类不平衡问题Class imbalance

解决类不平衡的方法主要有三种,分别是欠采样,过采样和阈值移动(也叫调整权重),在介绍算法之前,我们先来感性的认识一下究竟什么是类不平衡。
用logistic regression举例,正样本的label是1,负样本的label是0,如果正负样本数量接近,我们认为若\frac{y}{1-y}>1,则样本为正例,反之则样本为反例。
我们为什么这么理解呢?
是因为我们之前假设了正负样本的数目是接近的,logistic regression回归的是x可能是正例的几率,那我们就可以理所当然的认为这个几率大于0.5就意味着x是正例,小于0.5就意味着x是反例。
但是,当正样本和负样本数目相差较大的时候就不可以这样认为了。
logistic regreesion得到的回归值 y 的具体含义,要看你是否做了无偏采样。
如果你的采样出现了人为因素的问题,例如实际上正样本和负样本是一样多的,但是你就是采样了10倍的正样本,一倍的负样本,那么y值的含义不变。
这意味着,如果你回归得到的y是大于0.5的,你依旧可以把x看作正例,反之是反例。
但是,如果你能确保你做的是无偏采样,那么你的y值的含义就需要调整了。
换句话说,y的含义是否改变取决于“类不平衡”是人家真的不平衡,还是你人为造成的不平衡。
为什么会出现这样的问题呢?
原因在于你训练的时候从来没有要求机器给你输出一个绝对可靠的概率,你没有要求机器让正例一定大于0.5,反例一定小于0.5,你只是要求机器把训练集中的正例学习为1,反例学习为0.
机器也确实尽可能按照这个要求输出回归值了,但是很难保证它们是以0.5为界的。
我这么说你可能还是很迷糊,我们来做一个实验。
首先是模拟有偏差的采样,正例和反例的分布分别在 (0,10) 和 (-10,0) 之间,但是正例有100个,反例只有10个。这样的采样可以看作有偏差的,因为正例和反例的密度严重不同(不是说它们的数量不同,数量不同没关系)。
x1 = np.random.rand(100)*10
x2 = np.random.rand(10)*10 - 10
y1 = np.ones(100)
y2 = np.zeros(10)
x = np.append(x1, x2).reshape(-1,1)
y = np.append(y1, y2).reshape(-1,1)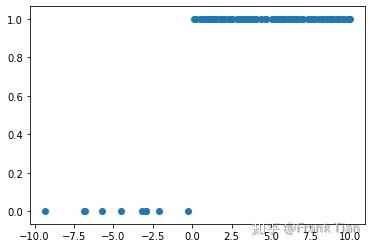
随便写一个logistic regression:
ones = np.ones(110).reshape(-1,1)
x = np.hstack((x,ones))
def sigmoid(inX):
