
近期任务型对话系统综述以及百度UNIT,理论和实践,我全都要!(手动鳌拜)

笔者近期阅读了新加坡南洋理工大学的最新对话系统综述《Recent Advances in Deep Learning-based Dialogue Systems 》,该综述包括7个部分,如图1所示。下面笔者就对其任务型对话的一些模型进行自己的一些分享,文章会比较长。如果说想通过本文了解最新的对话系统模型,那么你可能会有些失望,因为本文并没有涉及到近期非常非常前排的一些对话模型。这篇文章更多的是以循序渐进的方式对当前任务型对话进行一些解读,希望以这样的方式来夯实任务型对话的基本概念以及引发对任务型对话实际落地的些许思考。

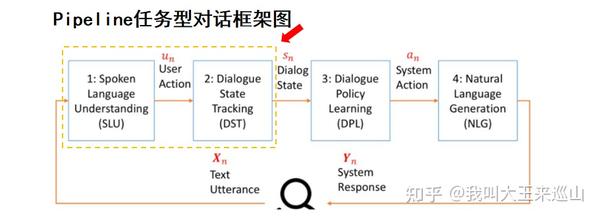
任务型对话系统的核心主要包括 Natural Language Understanding (NLU),Dialogue State Tracking (DST),Dialogue Policy Learning(DPL)等3个部分。对于任务型对话,概念理解很重要,因此本文会首先以一个简单的例子介绍任务型对话的基本概念,除了对模型的介绍,本文管中窥豹,将以百度UNIT的Task Flow为例,看业务中的多轮对话是如何落地和发展。
目录
一、Task-oriented Dialogue Systems Introduction
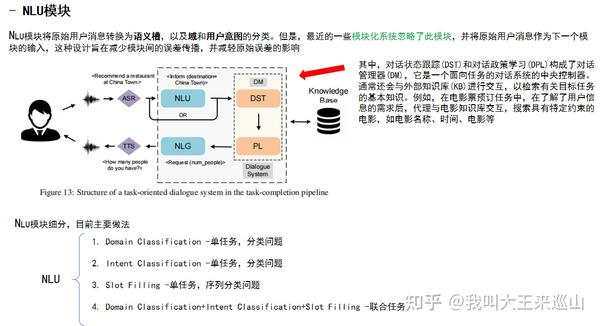
二、Natural Language Understanding (NLU)
三、Dialogue State Tracking (DST)
四、Dialogue Policy Learning(DPL)
五、BAIDU UNIT
六、Conclusion
一、Task-oriented Dialogue Systems Introduction
任务型对话从架构上来讲,主要分为2大部分,一部分是 modular systems;另一部分是 end-to-end systems


下面对 modular systems 进行介绍,首先将会对NLU, DST, DPL, NLG进行基本定义,四个部分的建模通用公式【10】如下所示:





单说公式会比较枯燥,为了在抽象的建模的基础上加深理解,下面以一个“ 饮料下单”的小例子来看这些公式在实际应用中各自承担的作用。




二、Natural Language Understanding (NLU)
个人认为NLU部分在对话系统地位很高,同时也是最好落地的部分,因此本文将会挑选1篇经典的文章以及4篇前沿的文章来看当前NLU的一些工作


NLU主要分为意图识别和槽填充2部分,即可以是2个单任务,也可以是1个联合任务,当然,联合任务的数据集可遇不可求。

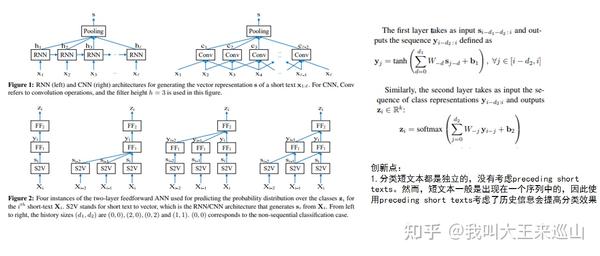
1.《Sequential Short-Text Classification with Recurrent and Convolutional Neural Network,NAACL-HLT 2016》【1】
这篇文章提出了几种融合历史对话的方式,在当时是一篇比较有创意的文章。其中,d1=n,代表在第一层ANN中有n段历史对话文本;d2同理,具体参考上图的Figure2。

