& log\mathop{\sum}\limits_{i=1}^{N} \left(\mathop{\sum}\limits_{y\in V(\mathcal{G})} \frac{P_{\theta_1}(y|q_i)P_{\theta_2}(a_i|y,q_i)Q_{\psi}(y|q_i,a_i) } {Q_\psi(y|q_i,a_i)}\right)\\ =&logE[\frac{P_{\theta_1}(y|q_i)P_{\theta_2}(a_i|y,q_i)}{Q_\psi(y|q_i,a_i)}]\\ \geq & E_{Q_\psi}[logP_{\theta_1}(y|q_i)+logP_{\theta_2}(a_i|y,q_i)-logQ_\psi(y|q_i,a_i)] \tag{詹森不等式} \end{align}
于是令\begin{align} \mathcal{L}(\psi,\theta_1,\theta_2) = \frac{1}{N}\sum_{i=1}^{N}\mathbb{E}_{Q_\psi}[logP_{\theta_1}(y|q_i)+logP_{\theta_2}(a_i|q_i,y)-logQ_{\psi}(y|q_i,a_i)] \end{align}
\mathcal{L} 是公式(4)的一个下界,优化目标变为为 \mathop{max}_{\psi,\theta_1,\theta_2}\mathcal{L} 。
5. 计算梯度
已知 J(\theta)=E_{\tau\sim p_\theta}[r(\tau)] ,则可以推导出 \nabla J(\theta) = E_{\tau\sim p_\theta}[\nabla logP_\theta(\tau)r(\tau) ]
所以:
\nabla \mathcal{L} =\mathbb{E}[\nabla logQ(y|y_i,a_i)A(y,q,a)] , A(y,q,a) = logP_{\theta_1}+logP_{\theta_2}(a|y,q)-logQ_{\psi}(y|q,a)
为了减少训练时的方差,将A(y,q,a)进行标准化然后再减去基线模型b(.),基线模型b(.)也是从数据中训练得到的模型。