Few-Shot Learning as Domain Adaptation: Algorithm and Analysis(ICML2020)

摘要链接:https://ui.adsabs.harvard.edu/abs/2020arXiv200202050G/abstract (各种渠道都没找到这篇论文,或许ICML2020合集有)
前景提要:这篇文章正确率达不到,应该是撤稿了,可以学习下思想
Abstract
由可见类不可见类不同引起的class-difference-caused分布偏移可以看作是域偏移的一种特殊情况。本文首次提出了一个domain adaptation prototypical network with attention(领域适应关注原型网络,DAPNA)来明确地解决元学习框架下的领域转移问题。
具体来说,本文用a set transformer based attention module,在已见类上构造两个不重叠的子集,以模拟已见类和未见类之间的域转移。为了将两个子集的特征分布与有限的训练样本相结合,采用特征转移网络和margin disparity discrepancy(MDD)损失。重要的是,本文还对DAPNA的学习边界进行了理论分析。
Introduction
小样本学习还有一个迄今为止被忽视的额外挑战,那就是,不可见类的分布与在训练中看到的不一样,这种分布差异/移位是由类别标签差异引起的。这与经典领域适应(Domain adaptation,DA)问题中研究的问题领域差异不同,其中源和目标数据集包含相同的类,但来自不同的领域(例如,训练一个猫分类器分别识别绘画和照片中的猫)。但同样会导致在源数据上训练的模型泛化效果较差,因此可以将其视为域移位的一种特殊情况。
本文首次提出在一个统一的元学习框架中,与FSL共同解决由类差异引起的域转移问题(Chen et al., 2019)。需要注意的是,在评估论文中并没有明确提到域移位问题(Chen等人,2019)。尽管DA和FSL都得到了深入的研究,并且存在各种独立解决每个问题的方法,但在统一的元学习框架中共同解决这两个问题是重要的。主要的挑战是估计和对齐数据分布与小样本训练样本。为此,提出了一种新颖的域适应注意原型网络(DAPNA)元学习模型,该模型将FSL和DA无缝地结合在一个单一的框架中。
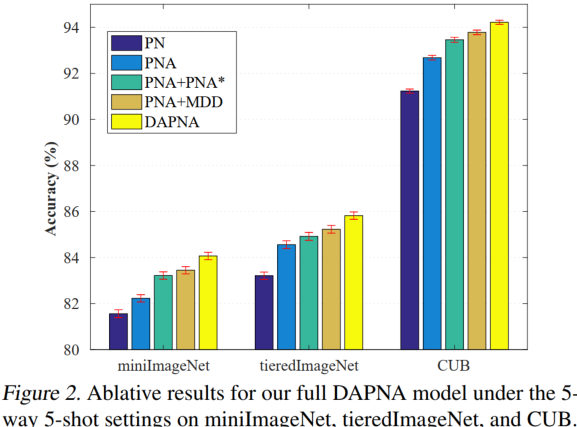
具体来说,我们首先介绍了一种基于实例注意模块的原型网络(ProtoNet) 的Set transformer (Set Transformer),使每个类的少数训练样本比使用的简单平均更好地组合来代表类原型。至关重要的是,为了使元学习模型在对抗阶层差异引起的领域转移方面具有内在的鲁棒性,每个元训练episode现在包含两个并行运行的sub-episode;每个子集包含一组不同的seen类。然后,该模型被强制在一个共享的特征嵌入空间中对齐两个sub-episode 中的样本分布。需要注意的是,每一阶段的样本数量仍然非常有限,这对现有的数据分析方法构成了挑战。为了克服这一问题,我们采用了一个具有编码器-解码器架构的特征传输网络来协助域对齐。进一步,使用margin differences differences (MDD) loss 来减小两个子集之间的域间隙。我们的比较结果(表1)和消融结果(图2)显示了引入元数据分析对基于元学习的FSL的显著优势。重要的是,我们还提供了理论分析,给出了我们的DAPNA模型的学习边界。
Contributions
(1)首次提出了传统的FSL问题必须与DA问题一起解决,并将meta-DA引入到ProtoNet中,建立了一种新的DAPNA模型。(2)提出了基于元学习的语言学习在语言学习领域的第一个严格学习边界。(3)我们的DAPNA模型在三个标准FSL和一个跨域FSL基准数据集上实现了最新的性能。
Related work
DAPNA属于基于度量学习的变体。然而,与任何现有的FSL模型不同的是,它明确地解决了在一个two-sub-episode的元训练框架中由可见类和不可见类之间的差异引起的域转移问题。
领域适应(Domain Adaptation )旨在将学习模型推广到不同的领域或不同的分布。(Mansour等人,2009;Ben-David et al., 2010)在Probably Approximately Correct(PAC)框架下(Valiant, 1984)提供了无监督DA的理论基础和严格的学习界限。从那时起,提出了许多最小化分布差异或学习边界的DA算法,或者基于对抗学习(Goodfellow等人,2014;Ganin等人,2016;Long et al., 2018)或统计匹配(Long et al., 2015)。注意,在所有现有的DA工作中,源域和目标域都假定包含相同的一组类。在这项工作中,我们首先发现尽管可见类和不可见类来自同一个域,域移位问题(Gretton et al., 2009)也存在于传统的FSL问题中。这种由类不同引起的域偏移由于可用的训练样本很少,独特并难以解决。在本研究中,我们构建了两个无类重叠的sub-episodes 作为元训练中DA的源域和目标域。我们的大量实验表明,引入这样的meta-DA显著提高了学习模型的跨域可移植性。注意FSL和DA结合的工作已经发表过(Motiian et al., 2017)。然而,本文和(Motiian et al., 2017)中的问题设置有很大的不同,该篇论文目标域与源域具有相同的类,但用于DA的样本很少。
Methodology
Problem Definition
在小样本的设置下,从一组源类Cs得到一个很大的样本集Ds,从一组目标类Ct得到一个few-shot的样本集Dt和一个测试集T, Ds∩Dt=∅。基于Ds得到的分类模型可以很好地推广到T。需要注意的是Dt也可以用于模型训练,但是本文遵循的是不需要对不可见类进行微调的FSL设置,因此在训练阶段忽略了Dt。这使模型可以更快部署到不可见的类。
本文定义了广泛使用在元学习上使用的episodic训练策略,episode D = {S,Q} 构造如下: 我们首先从Cs选择一个小的源类C,然后通过从C的每一类中随机采样k个support samples和q个query samples产生S和Q。然后,通过最小化每episode中查询集Q上的预测标签和groundtruth标签之间的损失函数来训练模型。
Few-Shot Learning Module
本文使用了原型网络(ProtoNet) 作为我们的baseline模型,在原型网络中,一个类被表示为少数训练样本的均值。然而,简单地将类原型表示为样本均值可能不是最优策略,特别是当样本数量较少时,例如单个离群样本可能会给原型带来较大的偏差。因此,我们建议通过引入基于set transformer的注意力机制来学习使用单个类原型来表示一组训练样本的最佳方法。具体地说,我们构造了一个triplet (查询、键、值):查询点匹配一个键列表,其中每个键都有一个值;计算查询点与键的相似性;最终值表示为计算出的相似性加权后的所有值的总和。形式上,我们用U 表示一组查询点,K表示键,V表示值:
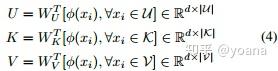
其中d为U中元素的维数U,K,V。然后,U 中的查询点xi和K中的一个key计算得到一个“attention”,这些attentions作为权值来计算查询点xi的最终嵌入:
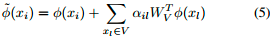
在将实例表示φ(xi)转换为新的φ~(xi)之后,我们仍然使用方程式(1)-(2)计算每个类的原型,以φ~(xi)为输入。得到的模型被称为ProtoNet with Attention(PNA)。为简单起见,我们将triplet元素统一设置为一集的支持集:U = K = V = S。
Domain Adaptation Module
在我们的FSL框架中引入域适应(DA)模块之前,我们需要对每个训练样本的原始特征进行变换,将变换应用到对样本所属域不敏感的特征嵌入空间中。为此,我们引入了一种特征传递网络,将实例特征在特征嵌入空间中转换为域混淆,并在特征嵌入前保持实例特征的判别性。具体来说,我们在backbone的顶部添加了一个编码器-解码器网络(如图1所示)用于特征嵌入。
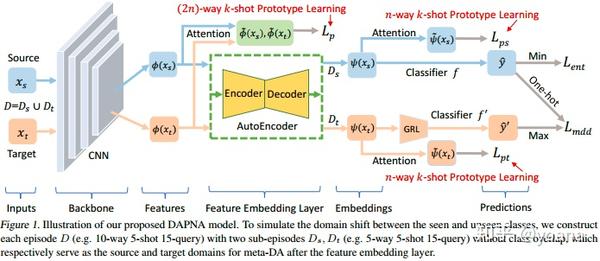

