为什么随机梯度下降方法能够收敛?
在解决大规模机器学问题的时候,通常梯度下降法因为计算开销过大,而被随机梯度下降法取代,每次只使用一个数据样本来寻找梯度下降方向。一直没有搞清随机梯度下…
关注者
928被浏览
215,690登录后你可以
不限量看优质回答私信答主深度交流精彩内容一键收藏

知乎用户
1 背景
梯度下降算法是目前最流行的优化算法之一,并且被用来优化神经网络的模型。业界知名的深度学习框架TensorFlow、Caffe等均包含了各种关于梯度下降优化器的实现。然而这些优化器经常被用作黑盒使用,而无法对这些优化算法的优缺点以及适用场景没有一个全面而深刻的认知,可能造成无法在特定的场景使用最优解的情况。
这篇文章主要对各种梯度下降优化算法进行全面成体系的分析,帮助相关的算法开发人员在模型开发的过程中选取合适的优化器。所以整个内容会比较多,将要分成几个章节进行分析,以下是初步的章节情况,本章会介绍下梯度优化的衍生变体以及模型训练的难题和挑战,后续章节会针对相关挑战讲解各种业界前沿的优化器。

梯度下降法的目标是在梯度的相反方向进行模型参数的更新,从几何学来说,就是沿着斜率的方向(最快)由目标函数创建的曲面一直向下直到山谷,并且通过合理的步长设置加快与稳定算法模型的收敛,训练出泛化更强的模型。更加形象化的理解是这样:我们从山上的某一点出发,找一个最陡的坡走一步(也就是找梯度方向),到达一个点之后,再找最陡的坡,再走一步,直到我们不断的这么走,走到最“低”点(最小花费函数收敛点)。基于此,相关科研人员针对该算法进行了广泛而深度的研究。
相关符号:
- 模型的代价函数:J(\theta)\\
- 模型的相关参数:\theta \in R^d\\
- 参数的梯度:\bigtriangledown_{\theta}J(\theta)\\
- 参数的梯度:\eta\\
2 梯度下降衍生变体
梯度下降法有三个衍生变体,不同之处仅仅在于对样本数据的处理方式。具体来说,就是基于参数更新的准确性与计算性能之间的考量,进而每次模型迭代使用的数据量的大小有所差异。
2.1 批量梯度下降 Batch Gradient Descent
- 定义
每次迭代使用整个数据集,计算代价函数的梯度,进行模型参数的链式求导更新,公式如下: \theta = \theta - \eta * \bigtriangledown_{\theta}J(\theta)\\
- 算法描述
BGD算法需要使用全部样本数据进行迭代,所以对于样本可以进行多轮充分的学习,获取全局最优解,不会由于个体样本的信息噪声,造成模型的大的偏差与震荡,不过对于资源消耗是较大的,尤其是互联网的海量数据的情况下。
for i in range ( nb_epochs ):
params_grad = evaluate_gradient ( loss_function , data , params )
params = params - learning_rate * params_grad
- 算法优缺点总结:
- 优点:全局最优解,易于并行实现;
- 缺点:当样本数目很多时,训练过程会很慢,并且需要非常大的内存,无法进行Online Learning。
- BGD的收敛图
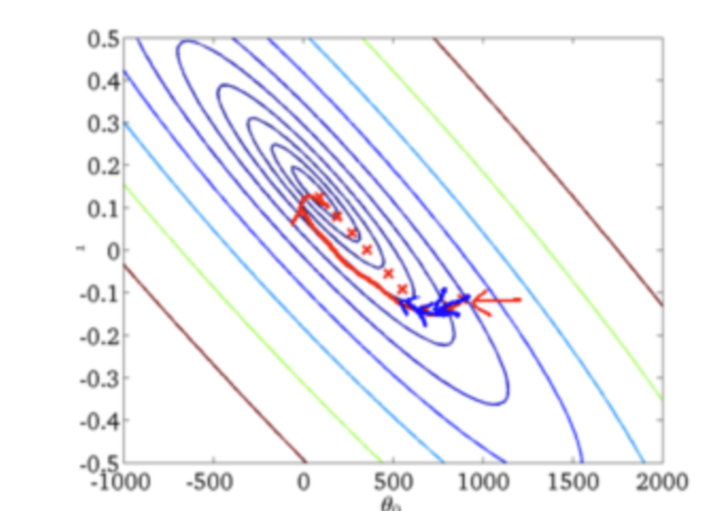

