语义分割该如何走下去?

Semantic Segmentation - 语义分割
1. 【Semantic Segmentation】Deep High-Resolution Representation Learning for Visual Recognition
【语义分割】用于视觉识别的深度高分辨率表示学习


作者:Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, Bin Xiao
链接:
https://arxiv.org/abs/1908.07919v2
代码:
https://github.com/PaddlePaddle/PaddleDetection
英文摘要:
High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection. Existing state-of-the-art frameworks first encode the input image as a low-resolution representation through a subnetwork that is formed by connecting high-to-low resolution convolutions \emph{in series} (e.g., ResNet, VGGNet), and then recover the high-resolution representation from the encoded low-resolution representation. Instead, our proposed network, named as High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams \emph{in parallel}; (ii) Repeatedly exchange the information across resolutions. The benefit is that the resulting representation is semantically richer and spatially more precise. We show the superiority of the proposed HRNet in a wide range of applications, including human pose estimation, semantic segmentation, and object detection, suggesting that the HRNet is a stronger backbone for computer vision problems.
中文摘要:
高分辨率表示对于位置敏感的视觉问题至关重要,例如人体姿态估计、语义分割和对象检测。现有的最先进的框架首先通过连接高分辨率到低分辨率卷积\emph{inseries}(例如,ResNet、VGGNet)形成的子网络将输入图像编码为低分辨率表示,并且然后从编码的低分辨率表示中恢复高分辨率表示。相反,我们提出的网络,称为高分辨率网络(HRNet),在整个过程中保持高分辨率表示。有两个关键特征:(i)连接高到低分辨率的卷积流\emph{inparallel};(ii)跨决议反复交换信息。好处是生成的表示在语义上更丰富,在空间上更精确。我们展示了所提出的HRNet在广泛的应用中的优越性,包括人体姿态估计、语义分割和对象检测,这表明HRNet是计算机视觉问题的更强大的主干。


2. 【Semantic Segmentation】ResNeSt: Split-Attention Networks
【语义分割】ResNeSt:分裂注意力网络


作者:Hang Zhang, Chongruo Wu, Zhongyue Zhang, Yi Zhu, Haibin Lin, Zhi Zhang, Yue Sun, Tong He, Jonas Mueller, R. Manmatha, Mu Li, Alexander Smola
链接:
https://arxiv.org/abs/2004.08955v2
代码:
https://github.com/open-mmlab/mmdetection
英文摘要:
It is well known that featuremap attention and multi-path representation are important for visual recognition. In this paper, we present a modularized architecture, which applies the channel-wise attention on different network branches to leverage their success in capturing cross-feature interactions and learning diverse representations. Our design results in a simple and unified computation block, which can be parameterized using only a few variables. Our model, named ResNeSt, outperforms EfficientNet in accuracy and latency trade-off on image classification. In addition, ResNeSt has achieved superior transfer learning results on several public benchmarks serving as the backbone, and has been adopted by the winning entries of COCO-LVIS challenge. The source code for complete system and pretrained models are publicly available.
中文摘要:
众所周知,特征图注意力和多路径表示对于视觉识别很重要。在本文中,我们提出了一种模块化架构,该架构将通道注意应用于不同的网络分支,以利用它们在捕获跨特征交互和学习不同表示方面的成功。我们的设计产生了一个简单而统一的计算块,可以仅使用几个变量对其进行参数化。我们的模型名为ResNeSt,在图像分类的准确性和延迟权衡方面优于EfficientNet。此外,ResNeSt在多个作为主干的公共基准上取得了优异的迁移学习结果,并已被COCO-LVIS挑战赛的获奖作品采用。完整系统和预训练模型的源代码是公开的。


3. 【Semantic Segmentation】Microsoft COCO: Common Objects in Context
【语义分割】Microsoft COCO:上下文中的公共对象


