关于GNN的几个疑问的思考

1 GNN的半监督体现在哪里?
GNN的体现半监督的地方和伪标签的经典半监督学习算法比较类似,但是存在本质不同。
在伪标签中,以二分类为例,使用模型先训练有标签的数据,然后预测无标签数据,得到的概率值作为样本权重从而将每一个无标签样本分为两个带权重的标签分别为0,1的样本,此为软标签,或者直接进行概率截断得到标签为0或1的硬标签样本,不断迭代直到达到预定的迭代次数或预测概率收敛。
GNN的做法有一些相似,在模型训练的过程中使用了无标签节点的特征,但是和伪标签不同,GNN使用的是无标签样本的特征而不是使用模型对无标签样本的预测概率。
基于空域的GNN非常好理解,上手写代码也非常容易,目前基本上看的和使用的也都是从空域的角度出发去思考和实践。
所谓的基于空域,其实就是
1、消息传递机制;
2、聚合函数的GNN;
3、更新计算,
空域的视角理解GNN非常的自然和简单。
1、消息传递:
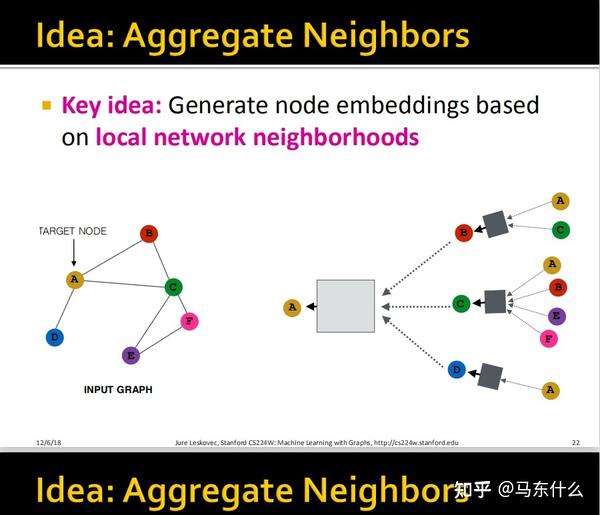

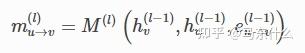
所谓的消息传递,就是定义节点v的一阶邻节点u,怎么把邻居和自己的node feature传递给自己,上述的公式是一个非常简练的表达,可以囊括各种情况,根据这里的公式也可以非常方便的自己设计自定义的消息传递范式,为了简单表达,这里假设l=1,则hv(l-1)=hv(0)即第0层的节点的表示,第0层的节点表示就是节点本身的特征,比如年龄,性别,收入之类的。同理hu(0)是v的一阶邻节点的本身的节点特征,(如果节点本身没有特征,可以通过node2vec或其它的一些基于邻接矩阵或拉普拉斯矩阵分解的图嵌入技术来生成节点特征或者更简单直接用单位矩阵作为节点输入的特征),那么这里的消息传递的公式就是在问你:
我给你一个节点v,和节点v的一阶邻节点的节点特征,以及节点v和节点u之间的边的特征,你要通过什么方式去给节点v生成新的节点特征的表征?