此外,为了模拟可见类和不可见类之间的域转移,我们构造每个episode D = {S,Q} (e.g. 10-way 5-shot 15-query)在无类重叠的两个sub-episodes Ds={Ss,Qs} 和Dt={St,Qt} 的可见类上,每个sub-episode包含相同数量的样本(e.g. 5-way 5-shot 15-query),但有不同的类。然后我们计算PNA损失(见第3.2节)通过两个sub-episode如下:
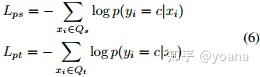
式中p(yi = c|xi)与式(2)中类似,唯一不同的是将嵌入函数改为了基于注意力机制的。
根据上面的episode定义,我们可以很容易地将DA引入元训练。具体来说,我们将一个子集Ds作为源域,另一个子集Dt作为目标域。我们希望通过meta-DA来缩小Ds和Dt之间的域间隙。这是通过向反向传播DA损失到backbone network来实现的。其优点在于,在元学习框架下可以提高学习模型的可移植性。
。。。MARGIN LOSS 和 MARGIN DISPARITY DISCREPANCY部分暂时忽略。。。
根据最新的DA方法,我们选择DA学习界的前两个项(Rademacher复杂性是常数w.r.t.f),因此我们的meta-DA问题表述为:
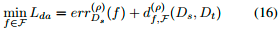
DAPNA Algorithm
DAPNA模型的整体损失函数(如图1)定义如下:
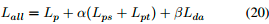
其中α和β是控制特征嵌入层和DA损失后FSL损失重要性的系数,最小Lda表示式(17)的过程。我们对我们的DAPNA模型有如下的理论分析。
定理3.2 (FSL的学习界)
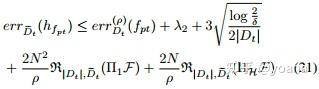
定理3.3 (DAPNA的学习界)
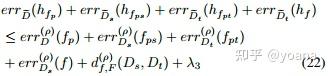
完整的算法概述在算法1中。

