
图像异常检测1:用图像复原重建+自监督学习+GMSD+SSIM作异常检测

题目:Reconstruction by inpainting for visual anomaly detection
来源:Pattern Recognition
原文链接:
一、Motivation
动机1:改善像素级重建的重构误差失灵问题;
动机2:异常定位。
文章核心思想源于以下两篇文献:
1、自监督学习+图像复原重建:
Arxiv2019:《Attribute Restoration Framework for Anomaly Detection》[1]
2、Anomaly detection+ Anomaly localization[多尺寸平均]+ Anomaly score Map
CVPR2020:《Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings》[2]
二、Contribution
1、将图像异常检测转换为自监督学习下的图像复原重构问题;
2、不只使用L2距离,配合使用新的图像相似度度量函数:SSIM和GMS。
备注:SSIM(structural similarity index)和GMS或GMSD(Gradient Magnitude Similarity Deviation)这两个图像相似度函数不是本文原创,是数字图像处理领域的技术,两者都是全参考的图像相似度算法。SSIM从亮度、对比度和结构三方面来比较图像相似度,GMS使用梯度幅值作为特征来比较图像相似度。值得说明的是,自然图像往往有着丰富类型的局部结构,不同的结构在失真中会有不同的梯度幅值退化,因而,梯度幅值能够反映结构信息。
三、Algorithm
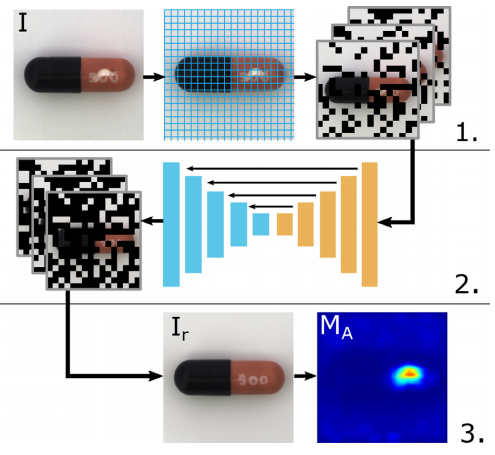

Step1:输入是原始图像 I ;
Step2:中间处理过程
1、图片处理成k*k的N个patch;
2、mask掉 \frac{N}{n} 个patch,重复n次得到n张mask后的“残缺图”,这n张“残缺图”中被mask掉的patch交集为空,即保证每个patch都能被mask,再在后续处理中被重建。
注:H,W是图像的高和宽, N=\frac{H}{K}\times\frac{W}{K} ,n为超参数代表想要生成的残缺图数
3.n张“残缺图”输入如下图所示的Reconstruction network architecture重建:


①模型结构
如图2所示,本文所使用的复原重建网络是一个基于encoder-decoder的U-Net模型,此外,模型在浅层和深层之间还使用了类似ResNet的Skip Connection。
②重建过程:


从原图到残缺图到复原图的流程:原图I→mask矩阵 M_{si} 和 I 相乘得到 I_{i} →输入模型重建得到 I_{ri} → I_{ri} 乘mask矩阵 M_{si} 的逆→重复n次,组合n个 I_{ri} 得到最终的完整复原图像 I_{r}
上述过程直观地讲,原图 X=A+B ,mask掉A后得到 X_{mask}=B ,将 X_{mask} 输入重建模型得到 X_{re}=A_{re}+B_{re} ;然后,在 X_{re} 上mask掉 B_{re} 后得到 X^{mask1}_{re}=A_{re}
重复以上过程,原图 X=A+B ,mask掉B后得到 X_{mask} =A,将 X_{mask} 输入重建模型得到 X_{re}=A_{re}+B_{re} ;然后,在 X_{re} 上mask掉 A_{re} 后得到 X^{mask2}_{re}=B_{re}
将 X^{mask1}_{re}=A_{re} 和 X^{mask2}_{re}=B_{re} 组合起来得到最终的复原图像。文中这样做的目的是为了保证图中被mask掉的部分都是靠且仅靠没有被mask掉的部分重建复原出来。
Step3:输出
输出的是复原重建后的图像 I_{r} ,衡量 I 和 I_{r} 的相似度得到Anomaly score Map .
供Anomaly localization使用的Anomaly score Map M_{A} .→计算复原图和原图每个patch的GMSD[梯度幅度相似性偏差,衡量图像的结构相似度],组合得到anomaly map;
供Anomaly detection使用的Anomaly score→比较Anomaly score Map M_{A} 中各patch的得分,取最大值作为当前图像的Anomaly score。
四、Experiments
1、主要实验设置
训练损失函数: L=\lambda_{G}L_{G}+\lambda_{S}L_{S}+L_{2}
\lambda_{G} 、 \lambda_{S} 为超参, L_{G} 为原图和复原图之间的GMSD相似度, L_{S} 为原图和复原图之间的SSIM相似度, L_{2} 为 L_{2} 距离。
2、主要实验及结果
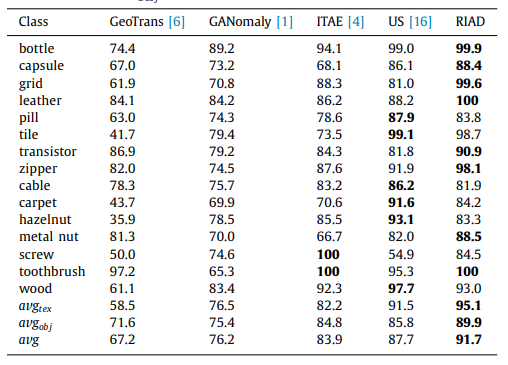
①图像Anomaly detection实验,RIAD是本文工作:

②图像Anomaly Localization实验,RIAD是本文工作:


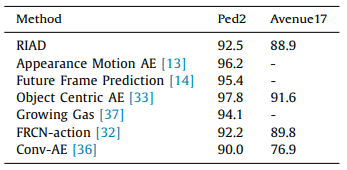
③视频Anomaly detection实验,RIAD是本文工作:
五、Conclusion
1、主要改进之处:
①在MVTec数据集上的Anomaly Localization和Anomaly detection上达到了SOTA效果,较之最近最佳的US模型。不仅效果更好,而且训练也更简单。
②在添加使用图像结构相似性度量函数GMSD和SSIM之后,本文算法在具有结构差异的图像异常检测任务上表现优异。
2、存在的问题:
①本文方法对random-pattern-heavy图像效果有限。
本文提出的基于重构复原的异常检测+图像结构相似度度量方法在random-pattern-heavy图像上(随机花纹多的?)效果有限,如MVTec数据集中的tile瓷砖、螺母等,本文方法在这些图像上的正常区域也会计算出较大anomaly score,从而难以和正常的异常区域区分开。
对random-pattern-heavy含义的理解:图像本身具有随机的复杂的纹理结构,即正常数据集中图片与图片,图片与图片对应位置patch间都存在差异。
对本文方法不适用于random-pattern-heavy图像原因的猜测(文中未作深入分析):a.具有复杂纹理结构图像自身重建就很困难,因此正常patch和异常patch的anomaly score都很大,导致两者难以区分开;b.具有随机纹理结构的图像相似度不便衡量,正如世界上没有两片完全相同的叶子,也没有两块一模一样的瓷砖,那么,如何区分“异常”和“正常随机花纹的差异”就需要另作考虑。
②多尺寸异常检测融合方式→实际具有先验思想的局限性。
图像划分的patch尺寸与图像中异常点的尺寸的适配程度会直接影响异常检测效果,本文以及当前最新最佳的研究都采用的是使用不同尺寸(如k设置为2,4,8,16)多次训练模型,然后取均值作为最终结果。这种处理方式实际上是通过分析MVTec数据集图像特点,预判了图像异常点的尺寸大小(2,4,8,16涵盖了大部分MVTec数据集中的异常尺寸),是一种先验思想的应用。以上实际上是一种假设和对问题的简化,对现实情况中“异常点”的完全不可控场景是不适用的。
以上仅个人一己之见,欢迎一起学习讨论。
