ECCV2020:probabilistic anchor assignment (PAA)

论文阅读:Probabilistic Anchor Assignment with IoU Prediction for Object Detection
文章代码:
论文地址:
这篇文章主要是针对当下anchor-based model中anchor标签的分配问题加以改进,传统的方法是计算bounding box与target box之间的IOU,如果这个值大于正阈值,那么将其作为正样本,小于负样本阈值则将其作为负样本,其余的忽略。这样做有几个缺陷
- 忽视了bounding box本身的内容,bbx和target的交集本身可能会包含大量的背景噪声。
- 在测试阶段是没有target,无法计算IOU,造成了测试阶段和训练阶段的不一致。
这篇文章针对存在的问题提出了一个给anchor分配标签的概率模型,和一个后处理的方法,主要优势如下:
- 分配标准取决于分类精度和IOU的组合,而不单单取决于IOU,这对model的增益更大(focus分类精度使得这个metric可以考虑box本身的内容)。
- 通过混合高斯分布对正负样本进行建模,可解释性强。
- 丢掉了IOU阈值,正样本数目等超参数,模型更稳定。
- 通过修改网络结构对box与GT的IOU进行预测,训练阶段有真实的IOU作为label,测试阶段可以预测IOU,使得训练和测试阶段保持一致。
接下来从各个部分对文章进行刨析
Probabilistic Anchor Assignment Algorithm
这一部分是文章的重点,使用如下公式计算每一个anchor的得分情况
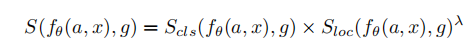

S_{cls},S_{loc},f_\theta,a,x,g 分别是分类,定位得分,参数为 \theta 的model,anchor,输入图片,ground truth。也就是说这个得分公式其实是和model的参数有关的。分类得分很容易算(就是分类分支的输出),定位得分通过IOU计算,然后使用最大似然进行优化
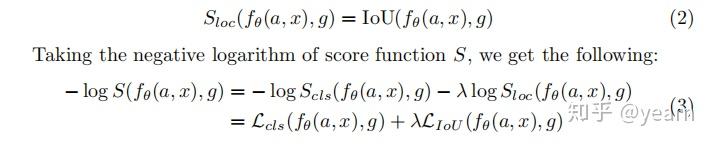

得到分类损失和定位损失,前者通过二元交叉熵损失计算,后者通过IOU损失计算(1-IOU)。
我们将anchor的分数(实际上在源码中传入的是anchor的cls损失和bbx损失的加权和,也就相当于score的反面吧,不过对于GMM来说二者差别不大)作为从概率分布中抽取的样本,并最大化分数的最大似然(通过调整分布的参数),然后对每个anchor我们就能得到它属于正,负样本的概率了。
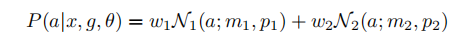

最基本的一维二元高斯混合模型,给定一组anchor的分数,这个GMM的可能性可以使用期望最大化(EM)算法进行优化,可能有些同志不熟悉EM算法(就像我这种菜鸡),所以这里简单写一下步骤
- 输入一组anchor,他们各自有个分数,给negative,positive的高斯模型分别初始化参数。(至于输入的anchor)
- 计算每个anchor的分数分别属于negative,positive分布的概率 P_{neg}(a,\theta,g),P_{pos}(a,\theta,g) (Expectation)。
- 通过概率加权和重新计算每个分布的参数,比如 m_1=\frac{\sum_{i}^nP^{pos}_iS_i}{\sum_{i}^nP^{pos}_i} (Maximization)
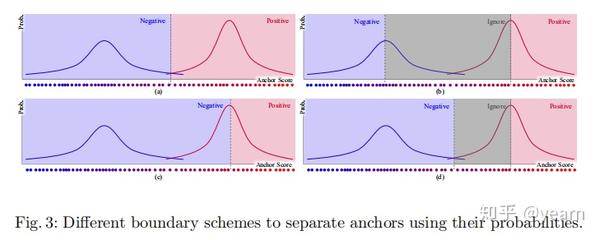

当EM确定了GMM的参数的时候,就可以用上图中的四种方法确定每个anchor是正还是负了,算法整体如下,总结为
- 对每一个GT,先选一组anchor
- 对每个选择的anchor,使用确定好的GMM计算属于正负样本的概率
- 基于概率值将样本对分为正,负,忽略三个部分。


