

CornerNet 算法笔记
论文名称:CornerNet: Detecting Objects as Paired Keypoints
论文链接:https://arxiv.org/abs/1808.01244
代码链接:https://github.com/princeton-vl/CornerNet
简介
这篇文章是ECCV2018的一篇目标检测论文,该论文的创新之处在于使用Keypoints代替原来的anchor思想进行目标检测,提出检测目标左上点和右下点来确定一个边界框,提出一个新的池化方法:corner pooling,在mscoco数据集上达到42.2%的ap,精度上是当时的单阶段目标检测器的state of the art,但是速度略慢,大约1fps(论文为Titan X 244ms/f),无法满足工程需求。
相对于基于anchor检测器创新意义有:
- anchor数量巨大,造成训练正负样本不均衡(anchor机制解决方式为难例挖掘,比如ohem,focal loss)
- anchor超参巨多,数量,大小,宽高比等等(比如yolo多尺度聚类anchor,ssd的多尺度aspect ratio)
算法整体架构
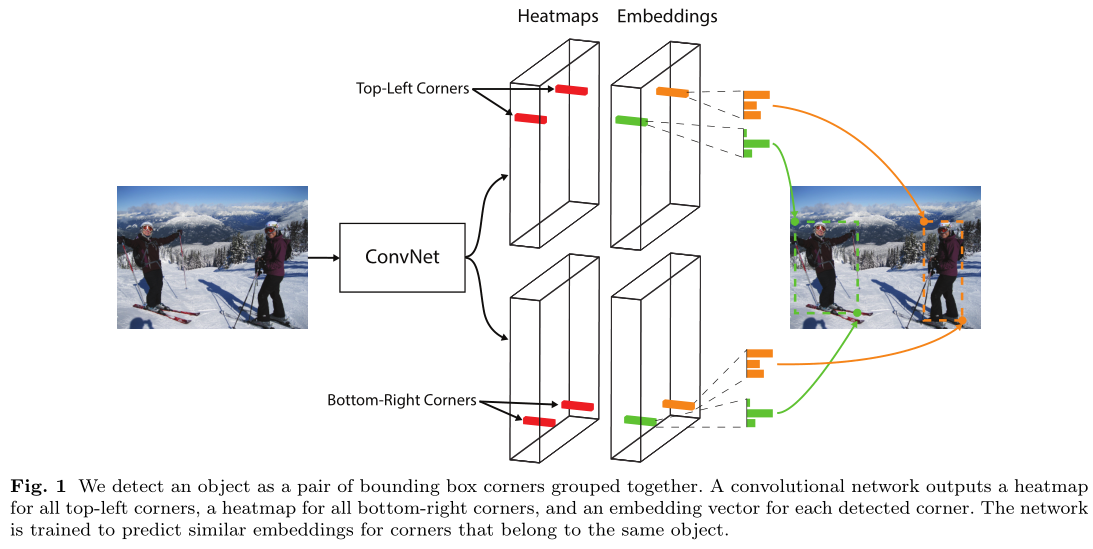
如上图fig1,经过特征提取主干网络(主干网络为Hourglass-104)后分为两个分支(两个分支分别接前面提到的corner pooling,随后细谈),一个分支生成目标左上点热力图,一个分支生成目标右下点热力图,而此时两个热力图并没有建立联系,因此无法确定两点是够属于同一目标,因此两分支同时生成embeddings,通过判断两个embedding vector的相似性确定同一物体(距离小于某一阈值则划为同一目标)。