Experiments
本文使用WRN-28-10作为backbone,和state-of-the-art方法比较miniImageNet,tieredImageNet和CUB数据集的正确率。
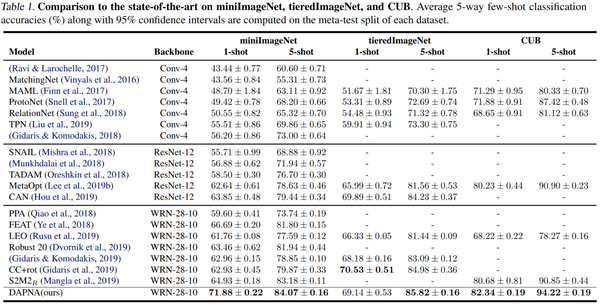

miniImageNet→CUB跨域实验结果。
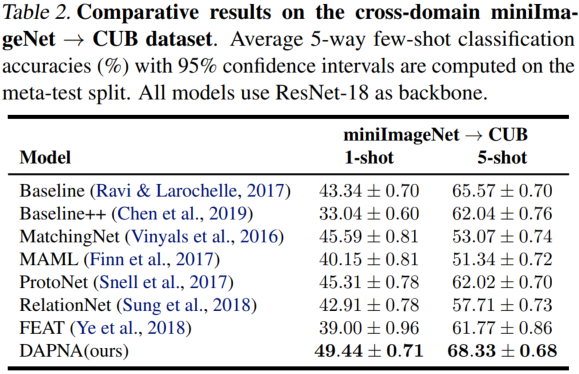
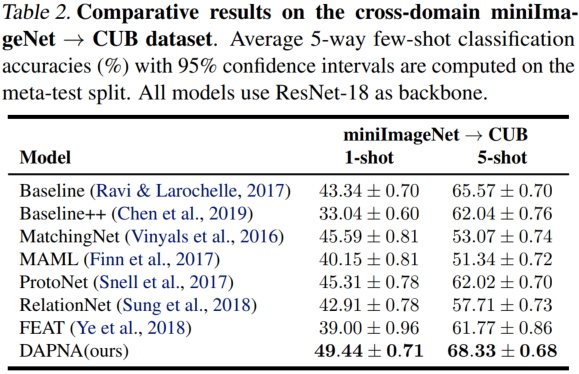
消融实验

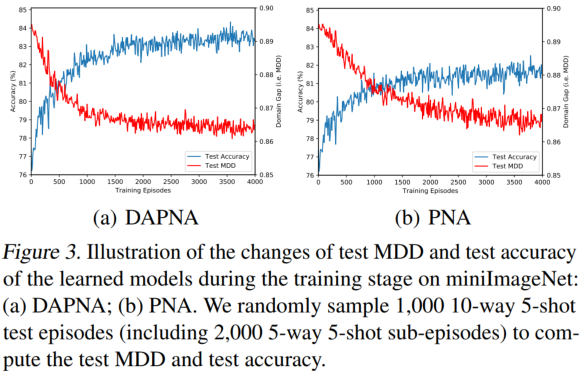
在定理3中,对本文的DAPNA模型进行了理论分析。为了进一步支持定理3,在图3中给出了说明性的结果