
深度学习--RNN学习笔记1

封面来源:https://vinodsblog.com/2019/01/07/deep-learning-introduction-to-recurrent-neural-networks/
参考资料:
[1] https://www.coursera.org/specializations/deep-learning
[2] Recurrent Neural Networks cheatsheet, By Afshine Amidi and Shervine Amidi, https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
[3] 完全图解RNN、RNN变体、Seq2Seq、Attention机制, https://zhuanlan.zhihu.com/p/28054589
[4] https://blog.csdn.net/u013733326/article/details/80890454
本文是Andrew Ng 的deep learning学习笔记,图表主要引自[2]。本文笔记的知识点有:
- 输入数据如何处理成可可供模型训练的数据,
- RNN的前向传播、后向传播、损失函数、优缺点的简单介绍,
- RNN结构类型的简单介绍。
1 概览
1.1 RNN及其前向传播
RNN(Recurrent neural network),即循环神经网络,用来处理输入或输出或两者是序列数据的一类神经网络算法,它的特点是会用先前的输出作为输入到隐藏状态,其典型结构如图1所示。
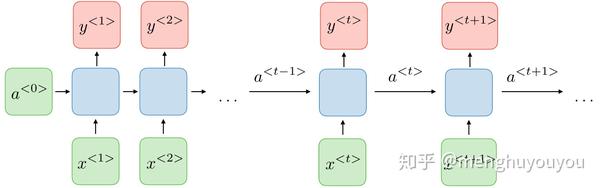

基于图1,先定义符号来建立RNN。这里以一个命名实体识别问题举例:
图2的输入 x 是由9个单词组成的序列,我们用9个特征集合x^{<1>},x^{<2>},...,x^{<9>}来表示这9个单词,并按序列中的位置进行索引,即用 x^{<t>} 来索引序列中的第 t 个位置。用 T_x 来表示输入序列的长度,这里 T_x =9 。同理,我们采用相同方法表示输出序列 y ,不再叙述。
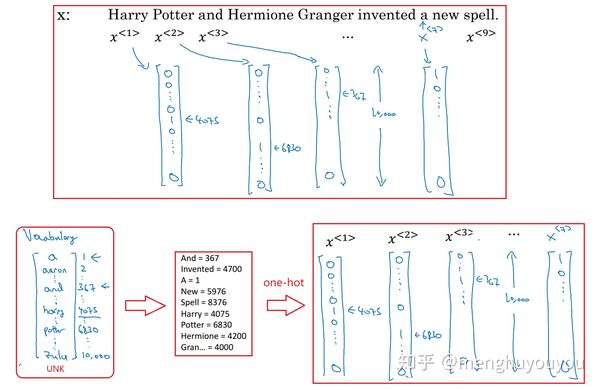

这里有个问题: x^{<1>},x^{<2>},...,x^{<9>} 实际应该是什么?
如图2,实际上我们会先遍历训练集构建一个词典。(意味着输入序列中的单词可以词典查到,当查不到时可再定义一个<UNK>来表示)然后就获取每个单词的在词典位置(序号),再用one-hot表示法就得到了 x^{<1>},x^{<2>},...,x^{<9>} ,最后就它们输入到一个RNN中。那么对于每一时间步 t ,有激活值 a^{<t>} 和输出值 \widehat{y}^{<t>} 的表达式:
\boxed{a^{< t >}=g_1(W_{aa}a^{< t-1 >}+W_{ax}x^{< t >}+b_a)}\quad\mbox{and}\quad\boxed{\widehat{y}^{< t >}=g_2(W_{ya}a^{< t >}+b_y)} \quad (1)
这里,W_{ax}, W_{aa}, W_{ya}, b_a, b_y 为参数, g_1, g_2 为激活函数,一般分别选用 tanh, \quad softmax 激活函数。式(1)就如图3所示形式,这时就可以计算一个RNN单元的前向传播。
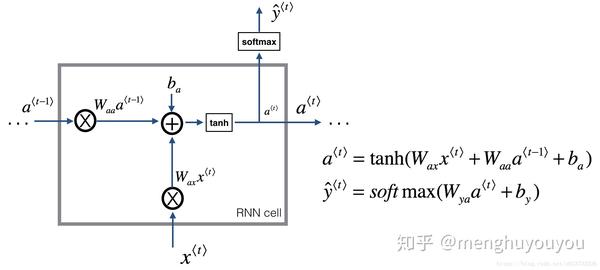

1.2 损失函数(Loss function)
为了计算反向传播,先定义一个元素的损失函数:
\boxed{\mathcal{L}^{<t>}(\widehat{y}^{<t>},y^{<t>})=-{y}^{< t >}log\widehat{y}^{<t>}-(1-{y}^{< t >})log(1-\widehat{y}^{<t>})}\quad (2)
它对应的是序列中一个具体的词,如果它是某个人的名字(比如前面的Harry),那么 y^{<t>} 的值就是1,然后RNN将输出这个词是名字的概率值,比如0.8,即 \widehat{y}^{<t>} 为0.8。这就是关于某个时间步 t 上对应单词的预测值的损失函数。那么对于整个序列的损失函数有:
\boxed{\mathcal{L}(\widehat{y},y)=\sum_{t=1}^{T_y}\mathcal{L}^{<t>}(\widehat{y}^{< t >},y^{< t >})}\quad (3)
1.3 穿越时间的反向传播(backpropagation through time)
已经知道损失函数,就可以反向求每个时间步上偏导(导数),再用梯度下降算法来更新参数。
\boxed{\frac{\partial \mathcal{L}^{(T)}}{\partial W}=\sum_{t=1}^T\left.\frac{\partial\mathcal{L}^{(T)}}{\partial W}\right|_{(t)}}\quad(4)
图4为计算一个RNN单元的反向传播:
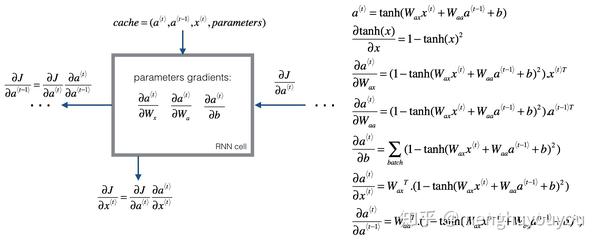