这里的设计就可以根据数据的情况非常的灵活了,比如edge的特征里有连续和离散变量,怎么在传播的过程中把这些特征考虑进来等等,目前暂时没有遇到这么棘手的情况,所以还是讨论简单的情况,在graphsage和GCN中,消息的传递方式非常简单,就是直接传递,也就是简单的copy操作,将v的一阶邻节点u的特征hu,copy一份出来,如果edge存在权重,则copy的结果需要乘上相应的权重,同时,v节点的特征也copy一份出来。
(为了方便描述,拉普拉斯矩阵标准化放到后面讲)
比如说 v的特征为[1,2,3,4,5],其一阶邻节点 u的特征为[0,1,2,3,4],[1,3,5,7,9],[2,4,6,8,10](假设v只有三个一阶邻节点),权重分别为[1,2,3],则我们的消息传递的最终结果为[1,2,3,4,5],[0,1,2,3,4],[2,6,10,14,18],[6,12,18,24,30];
2、聚合计算
聚合计算是GNN最核心的部分,也是GNN能够支持不规则的图数据的原因,其实nn解决不规则输入的方法有很多,比如bert里,简单的使用cls处的输出作为任务层的输入,这样无论输入句子的长度是多少,最终都统一为cls部分的固定的向量的长度,而sentence bert里提到,也可以对输出进行mean pooling处理,这里的mean pooling就是一种很常见的解决不规则输入数据的方法,因为无论输入的文本长度是多少,pooling之后的sequence的长度都变成1了,比如[[1,2,3,4],[1,3,2,4]]和[[1,2,3,4],[1,3,2,4],[1,2,3,4],[1,3,2,4],[1,2,3,4],[1,3,2,4]],无论输入长度多少,最后都给pooling变成了[X,X,X,X]的这样的形式了。
这里GNN的聚合计算也是起到一样的效果,无论节点的一阶邻节点有多少,统一用类pooling的方式处理成一样的就完事儿了。聚合计算的公式可以表示为:
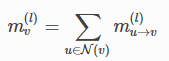
注意,这里的聚合计算不仅仅是求和一种,还有非常多其它的方法,只要保证能够达到“九九归一”的效果的方法,都可以作为聚合计算的方法。
这里其实就非常灵活了,因为节点v的邻节点u们构成的输入形式是:
[[x,x,x,x],[x,x,x,x],[x,x,x,x]]
这明显就是一个sequence数据的形式,只不过是无序的sequence,这样的话很多处理sequence的方法都可以用进来,比如用LSTM(但是因为输入是无序的,所以要对sequence进行多次shuffle,避免LSTM学习到无意义的顺序信息),1X1卷积,cnn中的各种pooling 层,或者是像GAT一样这里加个attention等等
在graphsage中聚合计算就是简单对节点v的一阶邻节点做了mean pooling
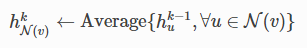
而gcn中,用的是sum,并且这里的sum的过程中把节点v自身的feature也放进去做sum 计算了。
3 更新的计算:
比如像graphsage处理之后,我们得到了节点v的原始特征[1,2,3,4,5]和它的一阶邻节点的聚合计算之后的特征[x1,x2,x3,x4,x5],现在我们要做的就是利用节点v的原始特征和其一阶邻节点的聚合之后得到的特征,来得到节点v的新的更高阶的表征,这里的设计也可以非常灵活,比如graphsage中:
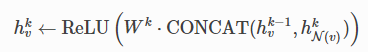
就是用的一个简单的全连接层+relu的激活函数来实现更新的,这里数据的输入形式就是两个向量[1,2,3,4,5]和[x1,x2,x3,x4,x5],然后就可以放飞想象,考虑看怎么对这两个向量进行各种奇怪的变换,比如两个向量加权求和,两个向量做元素积等等。
而GCN中更简单,在聚合计算阶段直接对节点v和其邻居u一股脑全部sum计算了一下,然后就只得到[x1,x2,x3,x4,x5]这样的形式的向量,然后接wk+激活函数就完事儿了。
GNN的半监督体现在消息传递和聚合计算的部分,因为节点v的最终的表征使用了其一阶邻节点的特征,整个计算过程不需要使用节点的标签,实现了有监督训练使用无监督样本信息的目的,因此GNN被称为可以实现半监督分类之类的,同时,整个过程中,无监督样本的表征也得到了学习,比如这里:
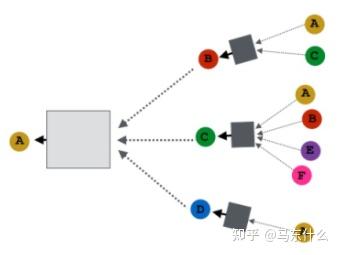
假设只有A是有标签的,则在有监督训练的过程中,
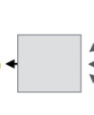
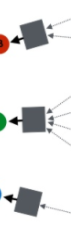
这两个地方的参数保留了下来,这里的参数保存了GNN 学习了标签和所有样本特征得到的精华信息,从而帮助提升无标签样本的预测准确度。类似于bert先用mlm,使用所有样本训练提取无标签和有标签样本的特征,然后用有标签样本做finetune效果会更好类似,只不过GNN中,这个过程是天然同时进行的。
2 关于拉普拉斯矩阵的标准化问题
这个问题我也挺懵逼的,因为一开始接触的是node2vec,输入数据的形式就是变形后的邻接矩阵,

如果edges有权重,则邻接矩阵中对应的1用实际的权重来代替就完事儿了。
在nodevectors中的实现也是采样这种形式的输入数据:
不过其实这种把edge信息放到邻接矩阵里的设计并不好,因为如果edges的信息不仅仅有权重,则这种方式就没法表达了,(不过也正常,常规的node embedding也用不上更丰富的信息,这样反而还能节省一些内存占用不需要额外的空间存储edge的信息了),node2vec其实没涉及到把邻接矩阵做标准化,顶多就对edge weights做归一化处理,所以为啥GNN这边要把邻接矩阵转成归一化拉普拉斯矩阵?
这个是GCN论文里的公式,
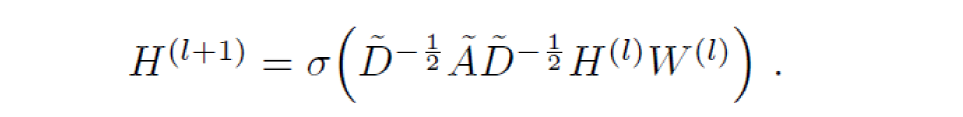

这里的A其实不是简单的0,1 这样的形式,而是带权重的,也就是edge的weight实际上是体现在A里面的。
关于这点,dgl的gcn的设计里也提到了:
>>> import dgl
>>> import numpy as np
>>> import torch as th
>>> from dgl.nn import EdgeWeightNorm, GraphConv
>>> g = dgl.graph(([0,1,2,3,2,5], [1,2,3,4,0,3]))
>>> g = dgl.add_self_loop(g)
>>> feat = th.ones(6, 10)
>>> edge_weight = th.tensor([0.5, 0.6, 0.4, 0.7, 0.9, 0.1, 1, 1, 1, 1, 1, 1])
>>> norm = EdgeWeightNorm(norm='both')
>>> norm_edge_weight = norm(g, edge_weight)
>>> conv = GraphConv(10, 2, norm='none', weight=True, bias=True)
>>> res = conv(g, feat, edge_weight=norm_edge_weight)推荐使用这种方式来构建模型,graphconv的部分norm就设置为None,edge的weight的标准化用EdgeWeightNorm来实现就行了,否则源代码里,你跑一个全图,就要计算一次标准化之后的edge weight,非常的麻烦且耗时,但是这里的设计也是没有办法,因为原始的GCN是不直接支持batch 训练的,每次跑必须全图,因为你的edge weight的标准化处理需要使用到整个图的度矩阵。
为了解决这个问题,dgl中的实现是:
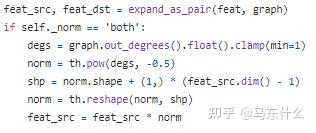
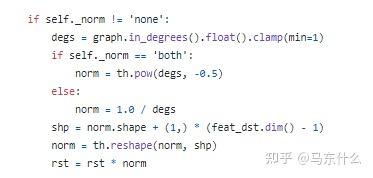
每跑一个batch都重新算一次。。
扯远了。。这里其实想说的是:
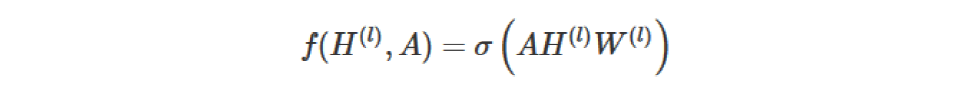

公式中的A是包含了edge weight的情况其实,所以其实邻接矩阵转化为归一化拉普拉斯其实就是对edge weights做标准化,只不过很多例子里都是用的无权图,默认权重都为1,所以看起来好像跟edge实际的weight没啥关系。
那么这种情况下,对于上面描述的GNN的消息传递,聚合和更新的过程而言,我们的输入应该是加入了自环的邻接矩阵(要加入自身信息嘛,所以加了个自环),大概长这样:
【1,0.5,0.0,0.0,0.0】
【3,1,0.25,1.4,2.5】
【4,2,1,1.5,3.6】
【0.7,1.5,3,1,5】
【1.5,2.5,3.5,3,1】
这样的输入数据其实就已经满足了GNN的输入数据的形式了,你直接用这个数据来跑GCN或者graphsage,程序运行不会有什么问题。
那么到底为啥要这么做啊。。。
首先,我们需要理解这种带权重的邻接矩阵扮演的角色,假设节点1在邻接矩阵中的向量为
【1,0.5,0.0,0.0,0.0】
