
R语言数据处理与分析入门 2(a brief tutorial)

在上一篇文章中,我介绍了R中简单的数据操作,以及循环、判断语句。此外还涉及到了一些简单的统计分析,这部分内容没有展开论述。
在这一篇文章中,我仍然“以任务为导向”,在完成任务的过程中讲解如何在R中进行一般线性模型的分析。
有人会问为什么为什么不从t检验和方差分析开始讲?答曰:这两者都是线性模型的特例,理解了线性模型就能理解t检验和方差分析,与其“舍本逐末”,不如“追本溯源”。
下面步入正题:
任务2-1:用Schad等人(2020)编写的函数MixedDesign() (available from OSF)来模拟2*3设计的实验的数据。实验中,在距离屏幕中央左或右一段水平距离的某处呈现刺激,要求被试按键反应并记录被试的反应时,水平距离有三个水平(1个、2个或3个单位)(假设每名被试只做一次反应,即是一个被试间设计的实验)。每个条件下有30次观测值,各条件的均值(标准差都为30)如下:
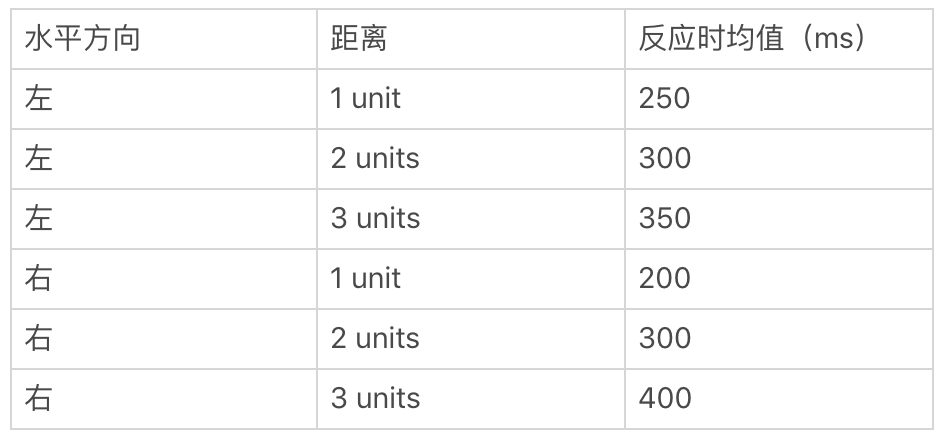

模拟数据:
df = mixedDesign(B = 6, n = 30, # B 表示 between-subject
M = matrix(c(250, 300, 350, 200, 300, 400),ncol = 1), SD = 30)注意这里各条件的均值要以矩阵的形式输入,每一行表示一个被试内的因素,每一列表示一个被试间的因素。这里数据中的两个因素都是被试间,因此先按一个因素的设计来生成,即输入一个6行1列的矩阵。
生成的数据如下,第一列为条件,第二列为编号(1-180),第三列为因变量:
> head(df)
B_A id DV
1 A1 1 241.4539
2 A1 2 276.0513
3 A1 3 205.3806
4 A1 4 224.5472
5 A1 5 329.0166
6 A1 6 233.3297下面对第一列变量进行重新编码,用两个变量(方向-direction,和 距离-distance)来表示。
这里涉及到以下几点:1.数据框内的子集选取;2.数据框中如何生成新变量;3.判断语句的迭代。对于最后一点,在excel中有常用到。
R中的子集选取运算符有三种:1. $;2. [];3.[[]]。
对于数据框,第一种运算符的功能是选取某一列,并以一维数组的形式返回:
> head(df$DV)
[1] 241.4539 276.0513 205.3806 224.5472 329.0166 233.3297
> is.vector(df$DV)
[1] TRUE第二种运算符的功能有多种,一个是选取列,并以数据框的形式返回:
> head(df[1:2])
B_A id
1 A1 1
2 A1 2
3 A1 3
4 A1 4
5 A1 5
6 A1 6
> is.data.frame(df[1:2])
[1] TRUE也可以根据列名返回 (返回结果仍为数据框):
> head(df[c('DV','id')])
DV id
1 241.4539 1
2 276.0513 2
3 205.3806 3
4 224.5472 4
5 329.0166 5
6 233.3297 6
> is.data.frame(df[c('DV','id')])
[1] TRUE但不能返回不存在的列:
> head(df[c('XX')])
Error in `[.data.frame`(df, c("XX")) : undefined columns selected二是可以输入坐标(格式为[行坐标,列坐标])返回,返回结果仍为数据框,比如返回第2到第10行:
> df[1:10, ]
B_A id DV
1 A1 1 241.4539
2 A1 2 276.0513
3 A1 3 205.3806
4 A1 4 224.5472
5 A1 5 329.0166
6 A1 6 233.3297
7 A1 7 298.4980
8 A1 8 264.9493
9 A1 9 263.0668
10 A1 10 244.2183返回第1列和第3列的第1、3、5、7、9行:
> df[c(1,3,5,7,9), c(1,3)]
B_A DV
1 A1 241.4539
3 A1 205.3806
5 A1 329.0166
7 A1 298.4980
9 A1 263.0668第三种运算符只能选取某一列,返回结果为一维数组:
> df[[1]] # 返回第一列
[1] A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1 A1
[26] A1 A1 A1 A1 A1 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A2
[51] A2 A2 A2 A2 A2 A2 A2 A2 A2 A2 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3
[76] A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A3 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4
[101] A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A4 A5 A5 A5 A5 A5
[126] A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5 A5
[151] A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6 A6
[176] A6 A6 A6 A6 A6
Levels: A1 A2 A3 A4 A5 A6
> is.data.frame(df[[1]])
[1] FALSE也可以按列名返回:
> head(df[['DV']])
[1] 241.4539 276.0513 205.3806 224.5472 329.0166 233.3297对于[]和[[]]的区别,一个形象的比方是:假设数据框是一列火车,前者表示把某一节车厢取下来,后者表示把某一节车厢的货物取下来。
不过这两者都可以用来生成新变量:
df['direction'] = ifelse(df$B_A %in% c('A1','A2','A3'),'left','right')
df['distance'] = ifelse(df$B_A %in% c('A1','A4'),'unit1',
ifelse(df$B_A %in% c('A2','A5'),'unit2','unit3'))这里,对于direction,当条件为A1, A2, A3时,为左边(left),否侧为右边(right);对于distance,当条件为A1, A4 时,为一个距离单位(unit1),条件为A2, A5 时,为两个距离单位(unit2),否则为三个距离单位(unit3)。