2.2 随机梯度下降 Stochastic Gradient Descent
- 定义
每次迭代使用一个样本,计算代价函数的梯度,进行模型参数的链式求导更新,公式如下: \theta = \theta - \eta *\bigtriangledown_{\theta}J(\theta; x^{(i)};y^{(i)})\\
- 算法描述
随机梯度下降是通过每个样本来迭代更新参数一次,对比BGD的迭代一次需要用到所有训练样本(往往如今真实问题训练数据都是非常巨大)多次数据集全局迭代。SGD每次迭代的计算与存储要求都非常的少,每轮迭代次数非常快,但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向,所以出现模型的反复震荡。
for i in range ( nb_epochs ):
np.random.shuffle ( data )
for example in data :
params_grad = evaluate_gradient ( loss_function , example , params )
params = params - learning_rate * params_grad
- 算法优缺点总结
- 优点:训练速度快,资源占用少,不集中占用资源。
- 缺点:准确度下降,并不是全局最优,不易收敛;不易于并行实现。
- SGD的收敛图
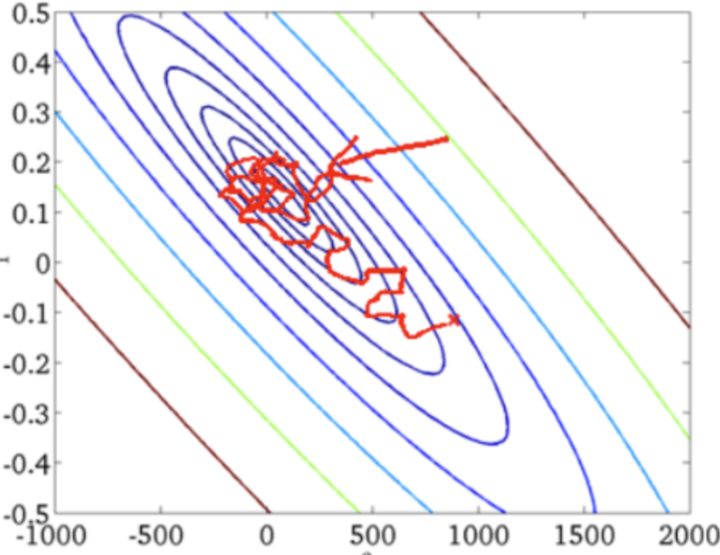