则消息传递的过程中,我们得到了节点1和节点2的feature,[x11,x12,x13,x14...]*1=[x11,x12,x13,x14...],[x21,x22,x23,x24.....]*0.5=[0.5*x21,0.5*x22,0.5*x23,0.5*x24.....],这里的1和0.5代表了邻接矩阵里对应的具体的值,然后进入下一步的聚合计算
这么做有两个问题,
A、在现实世界的图数据中,尤其是社交网络数据,节点的度分布是非常畸形的,
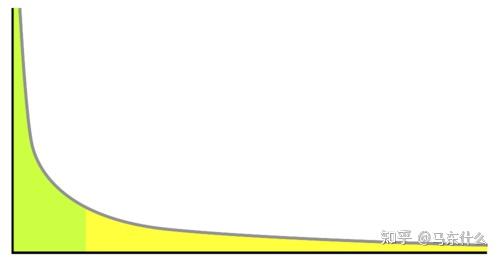

大部分节点的一阶邻节点数量很少,只有极少一部分超级节点具有大量的一阶邻节点;
B、不同节点之间的edge权重的分布也可能是非常畸形的,比如可能某两个节点之间的edge weights=10000,而其它节点之间的weights在1~10的范围;
这两个问题会导致:
1、在简单的无权图中,节点的度呈现幂律分布导致nn的收敛困难:
当我们使用GCN的时候,简单的sum聚合方法有非常明显的问题,某个超级节点sum之后的结果的量纲显然会大大超过普通节点的sum结果,这就导致了后面的linear变换面对的输入数据的量纲差异很大的问题,其结果类似于你用普通的dnn在没有做标准化的数据上训练导致难以收敛的问题很类似,但是还是存在本质不同。
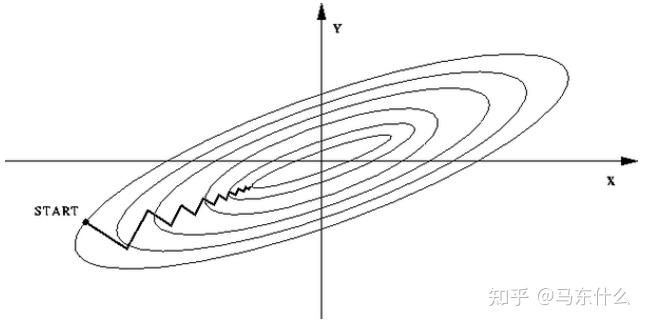
常规的比如dnn里,输入多个特征
如果不标准化,那么特征的量纲不同,其目标函数就会呈现这种情况,也就是扁的:

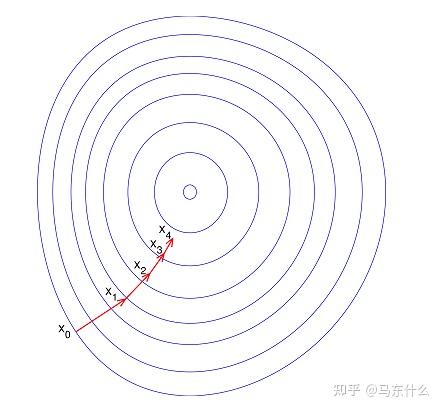
如果进行了归一化,那么目标函数就会比较圆:

但是在这里,GNN面临的问题在于不同节点的聚合计算之后的高阶特征的量纲差异大(当然,这里我们事先也需要对node feature做标准化处理)都不尽相同,
为了便于说明,假设有100万个nodes,每个node的feature均为[1,2,3],edge weight均为1,度服从幂律分布,则某个超级节点在邻接矩阵中对应的“邻接向量”为:
[1,1,1,1,1,1,1,......1](100w个1,即超级节点和所有节点都直接连接)
和一个普通的节点
[0,1,1,1,1,0,......,](4个1,其它都是0)
则我们进行聚合计算的时候,比如GCN中直接sum节点v和其邻节点的features,则超级节点得到的聚合计算的结果为【100万,200万,300万】,而普通节点的聚合计算的结果为[4,8,12],显然这就导致模型很难收敛到一个恰当的值可以同时满足差异这么大的样本。。。比如说[4,8,12]这样的样本对应的linear层的weights的权重的大小在0~1之间就可以满足条件,而【100万,200万,300万】的weights的权重大小要在0.000000~0.000001这样的量级才能满足条件,这使得nn很为难,找不到一个合适的权重来同时满足量纲差异这么大的不同样本的输入。
这里的问题和时间序列预测中的不同商品的序列数据的标准化问题非常相似,不同商品的销量数据可能不在一个量纲上,比如热门商品的销量是[10000,20000,30000,40000,50000],而冷门商品的销量是[1,2,3,4,5],我们要使用一个全局的深度时间序列模型来拟合,必须做分组标准化处理,将不同的商品的销量转化到同一个量纲上才可以 ,和特征标准化不同,常规的特征标准化是纵向标准化,即按列做标准化,而这里需要做的标准化是横向标准化,即按行进行处理(类比于batch norm和layer norm),所以简单直观的处理方式就是,做横向标准化,例如上面的例子 【100万,200万,300万】经过标准化处理为【100万/600万,200/600万万,300万/600万】,[4,8,12]经过横向标准化处理为[4/24,8/24,12/24],可以保证输入样本的大小在同一个量级内从而帮助nn收敛;