3.2 IoU Prediction as Localization Quality
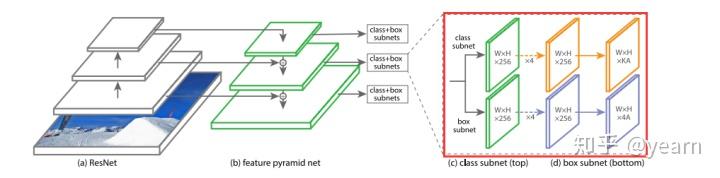
这一段比较有启发性,但是很简单,就是在RPN网络加上一个头部,也就是红框所示的部分加上一个iou预测分支,注意这里每个pixel只使用一个anchor。

if self.use_iou_pred:
self.iou_pred = nn.Conv2d(
in_channels, num_anchors * 1, kernel_size=3, stride=1,
padding=1
)
all_modules.append(self.iou_pred)
有一个比较有趣的地方(我这种菜鸡经常理解错的地方),无论是one/two stage,凡是用到anchor的,先将feature map输入,获得上图中的对每个pixel的类别和bbx偏移量的预测,然后再生成anchor(anchor并没有作为输入去预测pred_box和类别)。虽然没有用到anchor作为输入,但是上图的 W*H*4A 是和每个anchor一一对应的,anchor起到的作用只是之后来预测标签进行监督学习而已。
- 在此之后,one-stage将anchor和GT进行匹配,即根据IOU信息给他分配标签和回归目标,然后计算分类和回归损失即可,训练即可。
- two-stage的算法生成anchor之后,根据IOU信息分配前景/背景标签和回归目标,然后RPN网络就可以计算LOSS了。Then,对anchor利用pred_box做回归;提取positive score最大的N个anchor;剔除异常anchor;对剩余anchor进行NMS,最后留下的anchor生成proposal,这里就是one/two-stage最大差别(是否生产proposal),proposal再进入后续网络对类别进行预测,并再次regression。


3.3 Score Voting
这里引入了一个稍作改进的后处理的方法(压根没做改进,本来是这篇two-stage文章在NMS过程中的改进),当然对于one-stage算法,train阶段是不需要后处理的,这里只是测试阶段可以使用。所谓的得分投票,就是根据bbx自身和她的邻居给bbx重新计算出一个新的x,y,w,h,作者也验证了这样做确实有好处( s_i 是上面公式计算出的bbx的得分)。
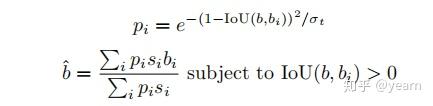

4 Experiments
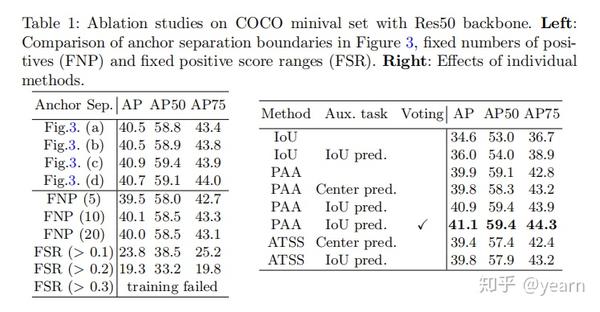
消融实验:可以看到,三种对混合高斯分布进行分割的方法其实差别不大。而PAA相对于IOU确实有提升(为啥不和novel的GIOU/CIOU比),IOU Pred也有一个点的提升

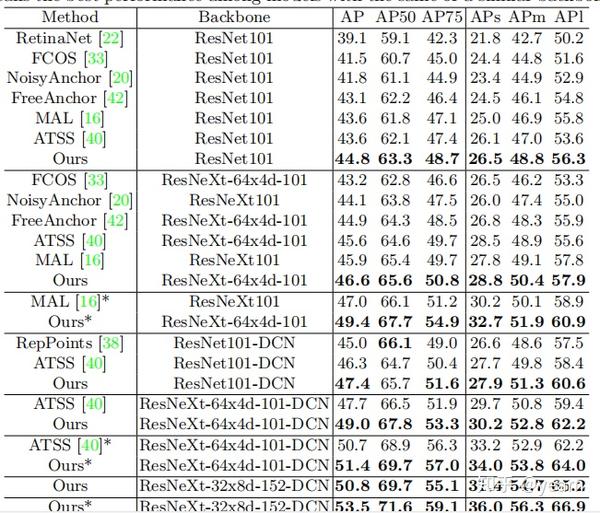
在COCO的 minival dataset 和其余三个模型的对比
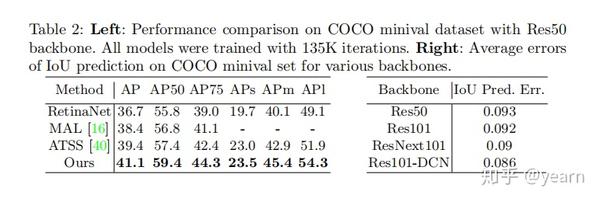

和SOTA的比较