如上图fig4,图片首先经过1个7×7的卷积层将输入图像尺寸缩小为原来的1/4(论文中输入图像大小是511×511,缩小后得到128×128大小的输出)。
然后经过hourglass-104提取特征,该网络通过串联多个hourglass module组成(Figure4中的hourglass network由2个hourglass module组成),每个hourglass module都是先通过一系列的降采样操作缩小输入的大小,然后通过上采样恢复到输入图像大小,因此该部分的输出特征图大小还是128×128,整个hourglass network的深度是104层。
hourglass module后会有两个输出分支模块,分别表示左上角点预测分支和右下角点预测分支,每个分支模块包含一个corner pooling层和3个输出:heatmaps、embeddings和offsets。heatmaps是输出预测角点信息,可以用维度为CHW的特征图表示,其中C表示目标的类别(无背景类),每个点的预测值为0到1,表示该点是角点的分数;embeddings用来找到属于同一个目标的左上角角点和右下角角点;offsets用来对预测框做微调,与anchor机制中的offset有区别,前者用来微调特征图映射回原图后的取整量化误差,后者用来表示ground true与anchor的偏移。
Headmaps
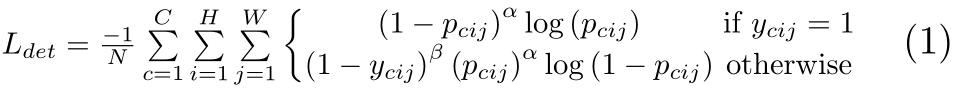
CornerNet的第一个输出headmap用来预测角点的位置。公式(1)是针对角点预测(headmaps)的损失函数,是修改后的focal loss。
pcij表示预测的heatmaps在第c个通道(类别c)的(i,j)位置的值,ycij表示对应位置的ground truth,N表示目标的数量。ycij=1时候的损失函数容易理解,就是focal loss,α参数用来控制难易分类样本的损失权重;ycij等于其他值时表示(i,j)点不是类别c的目标角点,照理说此时ycij应该是0(大部分算法都是这样处理的),但是这里ycij不是0,而是用基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的ycij值接近1,这部分通过β参数控制权重,这是和focal loss的差别。因为靠近ground truth的误检角点组成的预测框仍会和ground truth有较大的重叠面积,如下图所示,红色实线框是ground truth;橘色圆圈是根据ground truth的左上角角点、右下角角点和设定的半径值画出来的,半径是根据圆圈内的角点组成的框和ground truth的IOU值大于0.7而设定的,圆圈内的点的数值是以圆心往外呈二维的高斯分布;白色虚线是一个预测框,可以看出这个预测框的两个角点和ground truth并不重合,但是该预测框基本框住了目标,因此是有用的预测框,所以要有一定权重的损失返回,这就是为什么要对不同负样本点的损失函数采取不同权重值的原因。

Embeddings
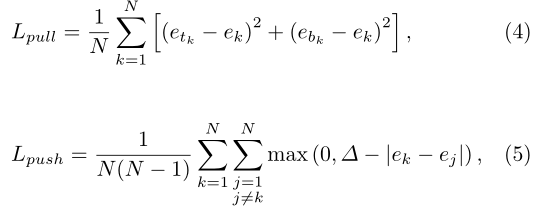
CornerNet的第二个输出是embeddings,对应文章中group corner的内容。前面介绍了关于角点的检测,在那部分中对角点的预测都是独立的,不涉及一个目标的一对角点的概念,因此如何找到一个目标的两个角点就是第三个输出embedding做的工作。这部分是受associative embedding那篇文章的启发,简而言之就是基于不同角点的embedding vector之间的距离找到每个目标的一对角点,如果一个左上角角点和一个右下角角点属于同一个目标,那么二者的embedding vector之间的距离应该很小。
embedding这部分的训练是通过两个损失函数实现的,etk表示属于k类目标的左上角角点的embedding vector,ebk表示属于k类目标的右下角角点的embedding vector,ek表示etk和ebk的均值。公式(4)用来缩小属于同一个目标(k类目标)的两个角点的embedding vector(etk和ebk)距离。公式(5)用来扩大不属于同一个目标的两个角点的embedding vector距离。
Offsets
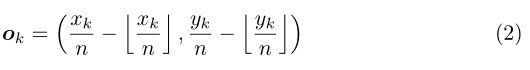
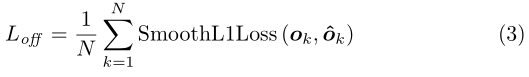
CornerNet的第三个输出是offset,这个值和目标检测算法中预测的offset类似却完全不一样,说类似是因为都是偏置信息,说不一样是因为在目标检测算法中预测的offset是表示预测框和anchor之间的偏置,而这里的offset是表示在取整计算时丢失的精度信息,如上式(2),其中(xk,yk)表示第k个角点的原图坐标值,n代表下采样因子,ok表示特征图缩放回原图后与原gt框的精度损失。然后通过公式(3)的smooth L1损失函数监督学习该参数,和常见的目标检测算法中的回归支路类似。
Corner pooling
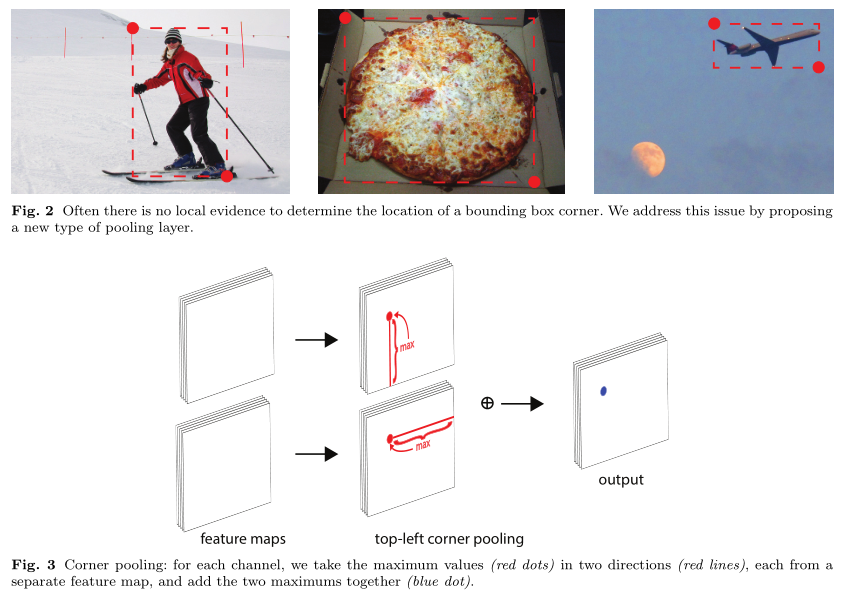
CornerNet是预测左上角和右下角两个角点,但是这两个角点在不同目标上没有相同规律可循,如果采用普通池化操作,那么在训练预测角点支路时会比较困难。作者认为左上角角点的右边有目标顶端的特征信息(第一张图的头顶),左上角角点的下边有目标左侧的特征信息(第一张图的手),因此如果左上角角点经过池化操作后能有这两个信息,那么就有利于该点的预测。Figure3是针对左上角点做corner pooling的示意图,该层有2个输入特征图,特征图的宽高分别用W和H表示,假设接下来要对图中红色点(坐标假设是(i,j))做corner pooling,那么就计算(i,j)到(i,H)的最大值(对应Figure3上面第二个图),类似于找到Figure2中第一张图的左侧手信息;同时计算(i,j)到(W,j)的最大值(对应Figure3下面第二个图),类似于找到Figure2中第一张图的头顶信息,然后将这两个最大值相加得到(i,j)点的值(对应Figure3最后一个图的蓝色点)。右下角点的corner pooling操作类似,只不过计算最大值变成从(0,j)到(i,j)和从(i,0)到(i,j)。