好了,到此为止,我们实际上已经完成了由邻接矩阵和度矩阵向random-walk normalized 拉普拉斯矩阵的的处理:
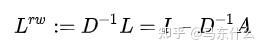
同时我们观察一下归一化的矩阵与特征向量矩阵的乘积:
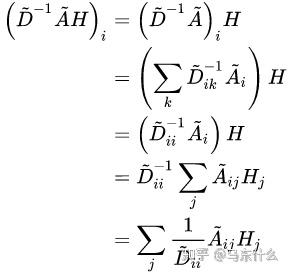
这种聚合方式实际上就是在对邻接求和取平均。Dii表示节点i的度的大小。注意,当我们处理的是无权图时,进行random-walk normalized 拉普拉斯矩阵处理,在计算上和直接在聚合计算的时候使用mean计算是等价的。
它的物理意义很简单如上所述。
2、在简单的有权图中,权重的畸形分布也会导致训练问题:
现在考虑另一种极端的情况,假设节点的度呈现均匀分布,再极端一点,每个节点的邻节点数量完全相同,但是节点和节点之间的权重的分布差异很大,即有权图的情况下,简单的横向标准化策略就莫得行了,假设一共存在5个节点,其中节点A 的邻接向量[1,1,1,1,1],节点B的邻接向量[1,1,1,1,1000000],每个nodes的features均为[1,2,3],可以看到节点A和节点B的邻居的数量是相同的都是4,加上自身一共5个节点,但是二者的edge的权重差异很大,以graphsage为例,节点A的更新计算为 wk * concat([[1,2,3],[1,2,3]]),节点B得到的更新计算为 wk* concat([[1,2,3],[250075,500150,750225]), GG。这里如果进行横向标准化处理(即random-walk normalized 拉普拉斯矩阵)没法很好的解决这个问题,[1,1,1,1,1000000]进行横向标准化之后,1的部分几乎等于0可以忽略不记,最终节点B的更新计算约等于:wk* concat([[0,0,0],[0.250075,0.500150,0.750225]),原节点自身的特征基本忽略不计了,如果像GCN一样直接求sum,结论类似。
这种情况,其实就不属于标准化能够处理的范畴了,类似于我们在做数据预处理的时候,某个特征里存在着异常值的问题,无论是基于随机游走的拉普拉斯矩阵标准化还是后面会提到的对称归一化拉普拉斯矩阵,其实都没法解决这个问题,因为权重的极端分布其实更像是数据异常值的问题,需要在预处理的时候,对这部分权重进行处理,处理的思路和在使用常规nn训练遇到特征存在异常值的思路一样,因为nn不像gbdt那样,对于异常值并不鲁棒,所以这部分需要放在图数据的预处理上来做,归一化解决不了这个问题的。
3、节点v的不同邻节点u对节点v的贡献度应该是不同的
这个其实很好理解,比如说,在脉脉上,算法工程师A可能就认识算法工程师B和算法工程师C,而其它的好友可能几乎都是猎头,算法工程师B和C的情况可能也差不多,那么假设我们希望做一个基于GNN的节点分类模型,无论是graphsage还是GCN的处理,都没有办法很好的突出算法工程师A真正的朋友(GAT引入注意力机制是make sense的),对于算法工程师A来说,算法工程师B和算法工程师C的node features对算法工程师A的节点分类帮助要大得多,而猎头的贡献要小得多。这个时候,基于随机游走的拉普拉斯矩阵标准化帮不上忙,很简单,我们做横向归一化仅仅使用了节点i本身的度,压根也没有考虑其邻节点的任何特性。