return 1.0/(1+np.exp(-inX))
m = x.shape[0]
theta=np.mat(np.ones(2))
for i in range(100):
theta=theta-0.2/m*(sigmoid(x*theta.T)-y).T*x查看输出
y = sigmoid(x*theta.T)
print(y)你会发现它是以0.5为界的。
那么,如果你是无偏采样,正负样本真的不平衡呢?
我们把正例和反例的分布改成分别在 (0,100) 和 (-10,0) 之间,其他不变。这样正负样本的密度就相同了。
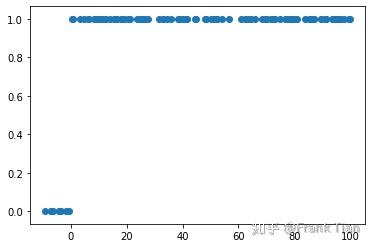
用同样的方法得到输出,你会发现有一些负样本的y值是大于0.5的。当然,当我把迭代次数改成1000后它们都小于0.5了。
尽管如此,你也可以发现在第二种情况中,负样本的y平均大于第一种情况。
也就是说,在这样的情况下,不应该在用0.5当作标准了。
实际上,分类的标准应该是 \frac{y}{1-y}>\frac{m^{+}}{m^{-}} ,其中 m^+ 代表正例的个数, m^- 代表反例的个数。
这意味着,当分类器的预测概率大于观测概率,我们就认为样本是正例的,反之则是反例。
当然前提还是你能保证在做无偏采样。
当然你也可以稍微修正一下你的y,这样你熟悉的0.5就回来了:
\frac{y^{\prime}}{1-y^{\prime}}=\frac{y}{1-y} \times \frac{m^{-}}{m^{+}}
上面的方法被称为rebalance。
除此之外,还有欠采样和过采样,我们分别介绍一下。
欠采样方法
欠采样就是把比较多的一类少采集一点,核心问题是怎么防止因为忽略了一些样本导致的信息缺失。
Tomek Links
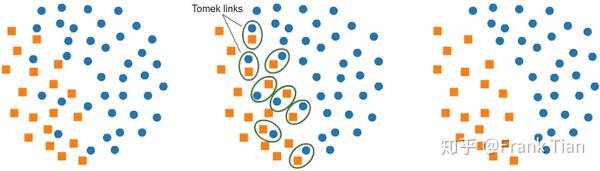
Tomek Links指的是,数据集中的两个样本彼此是对方的最近邻,同时他们的类别不同。
这时候我们可以删除两个点中,属于样本较多的那一类的那个点,这样能一定程度上减轻两类数据的不平衡。
Tomek Links的想法其实是,如果两个样本是Tomek Links的,那么分类器处理这两个样本的时候一定不太容易,那干脆删除一个减轻压力。
不过这个方法比较危险,毕竟这样很可能导致信息缺失。
至于如何找到最近邻的样本,有很多方法,比如说可以用KNN的k-d tree。(我乱讲的)
也可以把Tomek Links对应的两个样本都删除,用于数据清洗,当然和本节内容关系不大。
EasyEnsemble
EasyEnsemble是一种集成学习方法,用来解决类不平衡问题。
算法如下:


这个算法看起来挺简单,其实是有些说道的,比如最后的模型使用了所有的弱分类器集成,而不是使用adaboost集成。
EasyEnsemble比Tomek Links好在它不会丢失数据的信息,当然也相应提升了算法的复杂度。
Balance Cascade


我们简单对比一下Easy Ensemble和Balance Cascade的不同之处。首先Easy Ensemble虽然使用了级联的adaboost模型,但是最后分类的时候整个分类器是弱分类器们的并联。
但是Balance Cascade就不同了,它和GBDT这样的分类器更像,它是逐步的处理误分类的样本,从而提高准确率。
接下来是过采样的方法,主要是SMOTE,以及它的变体Borderline-SMOTE1&2,ADASYN和MAHAKIL。
SMOTE
SMOTE的全称是Synthetic Minority Over-sampling Technique,具体的算法是这样的:


看起来十分复杂,其实下面的图就可以体现算法的核心思想:
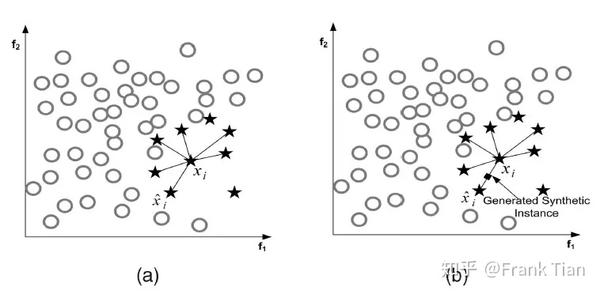

结合上面的图,SMOTE的想法就是,在少数类样本中选择一个样本 x_i ,得到它的K近邻,然后随机选择一个样本 \hat x_i ,在样本 x_i和样本 \hat x_i之间随机选择一个点,生成新的样本。直到总样本数达到要求的采样倍率N为止。
算法中有两个函数,一个是SMOTE,参数列表是一个三元组,一个是Populate,参数列表也是一个三元组。
值得注意的是在Populate函数中下面这句:
\begin{array}{l}{\text { Compute: } d i f=\text { Sample[nnarray[nn]][attr]-Sample[i][attr]}} \\ {\text { Compute: gap = random number between 0 and 1 }} \\ {\text { Synthetic [newindex][attr] = Sample[i][attr]+gap*dif}}\end{array}
注意是新样本的每一个attribute都是从 x_i 到 \hat x_i 之间的随机,而不是整体向量上的随机。
所以上图有点不准确,新的样本不一定在样本 x_i和样本 \hat x_i之间的直线上,而是可以在其作为顶点的超立方体上的任意一点。
但是好多国内的博客写的都是在两点之间的直线上选择一点,是我理解错了吗。。。有点慌。。。
Borderline-SMOTE1&2
就连这篇论文写SMOTE的方法都是“After that, new synthetic examples are generated along the line between the minority example and its selected nearest neighbors.”但是看SMOTE的伪代码,明明就是每个attr分别随机化啊。
Borderline-SMOTE是SMOTE的改进版本,核心思想是只过采样位于“边界线”上的少数类样本。这个算法是在2005年提出的。
与SMOTE只考虑了少数类样本不同,Borderline-SMOTE在KNN的时候还考虑了多数累样本,从而判断某一个样本的“类别”(这个“类别”不是指分类中的类别,而是“噪声”,“危险”,“安全”等)。
Borderline-SMOTE的算法如下 :


可以看出,Borderline-SMOTE在做KNN之前,先是根据“某一个少数类样本点周围样本的分布情况”进行了筛选。
如果周围全部是多数类,也就是反类,认为这个样本是噪声,不处理。
如果周围的反类超过半数,认为这个样本是边界样本,将这个样本加入集合DANGER中。
然后,对于每一个DANGER中的样本,在少数类样本中进行过采样。过采样的方法和SMOTE相同。
上面的算法被称为Borderline-SMOTE1,相应的还有Borderline-SMOTE2.
Borderline-SMOTE2的想法是不仅在少数类样本中KNN,还可以在边界样本和多数类样本(也就是它的负类)中采集样本进行过采样。
当然,新采集的样本应该离少数类样本更近一些,因此这个随机数不是在0到1之间的,而是在0到0.5之间的。
ADASYN
ADASYN的全称叫做adaptive synthetic sampling,也是SMOTE的一种改进方法。
ADASYN与Borderline-SMOTE相似,都是考虑了多数类样本的算法,同时ADASYN没有局限于“过采样一定要让少数类的数量和多数类相等”,而是设置了一个可以调节的超参数d,其实也就是一个阈值。