结合以上3点,我们就可以构建一个典型RNN结构,具体见《深度学习--RNN学习笔记2》。
1.4 典型RNN优缺点
典型RNN的优缺点下图3所示:


1.5 RNN结构
RNN主要应用在语音识别和自然语言处理等领域。RNN主要有以下几种结构:
1) one2one( T_x=T_y=1 ) -- 传统的神经网络


2) one2many( T_x=1, T_y>1 ) -- 音乐生成
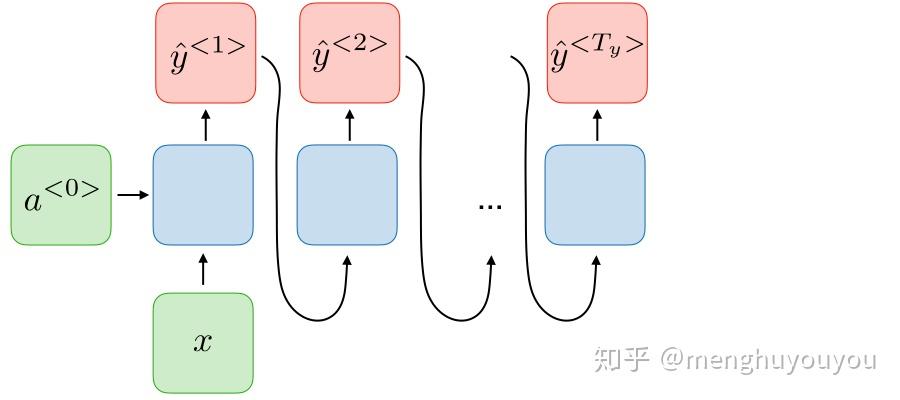

3)many2one( T_x>1, T_y=1 ) -- 情感分类
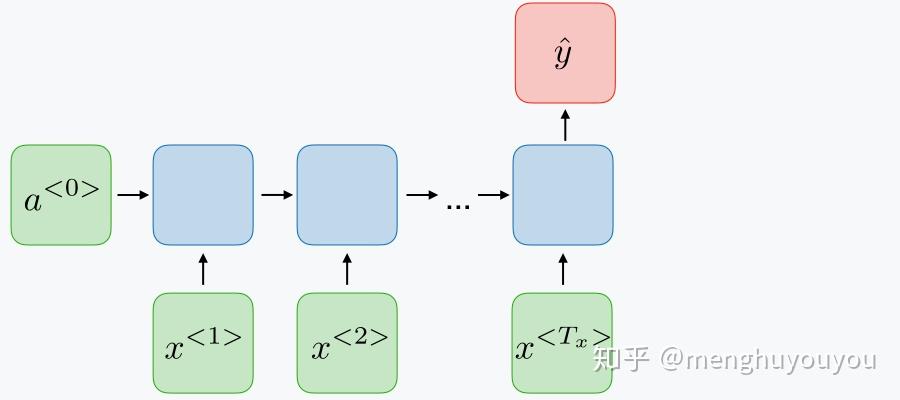

4)many2many( T_x=T_y>1 ) -- 命名实体识别
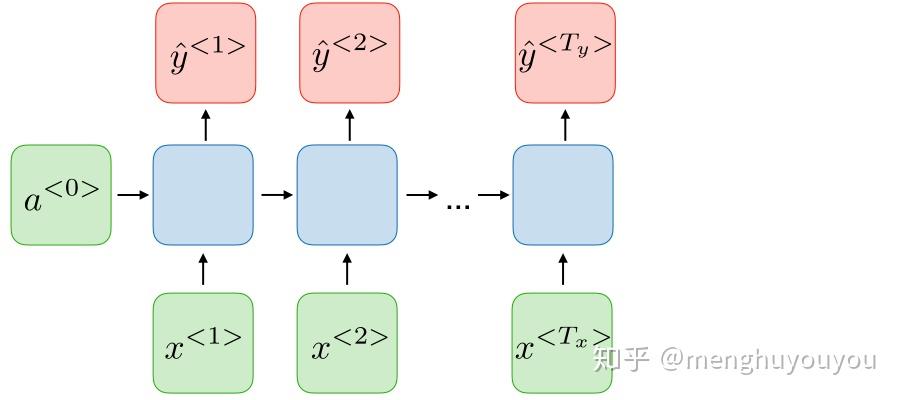

5)many2many( T_x\ne T_y, both>1 ) -- 机器翻译


关于RNN结构类型的具体解释,可参考[3] 完全图解RNN、RNN变体、Seq2Seq、Attention机制。