这个时候,就要有请对称归一化拉普拉斯矩阵了:
上图来源于GCN的论文,这个公式有一个更好看的形式(这里W表示的是linear层的权重,可忽略,矩阵乘法交换律):
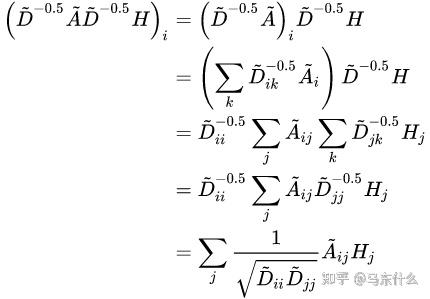

从上述公式可以看到,这里的标准化考虑了节点vi和其邻节点vj两个节点的度来进行标准化。即vi的度和它的邻居vj的度。上面的公式的第一项:
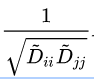
可以进一步变形为:
\sum_{j}^{}{\frac{1}{\tilde{D_{ii}}}*\frac{\sqrt{D_{ii}}}{\sqrt{D_{jj}}}}
可以看到,对称归一化拉普拉斯矩阵做了两件事,一件事就是完成了前面的random-walk normalized 拉普拉斯矩阵所做的横向标准化的操作,第二件事是做了加权。重点在于这后面的加权项,
这里的思想和tfidf是非常相似的,如果节点j的度很大,说明节点j和其它许多节点的也存在关联,则节点j对于节点i的角色的判定(比如节点分类问题)就不是那么重要了,比如猎头和许多不同行业的从业者有通讯关系,因此猎头对于某个从业者的职业的判定起到的贡献是比较低的。显然可以看到,如果节点j的度很小,则这个节点j相对于节点i来说就更重要,反之则不重要。
(这里需要补充一个知识点,在无权图中我们一般直接计算节点i的邻节点数量得到deg(vi)即degree(vi),但是在加权图中,更好的做法是计算和节点i想连接的edge的权重之和,即加权度,在dgl中,计算过程中有权图的degree实际上用的是加权度)。
这是一个非常有意思的变换,这种变换的含义在于对节点i的每个邻节点j,对于节点i的“贡献“进行了标准化,打一个不是很恰当的比喻,比如有两个男生同时喜欢你,其中一个男生这辈子就没谈过恋爱,另一个男生是个海王,那么明显,没谈过恋爱的男生对你的爱的分量更重,现在又有三个海王喜欢你,海王一号同时有三个女朋友,海王二号同时有五个女朋友,海王三号同时有七个女朋友,则此时,我们可以通过对称归一化拉普拉斯矩阵来对每一个男生对你的爱进行标准化处理。
关于GCN的一些缺陷问题:
1.直推式(transducive):无法直接泛化到新加入(未见过)的节点,为新节点产生embedding需要额外的操作;
所谓直推式,直接以word2vec进行对照就可以了,word2vec就是一个典型的直推式算法,直推式的模型无法直接对新的训练期间未存在的样本进行预测,这是模型本身的设计思路所导致的。GCN之所以说被是直推式的,核心的原因在于原论文中对输入的矩阵做了对称归一化的拉普拉斯矩阵变换,
这里的A和D都是根据训练的数据而固定下来的,当出现新节点的时候,D和A就会发生变化,这就导致了预测时候的graph和训练的graph的A,D不一样的问题,即训练的数据分布和预测的数据分布存在差异。
但是程序上运行没啥问题其实,因为训练结束之后,GCN最后得到的结果就是上图的两个方框中的权重,只要节点不是孤立的,有对应的nodes features,跑起来没啥问题。
2.没法分batch:
这块儿我其实挺懵逼的,跑代码没啥问题。。。问了一下群里的大佬,操作可以,就是理论上可能无法解释,无奈谱视角看GNN我实在不想劳神研究,pass
3.基础GCN是基于无向图的
这个问题dgl中的解决方法是,
这里的D分别使用出度的度矩阵和入度的度矩阵来进行计算从而实现基于有向图的GCN。
