语音识别如何利用半监督学习?

本文是Google语音团队于2020年10月发表的《Improved Noisy Student Training for Automatic Speech Recognition》,是当前半监督学习领域最新的进展之一,基于此文而来的《Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition》获得了LibriSpeech 上最好的效果,今天先分享Noisy Student Training。
1. 摘要
近年来,被称为Noisy Student Training(NST)的半监督学习方法在图像识别领域取得了不错的效果,它是一种利用数据增强提高网络性能的迭代自训练方法。本文采用增强的SpecAugment方法,将NST应用于语音识别领域。通过本文的方法,采用LibriSpeech中100h的有监督数据和860h的无监督数据,最终在LibriSpeech clean/noisy数据集上获得了4.2%/8.6%的WER,此外,如果用LibriLight的unlab-60k数据集作为无监督数据,WER可以进一步降低到1.7%/3.4%。
2. Noisy Student Training for ASR
Noisy Student Training(NST)是一个自迭代的过程,通常会训练一系列的模型,用前面训练的模型处理未标注的数据,得到对应的标签后用来训练后面的模型。
本文中,假设有一个已标注的数据集S,一个未标注的数据集U,一个在其他预料上训练的语言模型LM,然后ASR的中的NST训练过程如下:
在已标注数据集S上,应用SpecAugment训练初始模型 M_0 ,令 M=M_0 ;
将M与语言模型LM融合,并评估模型效果;
用融合后的模型生成带标注的数据集 M(U) ;
过滤生成的M(U) 得到 f(M(U)) ;
采用一定的均衡策略过滤 f(M(U)) 数据得到 b\cdot f(M(U)) ;
将 b\cdot f(M(U)) 和S混合,用混合后的新数据集,应用SpecAugment训练模型 M' ;
令M=M' ,重复执行第2到7步。
以上过程执行一次认为训练了一代模型,上述中的 b\cdot f(M(U)) 数据集就是半监督训练的部分,接下来详细描述各部分的细节。
SpecAugment:本文中NST的每一步都应用了SpecAugment,这里采用了自适应的时域mask方法,mask的长度根据输入长度动态线性调整。
Language Model Fusion:为了给Student生成更好的数据,这里用Teacher模型和特定语料上训练的LM进行了浅融合。像LAS模型一样,这里在计算融合分的时候引入了一个覆盖惩罚项(coverage penalty term)c,同时用一个非空的常量 \rho 来增大LM模型的影响。以上参数在每轮训练中都会通过grid search方法更新,更新策略是使WER在dev-set数据集最小。
Filtering:如果没有一个直观的诸如对数概率这样的数值来评价生成数据集,很难直观判断Teacher模型生成的数据集好坏。本文中提出了一种得分公式,这里以S表示融合得分,L表示Teacher模型生成的数据集数量,归一化的得分计算如下所示:
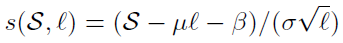
式中 \mu,\beta,\sigma 都是在开发集上训练而来, \mu,\beta 是通过线性回归对 (l_i,S_i)进行拟合, \sigma 是对应的标准差,所有参数在每轮训练中都会根据新的Teacher模型更新。
通过上面得分,可以有选择的找出模型生成的数据,再通过设置过滤截止值 S_{cutoff} ,在每一轮训练中只保留超过阈值的部分,这个策略在实际NST训练中效果明显。
Balancing:通过 f(M(U)) 生成的数据集上的tokens分布,同原始的有监督数据集有很大差异,这里通过在数据集上对样本进行均衡来弥补这个差距。
具体来说是通过“cost-benefit score”的子模块采样来平衡数据集,它是一种通过在备选池中挑选替换某些样本来使生成数据分别接近目标数据集的方法,采用贪婪计算的策略优化生成集和目标集的KL散度。此外,还增加了额外的约束,将一个句子的抽样次数上限设为2,并要求生成集中的Token总数与监督集的Token总数一致。
Mixing:文中将生成数据集和有监督数据集混合使用,在batch级别的混合中,混合率会在每个batch进行调整,在非batch级别混合中,数据在两个数据集中均匀采样。
3. 实验
3.1. LibriSpeech 100-860
LibriSpeech 100-860是将100小时干净的子集作为有监督数据,860小时数据作为无监督数据而来的半监督数据集。通过WPM模型在完整的100小时子集上以16k词汇量构建了抄本文件。训练中采用了80维带一阶差分和二阶差分的Fbank作为输入,声学模型采用了LAS-6-1280,其中encoder是一个双向LSTM。
共训练了六代模型,编号为0-5,其中0号表示使用有监督数据训练的模型。训练中采用Adam迭代器,学习率设为0.001,batch_size设为512,每一代模型在32个Google Cloud TPU上训练了十天。LM融合所用的checkpoint是根据其开发集WER来定的。具体细节如下:
SpecAugment:对于0号模型,频域maskF=27,两个时域mask T=40,时域变换参数W=40。在2-4号模型,重新优化了时域mask参数T。四个模型上,时域mask的参数分别是:0号为40,1、2号是80,5号是100。
LM:采用了三层带4096个节点的LSTM语言模型,在LibriSpeech LM corpus上训练而来,LM在开发集上的的词级困惑度为63.9。
Filtering:在1到5号模型上filter得分分别设置为 \{1,0.5,0,-1,-\infty \} ,对于clean-360h和other-500h数据集分开处理,具体来说是dev-clean上的得分系数应用于clean-360h,在dev-other上得到的参数应用于other-500h。
Other:balancing和batch-wise混合都没使用。
各代模型测试结果如下:
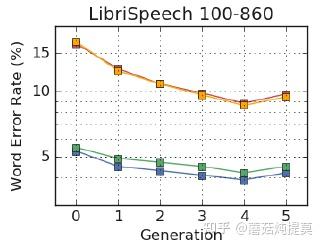
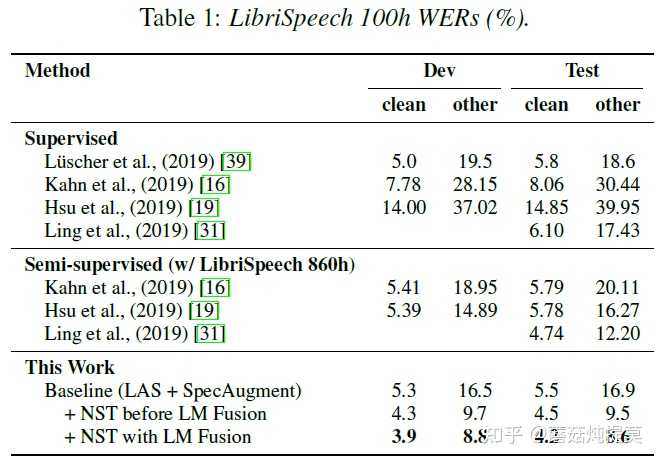
图中可以看到,最好的模型是4号模型,下图单独对比4号模型和baseline的效果

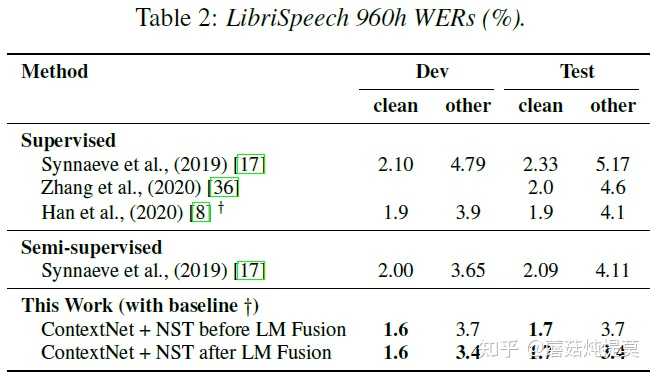
3.2. LibriSpeech-LibriLight
本实验用所有的LibriSpeech训练集作有监督数据,LibriLight的“unlab-60k”子集是电子书音频收集而来,用它作无监督数据。接着将所有的音频进行切分,最大长度为36s,然后进一步选择了总长少于22s的音频,这一步大概产生了一百万个音频。
实验中采用80维的fbank作为输入,模型采用ContextNets系列,它们是一种以CNN为encoder的RNNT模型,具体来说,模型有23个卷积组成的encoder,两层有1280个RNN单元组成的decoder,以及缩放因子w,将其记作CN-w。
同样训练了0-5号模型,0号的baseline ContextNet模型中,encoder是CN-2,decoder是只有一层640维的RNN。1-4号模型里,w分别是 \{ 1.25,1.75,2.25,2.5\} ,每一代模型在128个Google Cloud TPU上训练了三天。LM融合所用的checkpoint是根据其开发集WER来定的。具体细节如下:
SpecAugment:这里采用了自适应的时域mask方法,mask的长度根据输入长度动态线性调整,最大的mask ratio是0.05,没有用时域warping。
LM:采用了三层带4096个节点的LSTM语言模型,在LibriSpeech LM corpus和LibriSpeech 960h上训练而来,LM在开发集上的的词级困惑度为68.3。
Other:本实验中没有用filtering和balancing。但是用了在batch级别的混合,混合率会在每个batch进行调整,其中1、2号中有监督和无监督的比例是4:6,3号模型的比例是3:7,四号模型的比例是2:8。
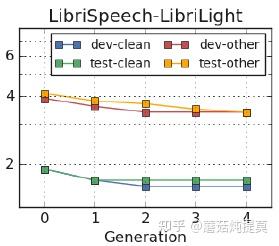
图中可以看到,最好的模型是4号模型,下图单独对比4号模型和baseline的效果:

4. 总结
本文提出将Noisy Student Training(NST)应用于ASR任务,并做了一些改进,包括增强的SpecAugment,LM模型融合,以及子模块抽样的方法当。同时还引入了一种归一化过滤评分,用于分级自我训练,该方法在对监督数据较少的LibriSpeech 100-860数据集有明显的提升,但是在更大的LibriSpeech-LibriLight数据集上效果不明显。以上各种组合统一提升了模型的效果,目前是两项任务上的最佳模型。