2. 《TOD-BERT:Pre-trained natural language understanding for task-oriented dialogues, EMNLP 2020》【2】
这篇文章利用任务型对话语料进行训练BERT,得到了TOD-BERT,在任务导向型对话的下游四个任务中都取得了超越当前SOTA的效果。其中包括,IR(意图识别),DST(对话状态追踪),DAP(对话行为预测),RS(响应选择)
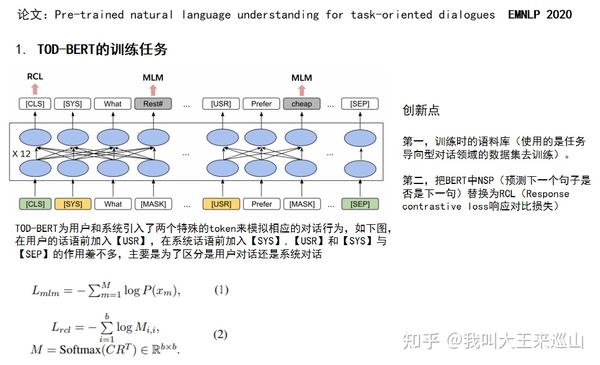
TOD-BERT模型采用MLM和RCL两个任务进行模型预训练,其中MLM与原生BERT保持一致,下面重点讲解一下RCL,RCL借鉴了下面要讲的ConveRT【3】的预训练任务,两者均为Response Selection,模型采用双塔结构。仔细来看,两者均采用Response Selection作为语言模型预训练任务,而两者采用的损失函数却不相同,TOD-BERT的RCL本质上是一个多分类任务,而ConveRT所采用的损失则是类似于Hinge Loss。


下面介绍一下TOD-BERT在下游任务的应用以及模型对应的输入输出




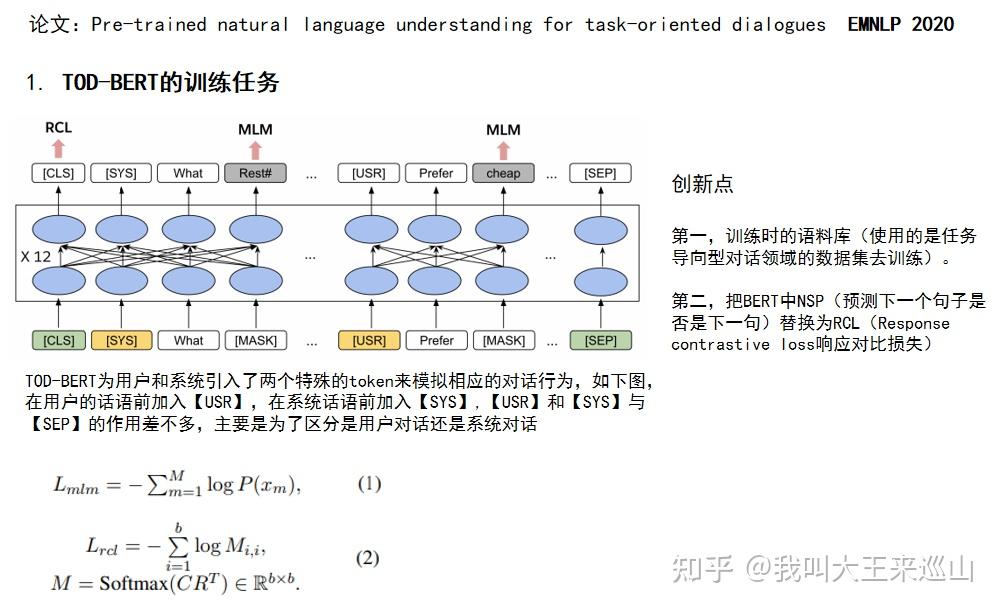
3. 《ConveRT: Efficient and Accurate Conversational Representations from Transformers, EMNLP 2020》【3】
- 论文动机
第一,数据决定模型效果,要想在具体任务上使用预训练语言模型并得到突出的效果,应该尝试用该任务领域的数据集进行预训练,而BERT模型并没有特意针对任务导向型对话领域的数据集进行预训练。
第二,Response Selection任务一般会用两个编码器(dual-encoder)进行编码,而BERT过于笨重,不符合实际使用
- 创新点
第一,训练思想对标BERT,将特定域的Conversational Learning任务简化为一般域的Response Selection任务,这样便可以使用大量的unlabelled对话语料(譬如Reddit conversational threads)进行模型预训练任务,使得模型的学习到的知识更多,同时证明了该预训练模型可以通过fine-tune的方式运用到下游的意图分类任务上。
第二,模型轻量性。同样以transformer为基础模型,但相比于BERT,Layer只有6层;模型训练采用大量技巧,比如训练时采用8-bit/16-bit的精度进行训练,而不是采用32-bit的精度。
模型整体结构如下,优化目标为最大化input和正例response的相似度分数,最小化input和负例response的相似度分数。


为了将对话历史融入,模型采用如下做法,最后loss为三个部分的loss叠加
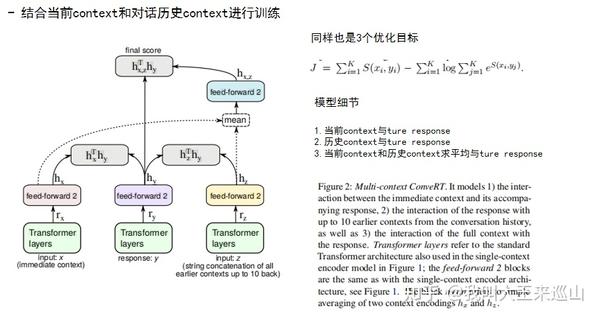

4. 《Span-ConveRT: Few-shot Span Extraction for Dialog with Pretrained Conversational Representations ACL 2020》【4】
这篇文章与上篇ConveRT都是同一个团队的作者,Span-ConveRT主要针对槽填充任务,想用对话领域的预训练语言模型ConveRT缓解当前slot-filling模型对话相关知识缺乏的问题。
- 当前slot-filling的挑战
当前对话内容较为简短,缺乏额外的知识,导致slot-filling的效果不好,使用资源丰富的域的域适应可以有效缓解域内数据的稀缺性,比如说融合了其他域知识的多任务学习,eg.intent和slot联合训练
- 创新点
1.指明了做好任务型对话模型的方向。本文建议了使用对话相关的预训练模型可以缓解知识缺乏的问题,比如ConveRT预训练语言模型,有推销自己的ConveRT的嫌疑??
2.丰富的文本输入特征。本文将三个binary特征,token里的字符长度特征与subword representations进行向量拼接,以强调重要的文本特征
- token是否是字母(binary特征)
- token是否是数字(binary特征)
- token是否是新词的起始位置(binary特征)
- token的character length
3.加入一个是否是slot的二值特征?训练时可以,但是预测时特征从哪里来?(存疑)
To incorporate the requested slots feature, we concatenate a binary feature representing if the slot is requested to each embedding in the sequence
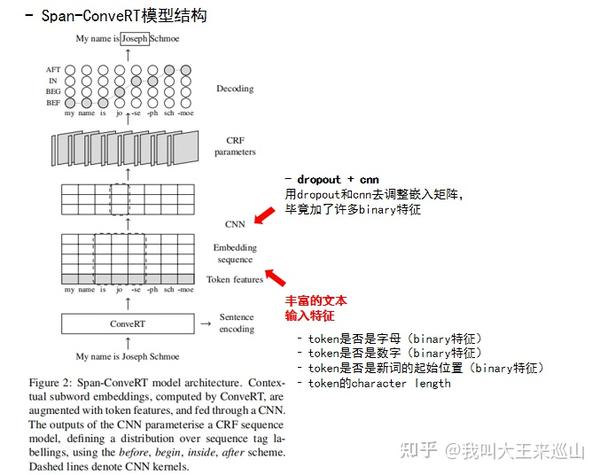

标题为span,何为span?-旧酒换新瓶
span使用标签序列表示,指示子词标记序列的哪些成员在span中,本文方法借鉴了ner中BOI方式,其实更准确的说是BMEO方式,用before, begin, inside and after 四个标记进行span的标记
- before, 非slot的词,类似于BMEO中的“O”
- begin, slot词的起始位置,类似于BMEO中的“B”
- inside,slot词的中间位置,类似于BMEO中的“M”
- after, slot词的终止位置,类似于BMEO中的“E”
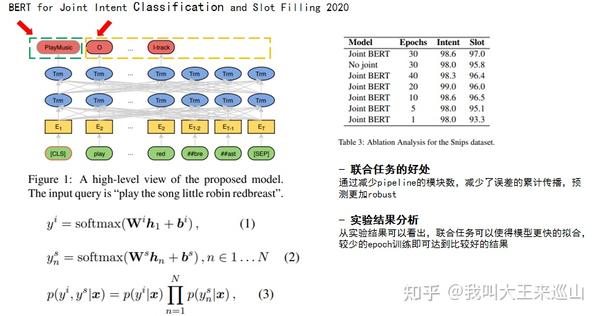
5. 《BERT for Joint Intent Classification and Slot Filling 2020》【5】
这篇文章为阿里发表的工程类型的文章,然而最大的问题是实际中这种联合任务的数据集从哪来,标注是否更加费力?说多了都是泪

三、Dialogue State Tracking (DST)
方式一:具有预定义的槽名称和值,每一轮DST模块试图根据对话历史找到最合适的槽值对
看成是一个 multi-class 或者 multi-hop classification 任务。
- multi-class任务
做法:tracker每一次读取所有槽值对,进行多分类预测
缺点:但是当value增大时,相当于模型预测的class的类别增大,那么就会增大模型的复杂度。
- multi-hop classification 任务
做法:tracker每一次只读取一个槽值对,并执行二分类预测
缺点:这种方式降低了模型的复杂性,但是提高了系统的时间复杂度
下面举例说明具有预定义的槽名称和值的DST过程


本文在DST部分介绍一个经典的NBT模型和一个比较复杂的TRADE模型


6.《Neural belief tracker: Data-driven dialogue state tracking ACL2017》【6】
- NBT模型属于multi-hop classification 任务
模型遍历某个领域内每一个(slot,value)对,以判断用户真实意图中包含该slot-value对的概率大小。例如上图中的Domain Ontology存在三个可能的slot-value对,分别是(food, Indian), (food, Persian), (food, Czech),假设当前遍历到了(food, Persian)这个取值,通过表征模型可以得到它的表征c,再通过图中所示的流程,最后可以得到一个结果y,这个结果便表明了(food, Persian)这个slot-value对属于用户真实意图的可能性大小
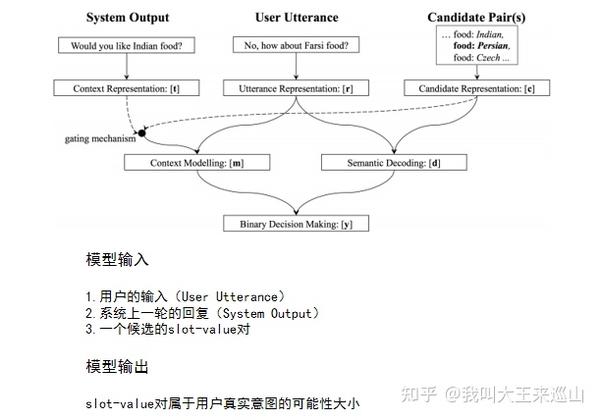

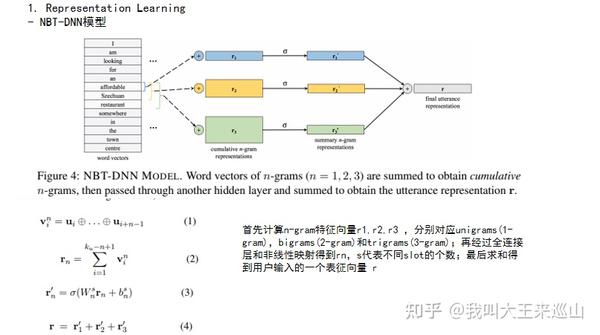
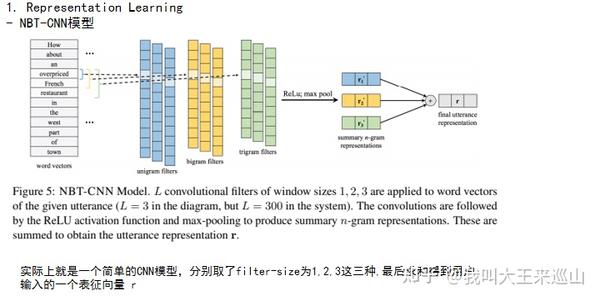
模型的结构如下所示:






7.《Transferable multi-domain state generator for task-oriented dialogue systems ACL2019》【7】
- 方式二:没有固定的槽值列表,因此DST模块尝试直接从对话上下文中查找值或根据对话上下文生成值
TRADE(可转移的对话状态发生器)属于方式二的这种DST模型
DST的目标是提取对话过程中表达的用户目标/意图,并将其编码为一组紧凑的对话状态,即一组slot-value对
传统的状态跟踪方法基于本体预先定义的假设,其中所有槽及其值都是已知的。拥有一个预定义的本体可以将DST简化为一个分类问题并提高性能。
然而,这种方法有两个主要的缺点:1)在业界,一个完整的本体很难提前获得,2)即使存在一个完整的本体,可能的槽值的数量也可能很大,而且是可变的。例如,餐厅名称或火车出发时间可以包含大量可能的值。因此,以往许多基于神经分类模型的工作可能不适用于实际场景。
Budzianowski等人(2018)最近引入了一个多域对话数据集(MultiWOZ),如图1所示,用户可以通过要求预订餐厅开始对话,然后询问附近景点的信息,最后要求预订出租车。在这种情况下,DST模型在每一轮对话中都要确定相应的域、槽和值,本体中包含大量的组合。30个(domain,slot)对和超过4500个可能的槽值。多领域设置中的另一个挑战来自执行多回合映射的需要。单回合映射是指可以从一个回合中推断出(域、槽、值)三联体的情况,而在多回合映射中,应该从发生在不同领域的多个回合中推断。例如,图1中attraction 域的(area, centre)对可以从前面提到的餐厅域的区域信息中预测出来
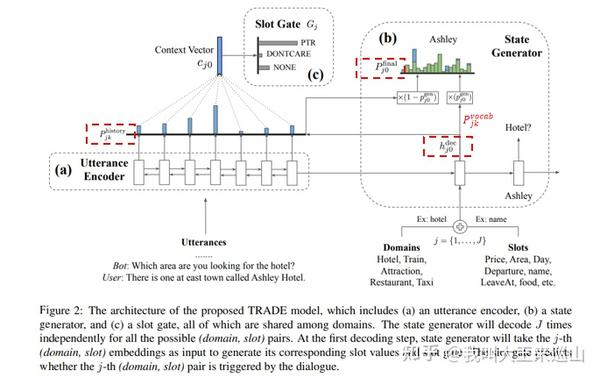



图2中提出的模型由三个部分组成:语音编码器、槽门和状态发生器【8】
一、Utterance Encoder(a)


二、State Generator(b)




三、Slot Gate(c)


四、Optimization


四. Dialogue Policy Learning(DPL)
- 简介
策略学习模块是对话管理器的另一个模块。该模块根据DST模块的输出对话状态来控制系统将采取的操作,监督学习和强化学习是主流的训练方法
监督学习模型可以精确地完成任务,但训练过程完全取决于训练数据的质量,此外,标注数据需要人力,决策能力受到特定任务和领域的限制,因此用强化学习做DPL成为主流
8. 《Hybrid Code Networks: practical and efficient end-to-end dialog control
with supervised and reinforcement learning》
虽然这篇文章是几年前发表的,但是文中所提出的整个对话流程思路非常清晰,也是值得借鉴和参考的。以查询天气为例,整个对话流程如下图所示:
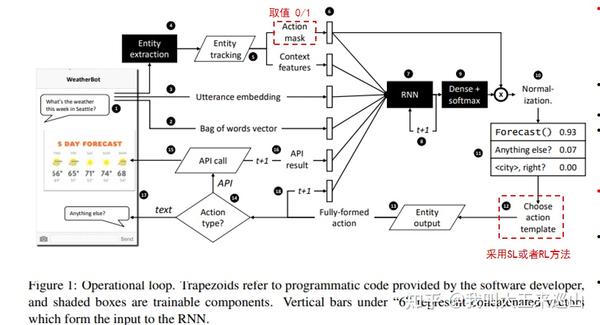

