
多标签文本分类 | ALBERT+Seq2Seq+Attention 实战

欢迎咨询!
今天介绍一种新的用于多标签文本分类的框架:ALBERT+Seq2Seq+Attention,它是一种比较有意思的多标签文本分类框架。为什么这么说呢?因为在这个框架中,我们对标签的理解可能与在其他框架中的理解有点差异。在这个框架下,ALBERT只作为提取文本特征的工具,下游任务框架Seq2Seq+Attention会完成标签的抽取。
目的:觉得这种框架的设计思想比较有意思,以及与其他框架对比下实验效果。
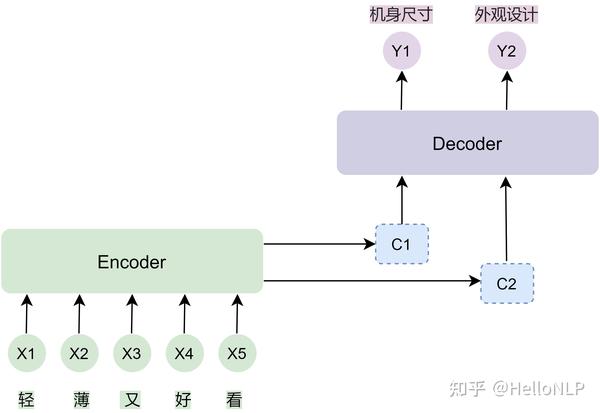

一. 简介
在电商评论中,用户的评论往往反馈了最真实的用户体验。如何从评论中提取用户的观点,成为了一件必不可少的工作。所以,为了解决这个问题,我们建立了一套标签体系,它可以反应绝大部分用户的声量。这套标签体系即为一个标签库,也是我们之后在标注和训练过程中需要使用到的标签。
1. 例子
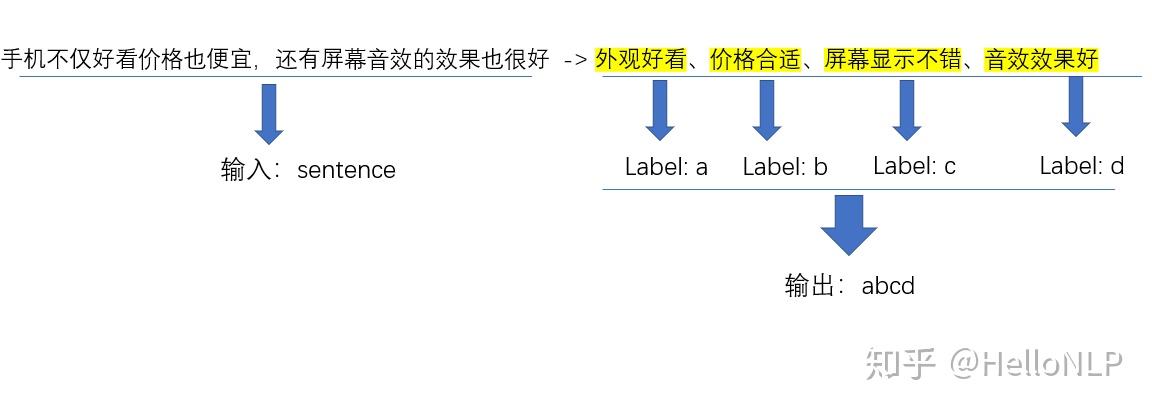
有一条评论:“手机不仅好看价格也便宜,还有屏幕音效的效果也很好 ”。我们从这评论中可以得知用户描述该产品的4个特征(标签):“外观好看”、“价格合适”、“屏幕显示不错”和“音效效果好”。

2. 标签理解
上面的例子中,a、b、c、d这4个标签组合在一起后的结果为"abcd",它可以被理解为一个句子,只不过它的颗粒度是一个标签,而不是我们平时理解的字或词。
在这里,我们对多标签的组合有了一个更深层的理解。将一个标签理解为一个token,多个标签的组合理解为一个query。这也是为什么之后要我们使用束搜索(Beam Search)的原因。
二、算法设计
1. Placeholder


首先,我们需要设置一些占位符(Placeholder),占位符的作用是在训练和推理的过程中feed模型需要的数据。我们这里需要4个占位符,分别是input_ids、input_masks、segment_ids和label_ids。前面3个是我们了解的BERT输入特征,最后面一个是标签的id。
2. ALBERT token-vectors
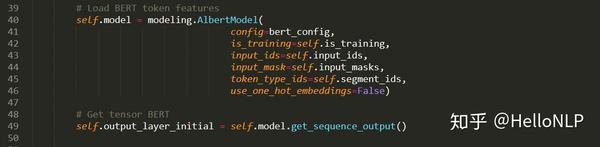

从图中可以看出,ALBERT需要传入3个参数(input_ids、input_masks、segment_ids),就可以得到我们所需要的一个3维向量output_layer_init:(batch_size, sequence_length, hidden_size),其中hidden_size为ALBERT中hidden_size的大小。之后,我们的下游任务(Downstream task)会使用这个vector,可以做一些自己感兴趣的任务,例如,我们即将要做的是一个多标签文本分类的任务。
3. Downstream task
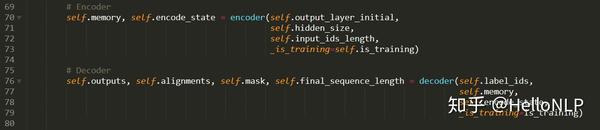

下游任务由2个部分组成,分别是encoder和docoder。其中,encoder部分由多层BiLSTM构成,decoder部分由多层LSTM的局部注意力机制(Local Attention)组成。由于encoder和decoder部分的代码太长,这里就不展示了。
另外,我们使用了局部注意力机制,主要为了突出临近标签之间的相互影响力。
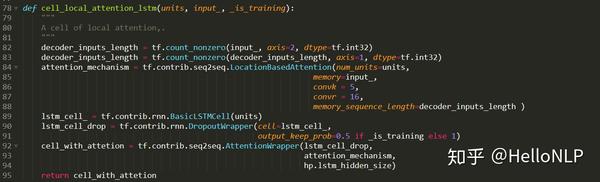

4. Cross-Entropy(交叉熵)


通常情况下,在文本分类中,我们使用的交叉熵为tf.nn.softmax_cross_entropy_with_logits;在多标签文本分类中,我们使用的交叉熵则为tf.nn.sigmoid_cross_entropy_with_logits。
但是,由于我们对标签的理解发生了变化,即逐一解码label,所以这里我们需要使用的是tf.nn.softmax_cross_entropy_with_logits。
5. Beam Search(束搜索)
可能有一部分会好奇,使用Beam Search的意义是什么。难道第一个标签的输出结果会影响第二个以及之后每一个标签的输出结果吗?是的,会影响。这也是之前为什么会提到将一个label理解为一个token,将多个label的组合理解为query。实验结果也证明,使用Beam Search确实会带来效果的提升。这种方法带来的效果在其他大部分多标签文本分类的框架上并不适用。
另外,Beam Search不参与训练,只在推理中使用。
6. Model Network
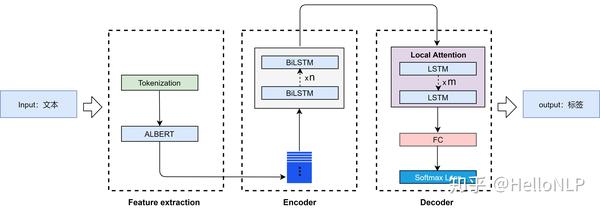

三、数据格式
1. 原始文本及标签形式
content = '手机不仅好看价格也便宜,还有屏幕音效的效果也很好 '
label = '外观好看/价格合适/屏幕显示不错/音效效果好'
2. one-hot向量
和传统的多标签文本分类的输入不一样,这里不是转为由0和1组成的one-hot向量。而是类似字典的形式,通过标签的指针,找到每一个标签对应的id。其中,在字典中可以找到,外观好看、价格合适、屏幕显示不错、音效效果好的id分别为22、3、87、54,那么这个one-hot向量即为:
label(one-hot): 22 3 87 54
3. 评估方法
四、实践及框架图
1、Tensorflow框架图
由于标签较多,所以框架图看起来会有点模糊。

2、模型Loss和Accuracy变化曲线图
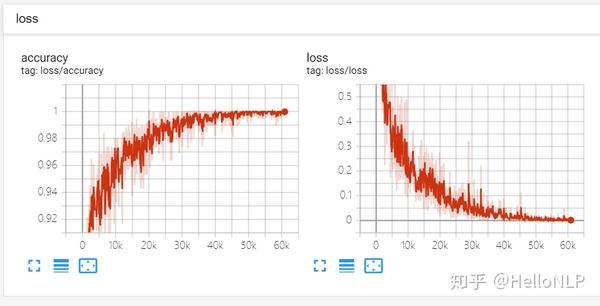

从图中可以看出,loss图像和accuracy图像都比较正常。
五. 代码链接
Github 链接:
