
机器学习——随机森林
###基础概念
随机森林是用随机的方式建立一个森林,森林里面有很多的决策树,并且每一棵决策树之间没有关联。也可说随机森林是决策树的组合模型,其中决策树的组合形式采用类bagging的形式。
####Boostrap、Bagging和Boosting(补充理解)
Boostrap:
Boostrap是一种组合方法的思想,它是用自身样本重采样的方法来估计真实分布的问题,其优势在于它的非参数性(non-parametric),即不需要假设样本服从某种特定的分布。但其缺点在于计算复杂:需要不停的放回抽样,在小样本时效果很好。Boostrap具体的实现方式包括Bagging,Boosting。
Bootstrap的实现方式:
- 采用重复抽样的方法每次原始样本中抽取n个样本
- 计算每个样本的统计量
- 重复步骤前面两个步骤k次,得到k个统计量
- 计算k个统计量的方差
Bagging方法: Bagging是boostrap aggregation的缩写,是一种根据均匀概率分布从数据集中重复抽样(有放回的)的技术。子训练样本集的大小和原始数据集相同。在构造每一个子分类器的训练样本时,由于是对原始数据集的有放回抽样,因此同一个训练样本集中可能出现多次同一个样本数据。
- 从整体样本集合中,有放回抽取n个样本,并进行k轮抽取,得到k个数据集
- 对k个数据集,训练出k个模型
- 结果选择:对于分类问题,结果选取分类器投票数最多的结果;对于回归问题:由k个模型预测结果的均值作为最后预测结果
Boosting方法: Boosting是一个迭代的过程,用来自适应的改变训练样本的分布,使得分类器聚焦在那些很难分的样本上
- 没有先验知识的情况下,初始的分布应为等概分布,也就是数据集如果有 n个样本,每个样本的分布概率为1/ n。
- 每次循环后提高错误样本的分布概率,分错的样本在训练集中所占权重增大,使得下一次循环的基分类器能够集中力量对这些错误样本进行判断。
- 最后的强分类器是通过多个基分类器联合得到的,因此在最后联合时各个基分类器所起的作用对联合结果有很大的影响,因为不同基分类器的识别率不同,他的作用就应该不同,这里通过权值体现他的作用,因此识别率越高的基分类器权重越高,识别率越低的基分类器权重越低。
随机森林实现过程: * 从原始训练集中进行bootstrap抽样 * 使用上一步的样本,生存决策树,随机选择特征子集,从这随机的特征子集中,选择最优的,并以此来拆分树的节点 * 重复以上两个步骤,生存多棵决策树 * 采取投票方式来选择对结果进行分类
Bagging和随机森林的区别在于,Bagging是通过对数据集进行随机抽取,而随机森林是对特征进行随机抽取,随机森林采取随机抽取特征的方式,主要是为了防止部分高预测性特征是决策树之间具有强相关性,这样并不会减小模型的方差。
随机森林分类效果(错误率)与两个因素有关:
- 森林中任意两棵树的相关性:相关性越大,错误率越大;
- 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
###随机森林的优缺点
优点:
- 支持高维度数据,兼容连续型变量和离散型变量,同时不用对数据进行特征筛选
- 由于在变量和数据上的随机抽取,使得随机森林不容易产生过拟合现象,同时也有很好的抗噪声性
- 训练速度相对于其他集合模型有不少的优势,同时模型使用也相对简单
- 是个有用的辅助模型,比如可以对变量进行重要性排序,检查样本间的相似性等
缺点:
- 当随机森林中的决策树个数很多时,训练会比较耗时以及耗内存
- 可解释性不高
###随机森林相关指标
####袋外错误率 构建随机森林的关键问题是如何选择最优的特征数,要解决这个问题主要依据计算袋外错误率oob error(out-of-bag error)。
随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。
在构建每棵树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对于每棵树而言(假设对于第k棵树),大约有1/3的训练实例没有参与第k棵树的生成,它们称为第k棵树的oob样本。
而这样的采样特点就允许我们进行oob估计,它的计算方式如下:(note:以样本为单位)
- 对每个样本,计算它作为oob样本的树对它的分类情况(约1/3的树);
- 然后以简单多数投票作为该样本的分类结果;
- 最后用误分个数占样本总数的比率作为随机森林的oob误分率。
oob误分率是随机森林泛化误差的一个无偏估计,它的结果近似于需要大量计算的k折交叉验证。
###python代码实现
以下是使用sklearn简单实现随机森林
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
df.head()
train, test = df[df['is_train']==True], df[df['is_train']==False]
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2)y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
preds = iris.target_names[clf.predict(test[features])]
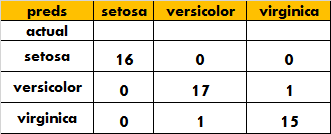
result=pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])
print(result)
结果如下:
###比较随机森林与其他模型的差异
from sklearn.datasets import load_boston
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
boston = load_boston()
#查看波士顿数据集的keys
print(boston.keys())
boston_data=boston.data
target_var=boston.target
feature=boston.feature_names
boston_df=pd.DataFrame(boston_data,columns=boston.feature_names)
boston_df['tar_name']=target_var
#查看目标变量描述统计
print(boston_df['tar_name'].describe())
#把数据集转变为二分类数据
boston_df.loc[boston_df['tar_name']<=21,'tar_name']=0
boston_df.loc[boston_df['tar_name']>21,'tar_name']=1
# 拆分训练集的30%作为测试集
X_train, X_test, y_train, y_test = train_test_split(boston_df[feature], boston_df['tar_name'], test_size=0.30, random_state=1)
#构建决策树模型
tree = DecisionTreeClassifier(criterion='entropy', max_depth=None)
#构建bagging分类器
bag = BaggingClassifier(base_estimator=tree, n_estimators=500, max_samples=1.0, max_features=1.0,bootstrap=True, bootstrap_features=False, n_jobs=1, random_state=1)
#构建随机森林
rf = RandomForestClassifier(n_estimators=500, criterion='gini', max_features='sqrt', max_depth=None, min_samples_split=2, bootstrap=True, n_jobs=1, random_state=1)
# 度量单个决策树的准确性
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train, tree_test))
# 度量bagging分类器的准确性
bag = bag.fit(X_train, y_train)
y_train_pred = bag.predict(X_train)
y_test_pred = bag.predict(X_test)
bag_train = accuracy_score(y_train, y_train_pred)
bag_test = accuracy_score(y_test, y_test_pred)
print('Bagging train/test accuracies %.3f/%.3f' % (bag_train, bag_test))
# 度量随机森林的准确性
rf = rf.fit(X_train, y_train)
y_train_pred = rf.predict(X_train)
y_test_pred = rf.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Random Forest train/test accuracies %.3f/%.3f' % (tree_train, tree_test))
以上三种模型的结果分别为:
Decision tree train/test accuracies 1.000/0.789
Bagging train/test accuracies 1.000/0.875
Random Forest train/test accuracies 1.000/0.888
可以见得,集合分类器的精度要比单棵决策树高上不少,同样是集合模型,随机森林的结果也略好于bagging。
###延伸概念
Bagging和Boosting的组合模型之所以效果比基分类器好,是因为Bagging比其任何一个基分类器效果好因为尝试去降低模型的方差,而Boosting尝试去降低模型的偏差。
####方差和偏差
训练模型和真实模型之间通常会存在差异,而这些差异主要体现在稳定性和正确性两个方面。
方差衡量的是模型的稳定性,由于我们的样本数据并不是包含所有的可能数据,这就导致不同的数据训练出来的模型参数会有差异,用有差异的模型去做预测,就会造成预测结果和真实结果之间的不同,而这种差异的大小就是方差。
偏差衡量的是模型的正确性,比如我们用一个线性模型去拟合本来是非线性模型的数据,这时候我们无论如何调整参数,都很难到达最优效果,而这种偏差的大小就是偏差。
在建立模型上要解决这两个问题,方差主要是数据集大小的问题,偏差主要是模型选择问题。
参考文档: * https://www.cnblogs.com/maybe2030/p/4585705.html * http://blog.csdn.net/xlinsist/article/details/51475345