Figure6也是针对左上角点做corner pooling的示意图,是Figure3的具体数值计算例子,该图一共计算了4个点的corner pooling结果。
Prediction module
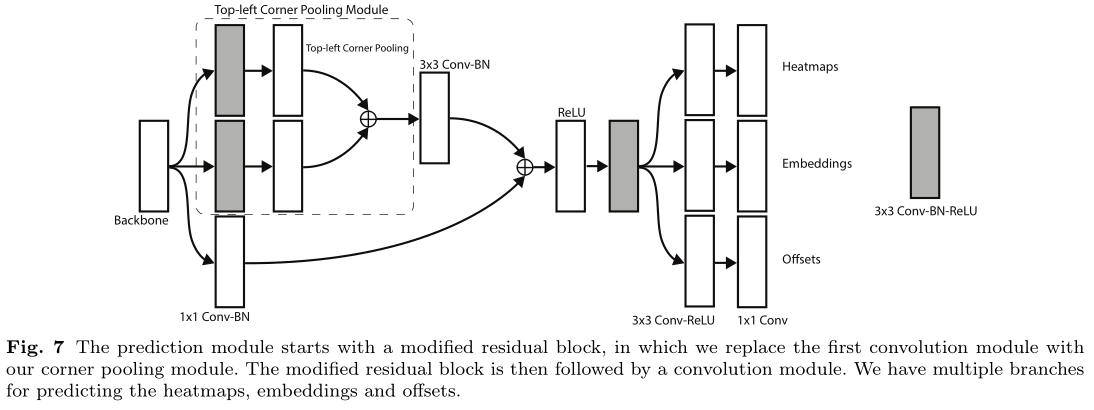
Figure7是Figure4中预测模块的详细结构,该结构包括corner pooling模块和预测输出模块两部分,corner pooling模块采用了类似residual block的形式,有一个skip connection,虚线框部分执行的就是corner pooling操作,也就是Figure6的操作。
Loss function
![]()
Ldet为角点损失,Lpull、Lpush为embedding损失,Loff为offset损失
其中α为0.1,β为0.1,γ为1,损失函数优化方式为Adam
Testing details
1、在得到预测角点后,会对这些角点做NMS操作,选择前100个左上角角点和100个右下角角点。
2、计算左上角和右下角角点的embedding vector的距离时采用L1范数,距离大于0.5或者两个点来自不同类别的目标的都不能构成一对,检测分数是两个角点的平均分数。
3、测试图像采用0值填充方式得到指定大小作为网络的输入,而不是采用resize,另外同时测试图像的水平翻转图并融合二者的结果。
4、最后通过soft-nms操作去除冗余框,只保留前100个预测框。
Eexperiment