- 重要步骤说明
step4: 实体识别,比如将“Seattle”标记为<city>;
step5: “Entity tracking”模块,用实体检索数据库(事先设置,value可以多样),如果value为”action mask”的值(0/1)来控制是否采用某个action。比如:电话号码如果没有获取,那么打电话这个api的置信度就降为0。如果value为“context features”,那么features就是区分action的一些特征
step6: 将上面获取到的一些特征组合成一个feature vector,当然还包含step16和step18中得到的信息;
step7: 将step6中得到的feature vector输入RNN;
step10: 应用step5中得到的一个action mask(这个mask个人认为也可以设计成一个加权的形式),过滤掉一些被禁止的action,并re-normalization得到当前状态下被允许的action templates概率分布;
step12: 从step11中的概率分布中选择一个action。如果是强化学习则从概率分布sample一个,如果是监督学习则选择最高概率的;
step13: Entity output模块,将step12中得到的action template,其中的entity类型替换成真实的实体词,比如说将city换成Seattle
step14: 根据API的类型会有两种情况:如果是一个API call,则进入step15,如果是一个文本,则直接返回给用户;
- 拓展
DPL模块以DST模块判定的对话状态Sn作为输入,输出为系统动作An。目前绝大多数都是基于规则来实现DPL,也就是人工设计有限状态自动机。
有限状态自动机有两种表示方式:
- 以点表示数据(槽位状态),以边表示操作
- 以点表示操作(系统动作),以边表示数据(槽位状态)【更常用】
在实际业务中对比发现,后一种表示方式以系统动作为核心,设计方式更为简洁,并且易于工程实现。通常系统动作的定义有问询、确认和回答3种模式。【11】
- 问询(ask):目的是了解必要槽位缺失的信息
- 确认(confirm):目的是为了解决容错性问题,填槽之前向用户再次确认
- 回答(reply):表示最终回复,意味着任务和有限状态自动机工作的结束。
下面将给出一个具体示例,看看DPL模块的有限状态自动机究竟是怎么工作的。
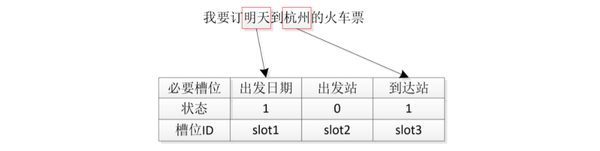

