
HMM词性标注实战

大纲
- hmm原理
- 任务描述
- 具体代码分析
- Github地址
hmm原理
任务描述
标注英文句子中每个单词的词性,属于HMM任务中的Inference/Decoding过程( X->Z )。
具体代码分析
数据traindata.txt
/前面表示的是单词 即HMM模型中的观察值X
/前面表示的是词性 即HMM模型中的隐状态Z


读取数据初始化字典
word2id,id2word = {},{}
tag2id,id2tag = {},{}
for line in open("traindata.txt"):
item = line.split("/")
word, tag = item[0], item[1].rstrip()
if word not in word2id:
word2id[word] = len(word2id)
id2word[len(id2word)] = word
if tag not in tag2id:
tag2id[tag] = len(tag2id)
id2tag[len(id2tag)] = tag#初始化pi 转移矩阵 发射矩阵
import numpy as np
N = len(tag2id)
M = len(word2id)
pi = np.zeros(N)
A = np.zeros((N,N)) #观测矩阵
B = np.zeros((N,M)) #状态转移矩阵# 统计参数
单词为.表示一个句子结束,即将开始一个新的句子
prev_tag_id = -1
for line in open("traindata.txt"):
item = line.split("/")
word, tag = item[0], item[1].rstrip()
word_id,tag_id = word2id[word],tag2id[tag]
if prev_tag_id == -1:#句首
pi[tag_id] += 1
B[tag_id][word_id] += 1
else:
B[tag_id][word_id] += 1
A[prev_tag_id][tag_id] += 1
if word == ".": #表示句子结束了
prev_tag_id = -1
else:
prev_tag_id = tag_id# 转换成概率
pi = pi / sum(pi)
for i in range(N):
A[i] /= sum(A[i])
B[i] /= sum(B[i])#log 函数
def log(v):
if v == 0:
return np.log(v + 0.000001)
return np.log(v)#使用Viterbi获得最好的状态路径
def viterbi(observe, pi, A, B):
x = [word2id[value] for value in observe.split(" ") if value in word2id]
T = len(x)
dp = np.zeros((T, N))
ptr = np.zeros((T, N), dtype=int)
#初始化状态
for j in range(N):
dp[0][j] = log(pi[j]) + log(B[j][x[0]])
for i in range(1,T):
for j in range(N):
prob, k = max([(dp[i-1][k] + log(A[k][j]) + log(B[j][x[i]]), k) for k in range(N)])
dp[i][j] = prob
ptr[i][j] = k
# best_seq = np.zeros(T)
best_seq = [0] * T
best_seq[T-1] = np.argmax(dp[T-1])
# 根据下一步推断上一步的状态
for i in range(T-2, -1, -1):
best_seq[i] = ptr[i+1][best_seq[i+1]]
for i in range(T):
print(id2tag[best_seq[i]])ptr[i][j] = k 表示将对应于当前状态的最好的上一个状态的Id存储下来
上面代码中路径回溯比较难以理解, 我们画个图
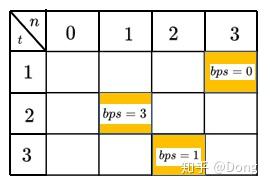
上图表示代码中的ptr矩阵 ,bps(best prev state)表示当前时刻最好的上一状态
假设我们计算到最后值最大的状态为2时,即 np.argmax(dp[T-1]) = 2
我们从ptr矩阵可得它的最好的上一状态是1,即ptr[3][2] = 1,同理可知ptr[2][1] = 3
ptr[1][3] = 0,上图中的黄框即为最好的状态转移过程 即为0->3->1->2
# best_seq = np.zeros(T)
best_seq = [0] * T
best_seq[T-1] = np.argmax(dp[T-1])
# 根据下一步推断上一步的状态
for i in range(T-2, -1, -1):
best_seq[i] = ptr[i+1][best_seq[i+1]]
for i in range(T):
print(id2tag[best_seq[i]])这段代码就是做的这个事情
#main函数调用
if __name__ == "__main__":
x = "keep new to everything"
viterbi(x, pi, A, B)
print("\n")
# x = "it is amazing"
# viterbi(x, pi, A, B)结果展示
"keep new to everything"

Github地址
发布于 2020-01-10 15:35