上表Table1是关于是否添加corner pooling的消融实验,可以看出第二行(添加)提升效果明显,尤其在大目标上

上表Table2是关于不同位置负样本采取不同权重的损失函数的效果,第一行为无惩罚减少机制,第二行为固定半径,第三行为采用目标计算得到的半径值,效果提升明显,尤其是在中、大目标上。
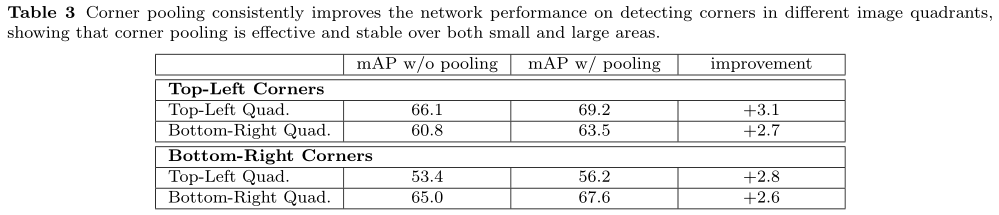
上表Table3是关于corner pooling分别对左上角点预测和右下角点预测的影响。

上表Table4是关于主干网络选择的消融实验,该实验分别以fpn为主干网络+corner检测方式,hourglass-104为主干网络+anchor检测方式,hourglass-104为主干网络+corner检测方式,最后说明本文组合方式效果最佳。

上表Table5将cornernet分别与RetinaNet、Cascade R-CNN、IoU-Net在高iou阈值下进行ap对比,证明“好的检测期的边界框与gt更贴近”

上表Table6错误分析。第一行是这篇文章的算法结果;第二行是将角点预测结果用ground truth代替,可以看到提升非常大;第三行是进一步将偏置用ground truth代替,相比之下提升会小很多。这说明目前该算法的瓶颈主要在于角点预测。
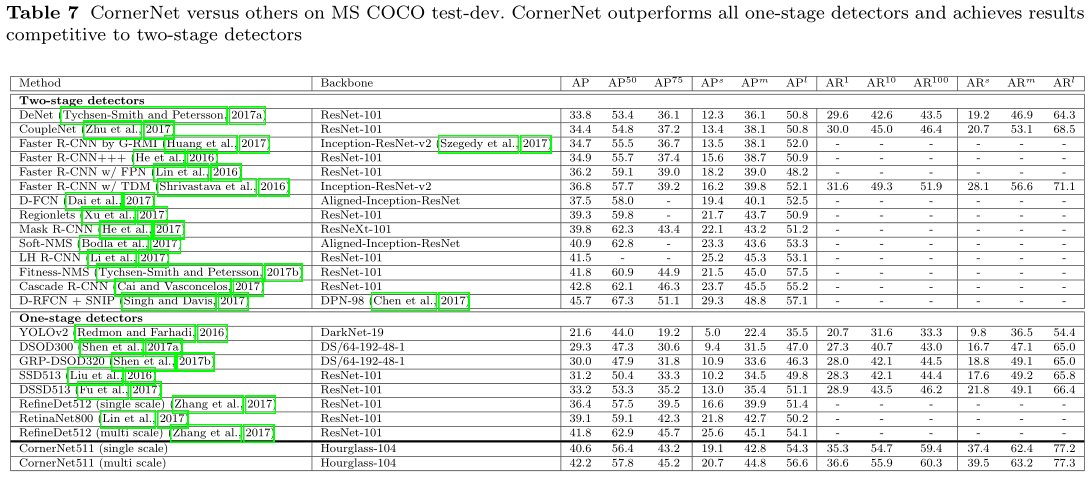
上表Table7是connerNet和其他优秀目标检测算法的效果对比。
总结
本论文主要提出使用一对关键点(左上角点,右下角点)进行目标检测,并取得非常好的检测精度,由此掀起anchor-free热潮,博主在写此篇博文时cornernet已经被deprecated,取而代之的还是普林斯顿大学团队提出的cornernet-lite(https://arxiv.org/abs/1904.08900),该论文在速度和精度上均对cornernet进行提升,另一篇同期论文(2019.04)centernet(https://arxiv.org/abs/1904.08189)提出Keypoint Triplets思想也对cornernet进行优化,达到目前单阶段目标检测器最高精度(47.0%)。接下来我将对以上两篇论文进行总结,并有可能分析cornernet系列的源码实现细节。本文参考:https://blog.csdn.net/u014380165/article/details/83032273