这个算法写的特别墨迹,其实想法很简单。
就是,现在不是要对每一个少数类的样本点做多采样嘛,然后采样的目的是让少数类和多数类更好的分开。
和Borderline-SMOTE的想法类似,ADASYN也认为所谓的边界点,也就是KNN时多数类比较多的点更需要过采样。然后ADASYN就搞出了一个分布,让那些边界点采样的数量多一点,中间点采样的数量少一点,因为中间点就算过采样了也没什么用,我们要时刻想着过采样的本质目的,不是机械的让少数类的个数和多数类相等,而是让分类更容易,更准确。
有了这个分布之后就不停的SMOTE直到多数类和少数类的比值达到阈值就好了。
MAHAKIL
MAHAKIL的名字可能来源于马氏距离Mahalanobis distance和一些不知道的什么单词组合。。。
其实MAHAKIL指出了SMOTE系列这种KNN算法的通病,一图以蔽之:
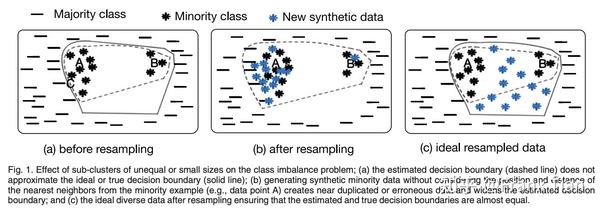
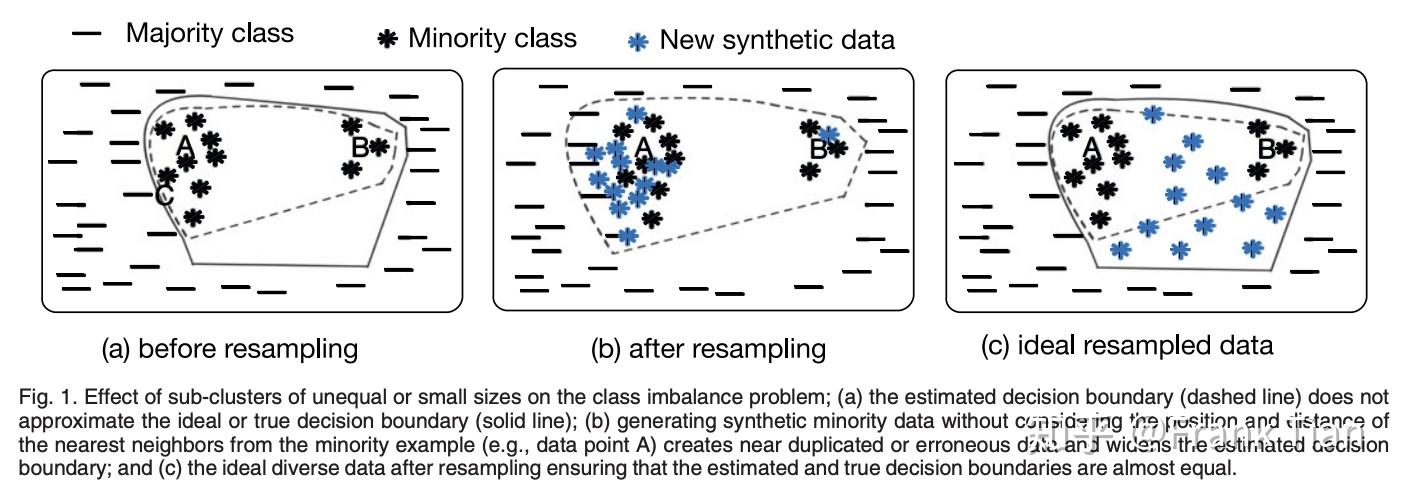
而在MAHAKIL中,算法通过通过模拟遗传学中的繁殖过程,来产生新的样本。作者认为这样的新样本能够具有原样本的更本质的特点。也就是立志于达到上图中图C的效果。
MAHAKIL算法的伪代码如下:


这个Pfp的全称是percentage of fault-prone,就是误判可能性比较大的占比,MAHAKIL的目的之一就是减小这个占比。
整个算法看起来复杂,其实流程还是比较简单的,主要分为三步:
- 将少数类样本从需要处理的数据集中分离出来,记为 bin ,对于 bin 中每一个少数类样本,计算其马氏距离。
- 按照马氏距离对 bin 排序,并将 bin 从序号中位数处一分为二,分别记为 bin1 、 bin2 。
- 分别依次成对地从 bin1 、 bin2 中选择数据样本,计算该对的均值,作为生成的新实例。
如果一轮下来生成新样本的个数不够 Pfp 的要求,则将新生成的样本 a 和它的父母 x,y 继续繁殖,如果还是不够,则由新新生成的两个样本 a',a'' 和它们分别的父母继续繁殖。
以此类推。
听起来比较乱伦,实际的流程图是这样的:


看这个图乱伦的流程就一目了然了。
这个算法用到了马氏距离,其实也是情理之中的,因为它需要判断两个样本之间的相似程度,既然数据集已经给定了,马氏距离肯定会比欧式距离更靠谱,比如消除了不同尺度和特征间关联的影响。
下面是参考论文,懒得按照格式写了,就直接给链接了。
周教授写的降采样的综述:
SMOTe:
Borderline-SMOTE:
MAHAKIL:
ADASYN:
