无监督高维空间嵌入向量对齐

Edouard Grave, Armand Joulin, Quentin Berthet:
Unsupervised Alignment of Embeddings with Wasserstein Procrustes. AISTATS 2019: 1880-1890
非常好的文章,但是数学太难了。。
在高维中对齐两组点的任务在自然语言处理和计算机视觉中有许多应用,比如说对齐多语言的单词,可以用来做翻译,如图所示


这种任务的标注数据一般都比较少,而且错误很多,文中举了一个例子是用字符串匹配,得到的数据就不是很靠谱。最近有一些无监督的方法,比如说把两个语言的数据看作是两个分布,用Wasserstein距离或对抗训练把问题转化为两个分布之间的距离最小化,但是总有一大堆缺点吧啦吧啦,比如说需要一些refinement procedure,训练不稳定,需要一个好的初始值等等。
背景知识
Procrustes
文章首先介绍了Procrustes analysis,主要是学习两个点集X和Y之间的一个线性变换,如果知道X到Y的一一对应关系,可以用最小二乘法解方程。
\min _{\mathbf{W} \in \mathbb{R}^{d} \times d}\|\mathbf{X} \mathbf{W}-\mathbf{Y}\|_{2}^{2}
如果对线性变换的矩阵W加一些约束会好一些,Xing提出了用正交变换实验效果会好点,Q代表一个正交矩阵,正交性约束可以确保通过变换不会改变点之间的距离。
\min _{\mathbf{Q} \in \mathcal{O}_{d}}\|\mathbf{X} \mathbf{Q}-\mathbf{Y}\|_{2}^{2}
这个正交矩阵有解析解为 \mathbf{Q}^{*}=\mathbf{U V}^{\top} ,其中 \mathbf{U S V}^{\top} 是 \mathbf{X}^{\top} \mathbf{Y} 的SVD分解。
Wasserstein距离
同时如果X到Y的一一对应已知的话,这个一一对应可以表示为一个置换矩阵P,也就是每一行和每一列都恰好有一个1,其他元素都是0,就可以优化这么一个问题
\min _{\mathbf{P} \in \mathcal{P}_{n}}\|\mathbf{X}-\mathbf{P} \mathbf{Y}\|_{2}^{2}
这里把上面的二范数展开,每一项相当于 ||x_i-y_j||_2^2= x_i^2+y_j^2-2x_iy_j ,前两项求和就是 ||X||_2^2+||Y||_2^2 ,是一个常数,把后面的 -2x_iy_j 取最小值变成取最大值,就变成了下面这个形式
\max _{\mathbf{P} \in \mathcal{P}_{n}} \operatorname{tr}\left(\mathbf{X}^{\top} \mathbf{P} \mathbf{Y}\right)=\max _{\mathbf{P} \in \mathcal{P}_{n}} \operatorname{tr}\left(\mathbf{P} \mathbf{Y} \mathbf{X}^{\top}\right)
相当于求解一个最佳分配问题,这里可以感性的认识一下,X和Y是两个矩阵,也就是两个向量的表格,把X中每个向量对齐到Y中的一个向量,相当于一个二分图匹配问题,其中每个 x_i 到 y_j 都有一条边,cost为 ||x_i-y_j||_2^2
这个问题可以用 O\left(n^{3}\right) 的匈牙利算法求解,但是太慢了,可以用一些近似求解的方法,Zhang等人优化了一个Wasserstein距离:
W_{2}^{2}(\mathbf{X}, \mathbf{Y})=\min _{\mathbf{P} \in \mathcal{P}_{n}} \sum_{i, j} P_{i j}\left\|\mathbf{x}_{i}-\mathbf{y}_{j}\right\|_{2}^{2}
本文方法
本文要做一个无监督的对齐方法,所以并不知道X到Y的一一对应关系P,也不知道两个分布之间的变换Q,所以本文提出了,同时学习这两个P和Q,也就是优化下面这个公式
\min _{\mathbf{Q} \in \mathcal{O}_{d}} W_{2}^{2}(\mathbf{X Q}, \mathbf{Y})=\min _{\mathbf{Q} \in \mathcal{O}_{d}} \min _{\mathbf{P} \in \mathcal{P}_{n}}\|\mathbf{X} \mathbf{Q}-\mathbf{P} \mathbf{Y}\|_{2}^{2}
这个方法有两个问题
- 求解起来复杂度比较高
- 在同时求P和Q时是非凸的,容易陷入局部最优
Stochastic optimization
这个章节主要是优化它的速度问题,直接求解上面的式子有个拿衣服的方法,就是固定Q找一个最优的置换矩阵P,求MSE之后再对Q梯度下降,但是找P这个过程复杂度很大,如果样本数太多的话不现实,文中的做法就是分了个batch,每次优化一个batch的\left\|\mathbf{X}_{t} \mathbf{Q}-\mathbf{P}_{t} \mathbf{Y}\right\|_{2}^{2}
讲了好久,而且写得很绕,但是直观上感觉就是把X和Y分了几个mini batch然后用SGD优化,整个算法过程如下,为了保证Q是正交的,更新Q的梯度的时候会用SVD把它映射到一个正交矩阵上。


Convex relaxation
上个章节解决了速度问题但是依然没有解决优化目标非凸的问题,这部分要找到一个好的起始点,内容逐渐天书起来。。上个章节解决了速度问题但是依然没有解决优化目标非凸的问题,这部分要找到一个好的起始点开始迭代,内容逐渐天书起来。。
原始问题是要求
\max _{\mathbf{P} \in \mathcal{P}_{n}} \max _{\mathbf{Q} \in \mathcal{O}_{d}} \operatorname{tr}\left(\mathbf{Q}^{\top} \mathbf{X}^{\top} \mathbf{P} \mathbf{Y}\right)
这里为啥也没看明白。。但是作者认为Q的最大值应该和 \max _{\mathbf{P} \in \mathcal{P}_{n}}\left\|\mathbf{X}^{\top} \mathbf{P} \mathbf{Y}\right\|_{*} 等价,其中 \mathbf{Z} \mapsto\|\mathbf{Z}\|_{*} 是核范数,但是作者说这个算起来太复杂了,所以就用F范数替代,得到了下面的公式
\max _{\mathbf{P} \in \mathcal{P}_{n}}\left\|\mathbf{X}^{\top} \mathbf{P} \mathbf{Y}\right\|_{2}^{2}=\max _{\mathbf{P} \in \mathcal{P}_{n}} \operatorname{tr}\left(\mathbf{K}_{\mathbf{Y}} \mathbf{P}^{\top} \mathbf{K}_{\mathbf{X}} \mathbf{P}\right)
其中 \mathbf{K}_{\mathbf{X}}=\mathbf{X} \mathbf{X}^{\top} \text { } \mathbf{K}_{\mathbf{Y}}=\mathbf{Y} \mathbf{Y}^{\top}
也就是一个二次分配问题,或者说是两个完全图的图同构问题,这是一个NP问题但是有很多优化算法,Gold等人提出了把其中的P从置换矩阵换成双随机矩阵,作者认为它是置换矩阵集合的凸包,经过这个再用Frank等人提出的优化算法,可以得到一个全局最优的 \mathbf{P}^{*} ,之后根据这个P求Q的初始值
\mathbf{Q}_{0}=\underset{\mathbf{Q} \in \mathcal{O}_{d}}{\operatorname{argmin}}\left\|\mathbf{X Q}-\mathbf{P}^{*} \mathbf{Y}\right\|_{2}^{2}
NN搜索
把X的嵌入向量映射到Y之后需要使用NN搜索找到每个 x_i 对应最近的 y_j ,但是一些研究指出,有一些叫hubs的点会与很多个点近似,NN搜索会倾向选出这些hubs,这是不符合预期的。文中又提了另外两个找最近点的方法,分别是ISF和CSLS
\operatorname{ISF}(\mathbf{y}, \mathbf{z})=\frac{\exp \left(\beta \mathbf{y}^{\top} \mathbf{z}\right)}{\sum_{\mathbf{y}^{\prime} \in \mathbf{Y}} \exp \left(\beta \mathbf{y}^{\prime \top} \mathbf{z}\right)}
\operatorname{CSLS}(\mathbf{y}, \mathbf{z})=2 \cos (\mathbf{y}, \mathbf{z})-R_{\mathbf{Z}}(\mathbf{y})-R_{\mathbf{Y}}(\mathbf{z})
其中 R_{\mathbf{Z}}(\mathbf{y})=\frac{1}{K} \sum_{\mathbf{z} \in \mathcal{N}_{Z}(\mathbf{y})} \cos (\mathbf{z}, \mathbf{y})
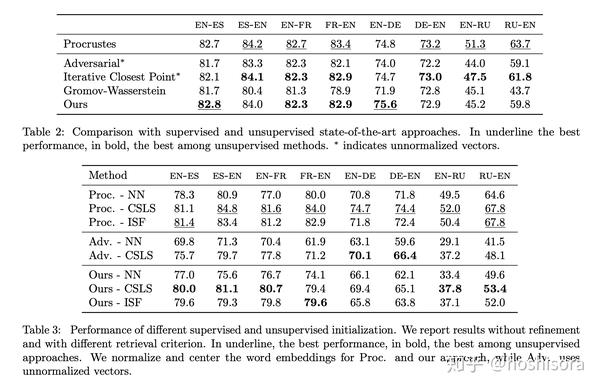
实验
结果如下

总结
本文提供了一个非监督学习两组嵌入向量的对齐方法,虽然数学看不懂但是有一点挺有意思,就是它把嵌入向量的对齐转化为了完全图的匹配问题,这点值得继续探讨。