作者:Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollár
链接:
https://arxiv.org/abs/1405.0312v3
代码:
https://github.com/minimaxir/person-blocker
英文摘要:
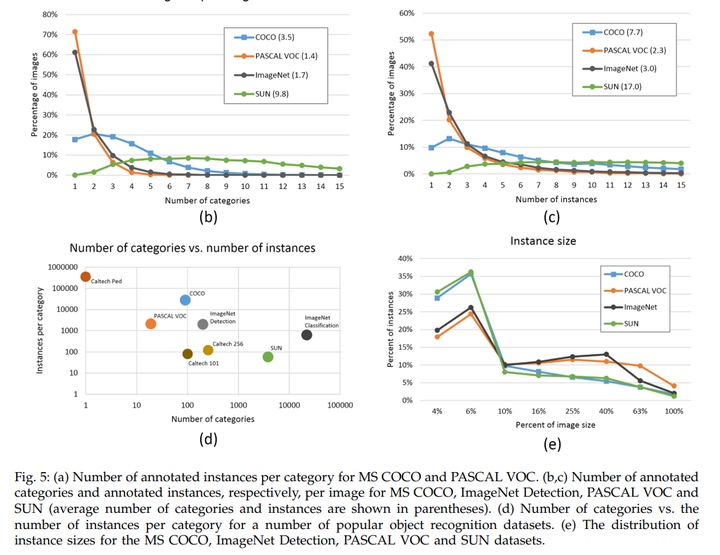
We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding. This is achieved by gathering images of complex everyday scenes containing common objects in their natural context. Objects are labeled using per-instance segmentations to aid in precise object localization. Our dataset contains photos of 91 objects types that would be easily recognizable by a 4 year old. With a total of 2.5 million labeled instances in 328k images, the creation of our dataset drew upon extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation. We present a detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet, and SUN. Finally, we provide baseline performance analysis for bounding box and segmentation detection results using a Deformable Parts Model.
中文摘要:
我们提出了一个新的数据集,旨在通过将对象识别问题置于更广泛的场景理解问题的背景下来推进对象识别的最新技术。这是通过收集包含自然背景中常见对象的复杂日常场景的图像来实现的。使用按实例分割标记对象,以帮助进行精确的对象定位。我们的数据集包含91种物体类型的照片,4岁的孩子很容易识别这些照片。在328k图像中总共有250万个标记实例,我们的数据集的创建利用了广泛的群众工作者的参与,通过新颖的用户界面进行类别检测、实例发现和实例分割。与PASCAL、ImageNet和SUN相比,我们对数据集进行了详细的统计分析。最后,我们使用可变形零件模型为边界框和分割检测结果提供基线性能分析。

4. 【Semantic Segmentation】Attention U-Net: Learning Where to Look for the Pancreas
【语义分割】注意 U-Net:学习在哪里寻找胰腺

作者:Ozan Oktay, Jo Schlemper, Loic Le Folgoc, Matthew Lee, Mattias Heinrich, Kazunari Misawa, Kensaku Mori, Steven McDonagh, Nils Y Hammerla, Bernhard Kainz, Ben Glocker, Daniel Rueckert
链接:
https://arxiv.org/abs/1804.03999v3
代码:
https://github.com/PaddlePaddle/PaddleSeg
英文摘要:
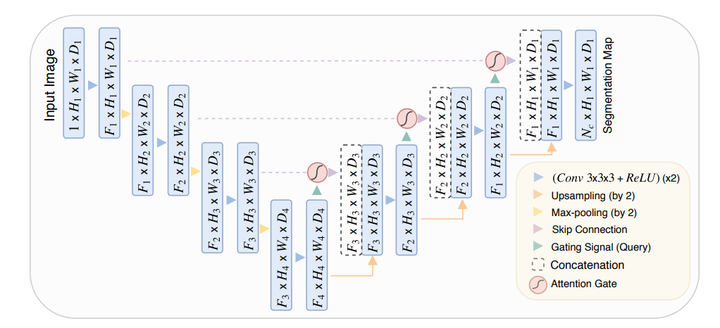
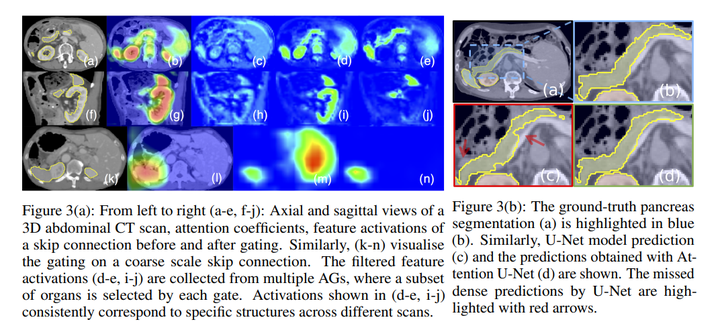
We propose a novel attention gate (AG) model for medical imaging that automatically learns to focus on target structures of varying shapes and sizes. Models trained with AGs implicitly learn to suppress irrelevant regions in an input image while highlighting salient features useful for a specific task. This enables us to eliminate the necessity of using explicit external tissue/organ localisation modules of cascaded convolutional neural networks (CNNs). AGs can be easily integrated into standard CNN architectures such as the U-Net model with minimal computational overhead while increasing the model sensitivity and prediction accuracy. The proposed Attention U-Net architecture is evaluated on two large CT abdominal datasets for multi-class image segmentation. Experimental results show that AGs consistently improve the prediction performance of U-Net across different datasets and training sizes while preserving computational efficiency. The code for the proposed architecture is publicly available.
中文摘要:
我们提出了一种用于医学成像的新型注意力门(AG)模型,该模型自动学习关注不同形状和大小的目标结构。使用AG训练的模型会隐式学习抑制输入图像中的不相关区域,同时突出对特定任务有用的显着特征。这使我们能够消除使用级联卷积神经网络(CNN)的显式外部组织/器官定位模块的必要性。AG可以很容易地集成到标准的CNN架构中,例如U-Net模型,计算开销最小,同时提高了模型的灵敏度和预测精度。所提出的Attention U-Net架构在两个大型CT腹部数据集上进行了评估,用于多类图像分割。实验结果表明,AGs在保持计算效率的同时,不断提高U-Net在不同数据集和训练规模上的预测性能。所提议架构的代码是公开的。