2.3 小批量梯度下降:Mini-Batch Gradient Descent
- 定义
每次迭代使用一个样本,计算代价函数的梯度,进行模型参数的链式求导更新,公式如下: \theta = \theta - \eta * \bigtriangledown_{\theta}J(\theta; x^{(i:i+n)}; y^{(i:i+n)})\\
- 算法描述
BGD每次迭代都要使用到所有的样本,对于数据量特别大的情况,如超大规模数据的机器学习应用,每次迭代求解所有样本需要花费大量的计算成本。而SGD每次迭代都是只使用所有样本中一个进行模型更新,噪声较多,造成模型震荡,并且不利于并行等。那么是否可以在每次的迭代过程中利用部分样本代替所有的样本呢?基于这样的思想,便出现了mini-batch的概念。
for i in range ( nb_epochs ):
np.random.shuffle ( data )
for batch in get_batches ( data , batch_size =50):
params_grad = evaluate_gradient ( loss_function , batch , params )
params = params - learning_rate * params_grad
- 算法优缺点总结
- 优点:内存利用率提高,大矩阵运算的并行化效率提高。 跑完一个epoch所需的迭代次数减少,对于相同数据量的处理速度进一步加快。 在一定范围内,一般来说 BatchSize 越大,其确定的下降方向越准,引起训练震荡越小。
- 缺点:内存利用率提高了,但是内存容量可能撑不住了,需要进行权衡。
本质属于BGD与SGD的折中方案,解决BGD的训练速度慢,以及随机梯度下降法的准确性,但是这里注意,不同的场景需要算法人员对BatchSize进行调参,没有一个确定的参数方案,这个可能就要靠经验和实验了,就像是一个神经网络模型到底要有多少个隐层一样,没有固定的答案。不过在模型的训练过程中,会发现要想达到相同的精度,其所花费的BatchSize 增大到一定程度,其确定的下降方向已经基本不再变化,并且随着BatchSize的增大,内存压力也大,所以并不是越大越好,需要经过实践的检验。
3 模型训练的挑战与难题
- 选择合适的学习速率可能是困难的。学习速率太小会导致收敛速度慢得令人痛苦,而学习速度过大则会阻碍收敛,并使损失函数在最小值附近波动甚至发散。
- 在训练期间尝试调整学习速率,即根据预先设定的学习率表在相应epoch或阈值时调整学习速率,然而提前定义的学习率,无法适应数据集的特征分布的动态变化。
- 同样的学习率可能不适用所有的参数更新。如果我们的数据稀少或者我们的特性有非常不同的出现频率,可能不想以相同的频次进行更新,而是对较少频率出现的特性执行较大的更新更快。
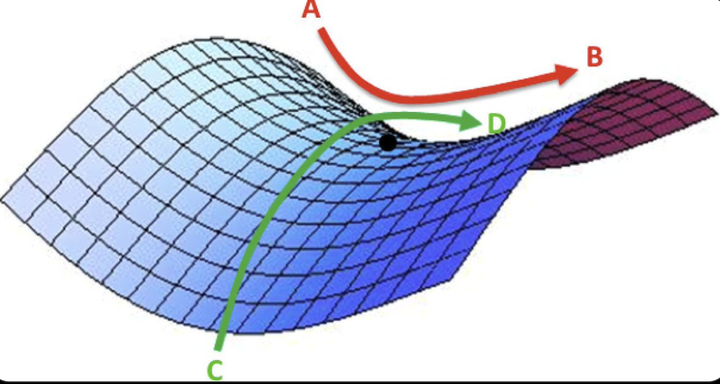
- 神经系统常见的问题是非凸,使得网络非常容易陷入最优局部最小值中。另外不仅仅有局部极小值困扰,还有鞍点,(即一个维度向上倾斜,另一个维度向下倾斜的点,而在鞍点出的梯度为零)。这使得模型非常困难从这些鞍点逃出。(下面两个图分别表示局部最优和鞍点)
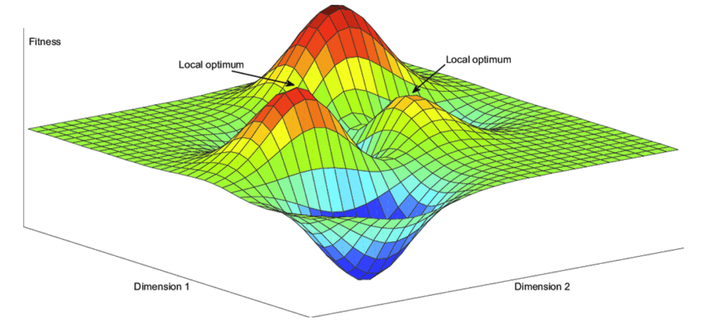


4 参考资料
- An overview of gradient descent optimization algorithms∗ https://arxiv.org/pdf/1609.04747.pdf
5 未完待续
敬请期待后续章节。