深度学习图像去噪有许多许多的算法,能否一一由时间线简单介绍下,以便更好的入门?

FFDNet的代码链接:https://github.com/cszn/FFDNet
简单介绍:作者是在DnCNN和FFDNet的基础上进行改进,受张凯大神的启发,提出了两阶段的盲去噪模型。
2.相关工作
本节主要介绍了DnCNN的模型以及其改进模型
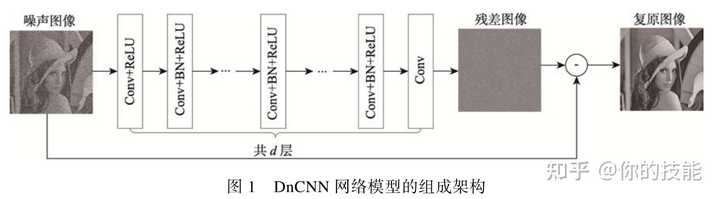
2.1DnCNN的降噪模型
首先对DnCNN的模型进行介绍。第一层利用卷积层对输入图像进行处理,并利用ReLU激活函数赋予网络的非线性能力。从第2~d-1层,在conv和ReLU层之间加入批量归一化(BN)操作,主要是减少内部协变量转移对网络的参数选取的影响,加快网络模型的收敛速度。

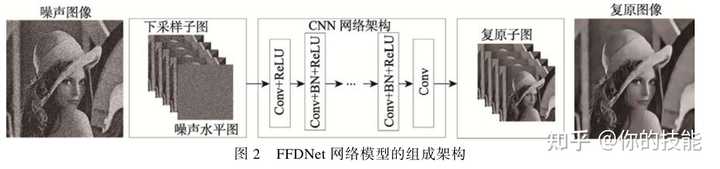
2.2FFDNet的降噪模型
与DnCNN通过残差学习获得残差图像不同,FFDNet是将噪声图像作为网络的输入,在进行非线性映射之前,采用下采样算子将大小为 W\times H\times C 的输入图像下采样生成对应的4张大小为 W/2\times H/2\times 4C 子图像,在最后一层则采用上采用将子图像重构成大小为 W\times H\times C 的降噪图像。上、下采样的引入加快了网络的训练速度,仅此而已。另外,引入了1张大小为 W/2\times H/2 的噪声水平映射图,将其与上下采样子图连接成一个大小为 W/2 \times H/2 \times (4C+1) 的张量作为网络的输入,使得网络只需要训练一次,就可以处理任意噪声水平的图片,提高了网络的灵活度。

3.两阶段盲卷积降噪模型(本文所提方案)
第一阶段:针对给定的受0~90%范围内的某个水平噪声干扰的图像,利用DnCNN-B进行初步降噪,同时,利用噪声检测模型预测出噪声图像相应的噪声标签,在将图像与标签按位相乘,生成稀疏图像。
第二阶段,将第一阶段获得的初步降噪图像和稀疏图像连接后再次输入预先训练好的双通道图像质量提升模型获得残差图像,用用初步降噪图减去残差图获得最终的降噪图。
优点:(1)在第二阶段执行之前,利用噪声检测模型准确地判定待降噪图像中噪声像素点位置;同时,初步降噪图在SSI稀疏采样图像辅助下输入去噪网络,极大地提升了网络的降噪能力。
(2)使用方便。训练一旦完成,就可以在无需人工参与的情况下,去除全范围内的噪声。
(3)执行效率高。与传统开关型降噪模型相比,我们采用CNN网络模型,不需要反复迭代操作。
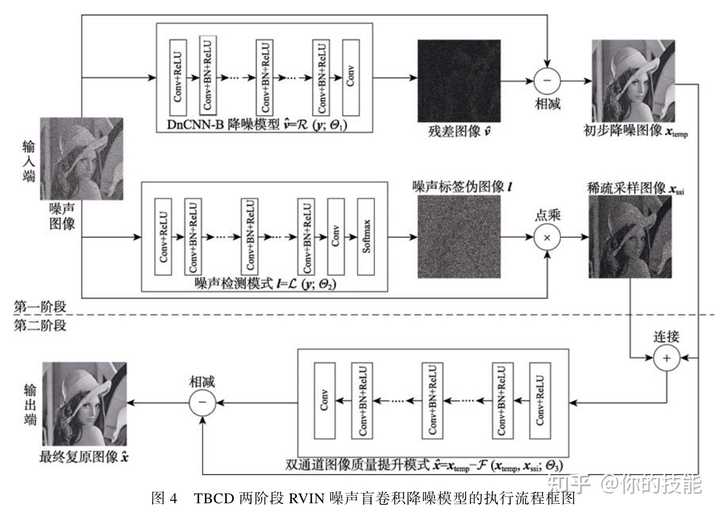

DnCNN降噪子模型:这里直接使用张凯大神的DnCNN-B模型进行全范围降噪,获得的性能会劣于针对特定噪声水平训练的DnCNN-S模型。
噪声检测子模型:FFDNet降噪模型的性能相对于DnCNN有所提升的一点在于设计了噪声水平映射图,预先将噪声水平作为先验知识。本文根据RVIN的特点,设计能反映出RVIN噪声信息的SSI稀疏采样图像,用“0”标记噪声点,用“1”标记正常像素点。本文用噪声标签矩阵和噪声图像做点乘,获得稀疏图像,在DnCNN-B的最后一层加一个softmax层来实现噪声的判定。
双通道图像质量提升模型:其实就是张凯大神的模型,只不过作者在第一个Conv层使用的是64个大小为 3\times 3\times 2 的滤波器,这里的2就是通道数。
最后作者进行了消融实验,分析了各个子模块在网络中的作用。
文中还有一段有趣的叙述:“当测试图像的噪声比例值 testr 与训练图像集合中所添加的噪声比例值 trainr 相等时,才可以获得最好的降噪效果;当 testr 和 trainr 不匹配时,降噪效果则会存在不同程度的下降.”这可能是个常识,但没有人证明过,作者给出了证明。