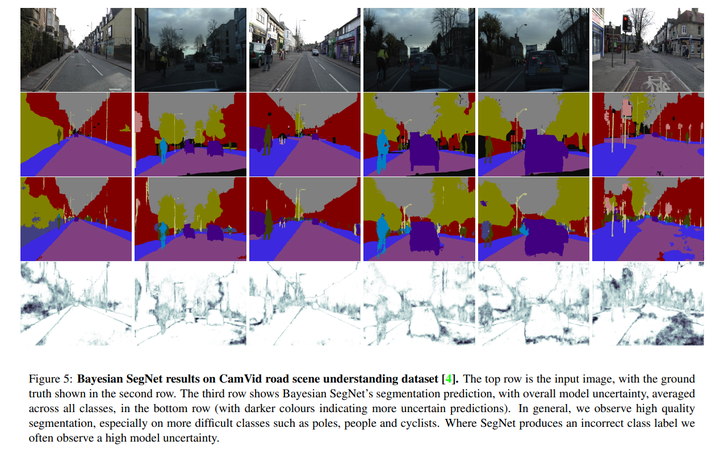
5. 【Semantic Segmentation】Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding
【语义分割】贝叶斯 SegNet:用于场景理解的深度卷积编码器-解码器架构中的模型不确定性

作者:Alex Kendall, Vijay Badrinarayanan, Roberto Cipolla
链接:
https://arxiv.org/abs/1511.02680v2
代码:
https://github.com/alexgkendall/caffe-segnet
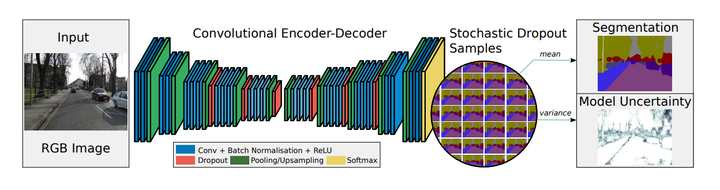
英文摘要:
We present a deep learning framework for probabilistic pixel-wise semantic segmentation, which we term Bayesian SegNet. Semantic segmentation is an important tool for visual scene understanding and a meaningful measure of uncertainty is essential for decision making. Our contribution is a practical system which is able to predict pixel-wise class labels with a measure of model uncertainty. We achieve this by Monte Carlo sampling with dropout at test time to generate a posterior distribution of pixel class labels. In addition, we show that modelling uncertainty improves segmentation performance by 2-3% across a number of state of the art architectures such as SegNet, FCN and Dilation Network, with no additional parametrisation. We also observe a significant improvement in performance for smaller datasets where modelling uncertainty is more effective. We benchmark Bayesian SegNet on the indoor SUN Scene Understanding and outdoor CamVid driving scenes datasets.
中文摘要:
我们提出了一个用于概率像素语义分割的深度学习框架,我们称之为贝叶斯SegNet。语义分割是视觉场景理解的重要工具,有意义的不确定性度量对于决策至关重要。我们的贡献是一个实用的系统,它能够通过模型不确定性的度量来预测像素级的类标签。我们通过在测试时使用带有dropout的蒙特卡罗采样来生成像素类标签的后验分布来实现这一点。此外,我们还表明,建模不确定性可以在许多最先进的架构(如SegNet、FCN和Dilation Network)中提高2-3%的分割性能,而无需额外的参数化。我们还观察到对不确定性建模更有效的较小数据集的性能显着提高。我们在室内SUN场景理解和室外CamVid驾驶场景数据集上对贝叶斯SegNet进行了基准测试。

AI&R是人工智能与机器人垂直领域的综合信息平台。我们的愿景是成为通往AGI(通用人工智能)的高速公路,连接人与人、人与信息,信息与信息,让人工智能与机器人没有门槛。
欢迎各位AI与机器人爱好者关注我们,每天给你有深度的内容。
微信搜索公众号【AIandR艾尔】关注我们,获取更多资源❤biubiubiu~