张量分解(三):模型压缩

目前已经全面转向自然语言处理了,但是大实验室还是做张量的,之前还关注一部分张量模型压缩的文章和实验,奈何我对张量理论了解的不深刻,所以这里只是一个综述和个人见解。
2020.2.24 我回来更新啦。
开始我们的正题。随着深度学习模型的日渐增大,对部署的压力也越来越大,模型压缩就是很好的解决方案。常见的模型压缩方法有蒸馏,TS,量化,剪枝,低秩分解等等。这里的张量压缩方法就是低秩分解的一种。
本文使用TT分解来对矩阵进行分解,参考的paper是《Tensorizing Neural Network》,至于张量分解以及TT分解的内容参考这篇博文
这里简单给出TT分解的压缩效果,如下图所示。可以看出参数量大大压缩了。


为了实际演示模型压缩效果,我们这里采用t3f这个库来进行实验。官方的demo文档
为了更好的记录实验结果,我们采用了wandb来记录实验数据。
import t3f
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout, Flatten
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import optimizers
import tensorflow.compat.v1 as tf
import wandb
from wandb.keras import WandbCallback
tf.disable_v2_behavior()
tf.enable_resource_variables()
import tensorflow.keras.backend as K
tf.set_random_seed(0)
np.random.seed(0)
sess = tf.InteractiveSession()
K.set_session(sess)
wandb.init(magic=True, project="tensor_train")
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 127.5 - 1.0
x_test = x_test / 127.5 - 1.0
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
model = Sequential()
model.add(Flatten(input_shape=(28, 28)))
# model.add(Dense(625, activation='relu'))
tt_layer = t3f.nn.KerasDense(input_dims=[7, 4, 7, 4], output_dims=[5, 5, 5, 5],
tt_rank=4, activation='relu',
bias_initializer=1e-3)
model.add(tt_layer)
model.add(Dense(10))
model.add(Activation('softmax'))
optimizer = optimizers.Adam(lr=1e-2)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=20, batch_size=64, validation_data=(x_test, y_test),callbacks=[WandbCallback()])
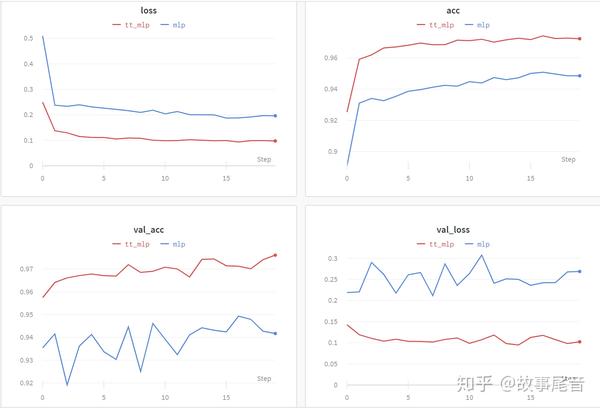

训练的结果如上图所示,可以看出,TT的压缩后的模型效果更好,主要表现在不容易过拟合。这跟参数量大大减少有直接的关系。
接下来我们分析压缩模型的性能。直观上我们知道TT压缩的参数量更少,那么是否意味着性能也更好呢?这里的性能包括显存占用,训练时间最终模型的大小等等。这里为了更方便的比较。我对上面的MLP层进行了复制,来使得数据更好的比较:
# model.add(Dense(625, activation='relu'))
# model.add(Dense(625, activation='relu'))
# model.add(Dense(625, activation='relu'))
# model.add(Dense(625, activation='relu'))
# model.add(Dense(625, activation='relu'))
tt_layer = t3f.nn.KerasDense(input_dims=[7, 4, 7, 4], output_dims=[5, 5, 5, 5],
tt_rank=4, activation='relu',
bias_initializer=1e-3)
model.add(tt_layer)
tt_layer = t3f.nn.KerasDense(input_dims=[5, 5, 5, 5], output_dims=[5, 5, 5, 5],
tt_rank=4, activation='relu',
bias_initializer=1e-3)
model.add(tt_layer)
model.add(tt_layer)
model.add(tt_layer)
model.add(tt_layer)实验结果如下图所示。可以看出tt压缩的模型训练时间更长,显存占用更多,TT压缩的模型大小为166.4kb, 没压缩的模型大小为24.8MB,这明显跟模型的参数量有关系。
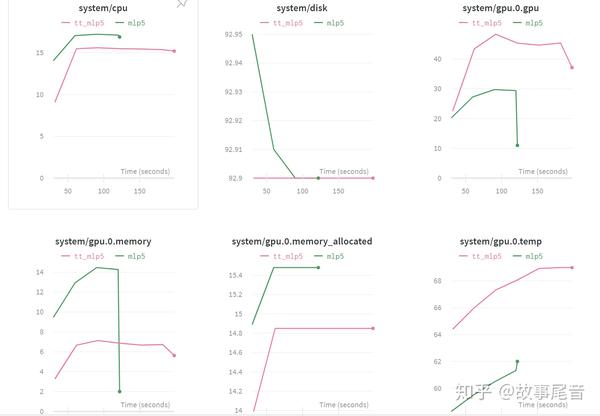
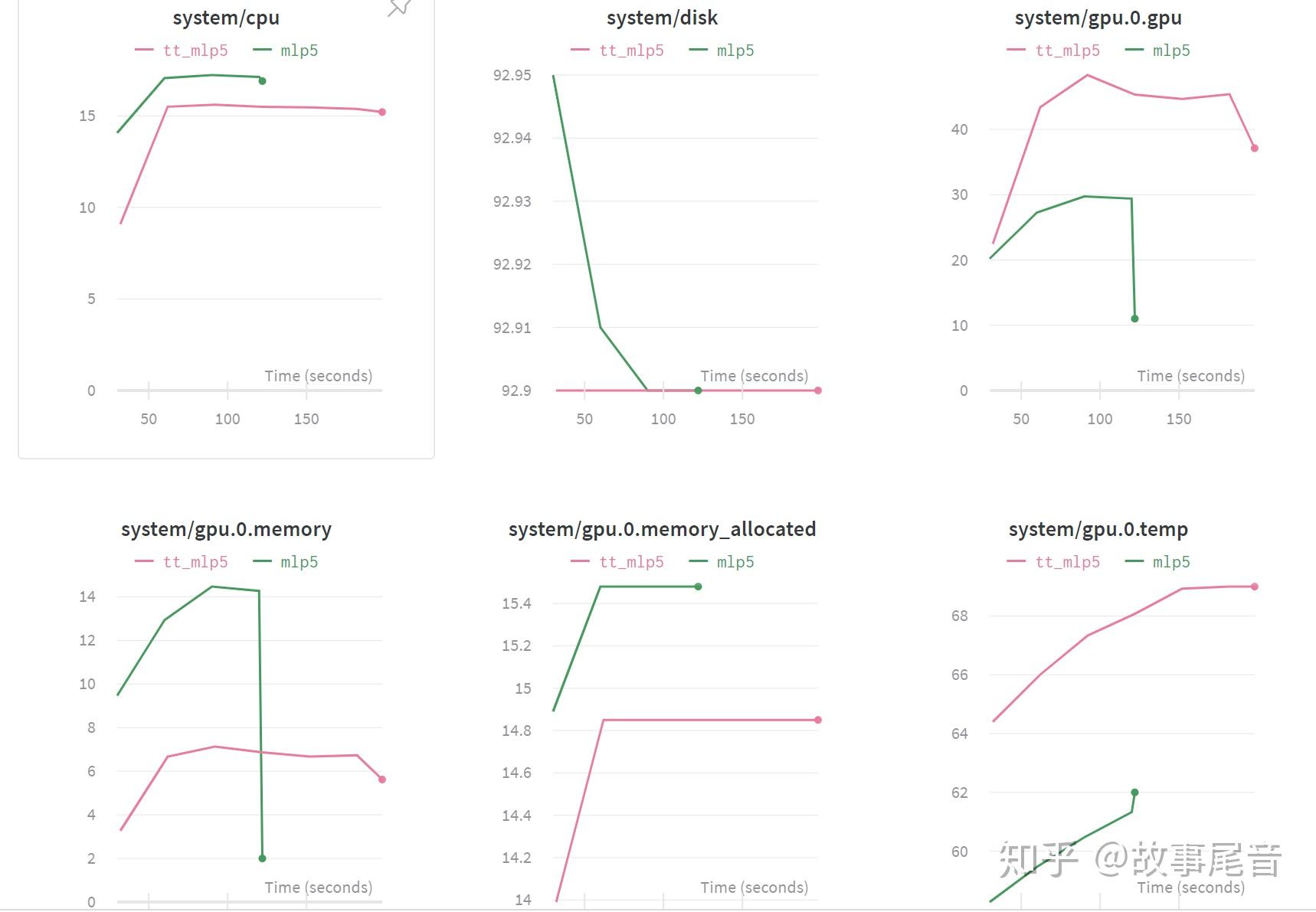
那么是否有方法可以折衷呢,方法在
也有提到,就是先正常训练,然后对模型进行分解,最后微调,具体的代码可以自己试验一下。
下一部分讲另一应用,张量补全,依旧要拖更啊~~~~~
编辑于 2020-02-24 17:39