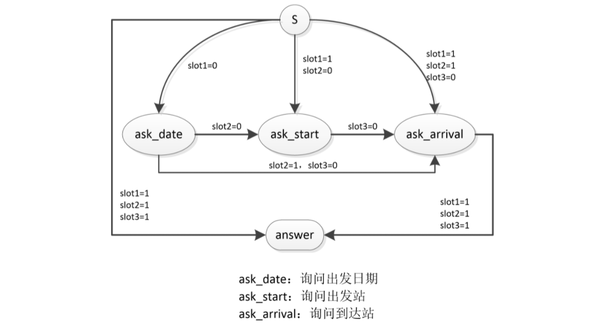

如上图所示,针对用户问题“我要明天到杭州的火车票”,其意图为“购票”,该意图下有三个必要槽位:“出发日期”、“出发站”、“到达站”,目前假设经过NLU模块、DST模块已经将其意图和槽位识别出来,发现“出发站”这个槽位缺失,于是根据上面的有限状态自动进的规则找到“slot1=1, slot2=0”这个路线,生成系统动作ask_start,进而执行“问询”模式。
NLG模块以DPL模块的系统动作作为输入,输出是系统对用户输入Xn的回复Yn。目前,NLG模块广泛采用基于规则的方法,进而根据规则将各个系统动作映射成自然语言表达。下面给出示例。
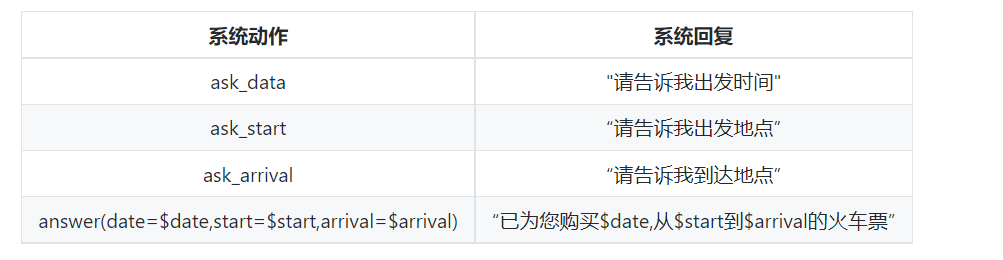

五、BAIDU UNIT对话
1.简介
百度unit从2017年以来到现在已经进化到了3.0版本,最近更新的版本在操作上比之间友好了很多,特别是Taskflow部分(图形化对话流编辑器),逻辑更加清晰。
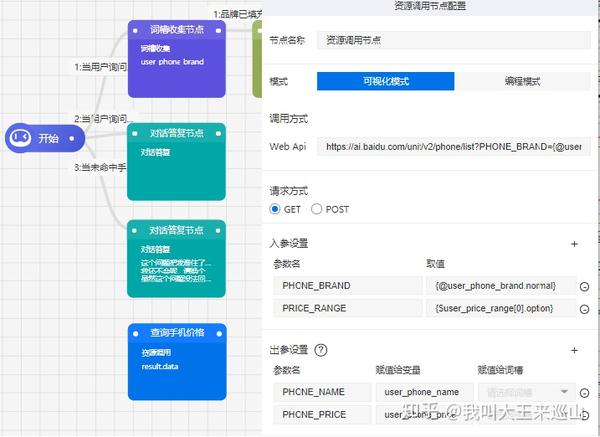
2.从Taskflow看业务多轮对话


如下图所示:api接口查询用户手机价格

什么是打断恢复能力?
- 当前节点是否支持恢复到原流程(对象为当前节点)


对话中上一个流程是因为被打断才跳转到当前流程时,默认会在完成所有动作后,发送已完成的信息给上一个流程,若选否,则动作完成后直接结束。
- 打断后是否支持恢复(对象为上一节点)
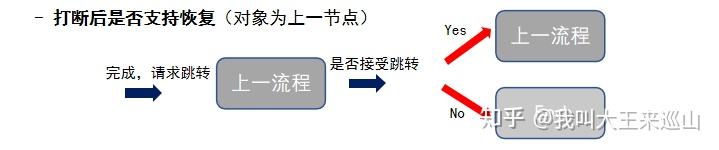

对话中节点若被打断到下一个流程,默认处于等待恢复状态,当接收到下一个流程成功完成对话的信息后,会继续完成该流程的后续动作。若选择否,则不再恢复对话
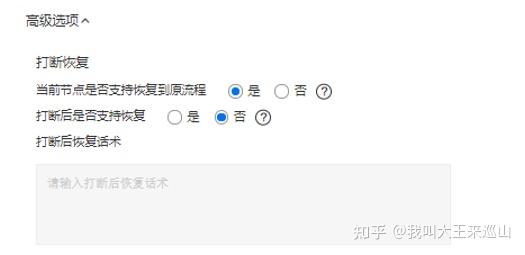
也就是说如果当前流程结束后能跳转到上一流程,那么两个设置都应该为Yes!
如果设置打断后支持恢复,在配置一个 打断后恢复话术 则不会使得对话跳转那么突兀
UNIT 对话回复节点配置如下图所示:

3. 从零开始对话
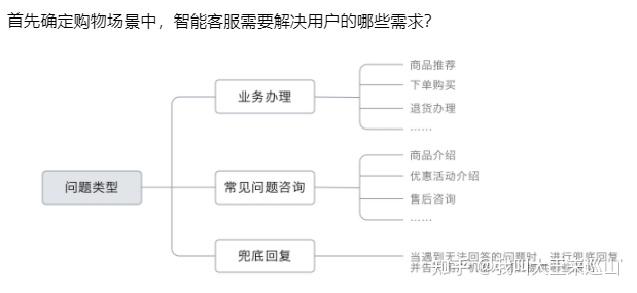

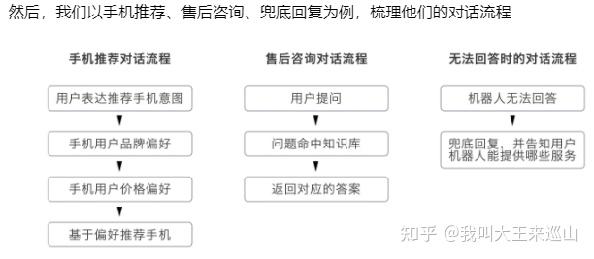

手机售卖业务可以用任务型对话和FAQ对话来实现
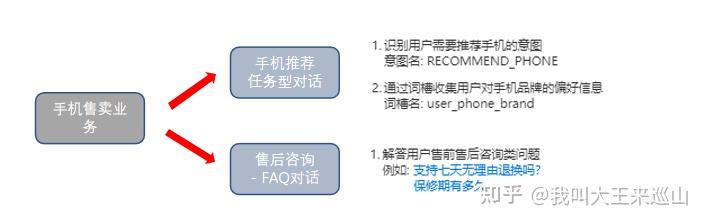

在UNIT设置好后,体验一下对话流程,看UNIT如何实现意图跳转




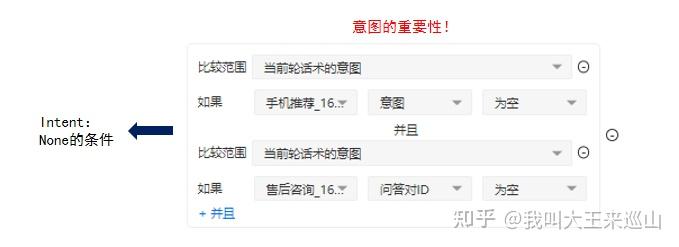
在UNIT设置TASK-Flow意图跳转的一些规则

六、总结
- 近年来,很直观的一个现象就是,模型越来越复杂了,但是回归工业界,那么复杂的模型真的能用吗,QPS跟得上吗。尤其是任务型对话,NLU, DST, DPL, NLG四个部分模型都不简单,貌似除了NLU用的上复杂的模型,DST和DPL基本上都是用有限状态机给整合过去的吧,如果有什么更快更强的方法,可以在评论区告诉我。
- 对比过腾讯,阿里的对话工厂,才发现百度UNIT真的是很棒,果然,没有对比就没有伤害。百度UNIT的Task-Flow整体逻辑非常清晰,构建界面也非常友好,从一代关注到现在的三代,在发展的过程中确实真切的考虑了很多实际的业务需求,优秀!(声明:本人从未接到百度UNIT的任何一笔广告费,手动狗头)
Reference
- 【1】Sequential Short-Text Classification with Recurrent and Convolutional Neural Network
- 【2】TOD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogue
- 【3】ConveRT: Efficient and Accurate Conversational Representations from Transformers
- 【4】Span-ConveRT: Few-shot Span Extraction for Dialog with Pretrained Conversational Representations
- 【5】BERT for Joint Intent Classification and Slot Filling
- 【6】Neural belief tracker: Data-driven dialogue state tracking
- 【7】Transferable multi-domain state generator for task-oriented dialogue systems
- 【8】Hybrid Code Networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning
- 【9】Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems论文讲解
- 【10】任务型对话系统公式建模&&实例说明
- 【11】Dialogue_System
胖友,请不要忘了一键三连点赞哦!
转载请注明出处:QA Weekly