将两个新的变量设置为因子变量:
> df$direction = factor(df$direction, levels = c('left','right'))
> df$distance = factor(df$distance, levels = c('unit1','unit2','unit3'))查看修改后的数据:
> head(df)
B_A id DV direction distance
1 A1 1 241.4539 left unit1
2 A1 2 276.0513 left unit1
3 A1 3 205.3806 left unit1
4 A1 4 224.5472 left unit1
5 A1 5 329.0166 left unit1
6 A1 6 233.3297 left unit1任务2-2:请在一个模型中考察以下问题:
- 水平方向对反应时是否有显著影响?
- 水平距离对反应时是否有显著影响?
- 方向和距离是否有交互作用?
这里涉及到R中建立线性模型的知识。本任务同时考察两个主效应和交互作用,固然可以用上一篇文章中的aov()函数建立:
> Model2.2.1 = aov(data = df, DV~direction*distance)
> summary(Model2.2.1)
Df Sum Sq Mean Sq F value Pr(>F)
direction 1 0 0 0.00 1
distance 2 675000 337500 375.00 < 2e-16 ***
direction:distance 2 75000 37500 41.67 1.64e-15 ***
Residuals 174 156600 900
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1可以看到direction的主效应不显著,distance的主效应显著,两者的交互作用也显著。
不过这里介绍用lm()函数完成:
> Model2.2.2 = lm(data = df,
+ DV ~ direction * distance)想获取主效应和交互作用,需要用anova()函数获取
> anova(Model2.2.2)
Analysis of Variance Table
Response: DV
Df Sum Sq Mean Sq F value Pr(>F)
direction 1 0 0 0.000 1
distance 2 675000 337500 375.000 < 2.2e-16 ***
direction:distance 2 75000 37500 41.667 1.639e-15 ***
Residuals 174 156600 900
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1两种建模方式的结果是一致的。
任务2-3:请考察不同距离上,方向对反应时的影响。
如果有一定数理统计基础,对这个任务直觉上的理解是考察简单效应,因为上一个任务中发现两个因素有显著的交互作用,这样理解未尝不可,我们这里先介绍如何进行简单效应分析,R中可以利用emmeans 包中join_test() 和 emmeans() 函数获取简单主效应和之后比较的结果:
distance的不同水平上的direction的简单主效应:
> emmeans::joint_tests(Model2.2.2, by = 'distance')
distance = unit1:
model term df1 df2 F.ratio p.value
direction 1 174 41.667 <.0001
distance = unit2:
model term df1 df2 F.ratio p.value
direction 1 174 0.000 1.0000
distance = unit3:
model term df1 df2 F.ratio p.value
direction 1 174 41.667 <.0001 distance的不同水平上的direction不同水平间的事后检验:
> emmeans::emmeans(Model2.2.2, pairwise~direction|distance)
$emmeans
distance = unit1:
direction emmean SE df lower.CL Welcome
left 250 5.48 174 239 261
right 200 5.48 174 189 211
distance = unit2:
direction emmean SE df lower.CL Welcome
left 300 5.48 174 289 311
right 300 5.48 174 289 311
distance = unit3:
direction emmean SE df lower.CL upper.CL
left 350 5.48 174 339 361
right 400 5.48 174 389 411
Confidence level used: 0.95
$contrasts
distance = unit1:
contrast estimate SE df t.ratio p.value
left - right 50 7.75 174 6.455 <.0001
distance = unit2:
contrast estimate SE df t.ratio p.value
left - right 0 7.75 174 0.000 1.0000
distance = unit3:
contrast estimate SE df t.ratio p.value
left - right -50 7.75 174 -6.455 <.0001 其中$contrasts的部分即为事后检验,$emmeans部分为描述统计信息。
当然也可以反过来比较,用以下的命令:
> emmeans::joint_tests(Model2.2.2, by = 'direction')
direction = left:
model term df1 df2 F.ratio p.value
distance 2 174 83.333 <.0001
direction = right:
model term df1 df2 F.ratio p.value
distance 2 174 333.333 <.0001
> emmeans::emmeans(Model2.2.2, pairwise~distance|direction, adjust = 'bonferroni')
$emmeans
direction = left:
distance emmean SE df lower.CL Welcome
unit1 250 5.48 174 239 261
unit2 300 5.48 174 289 311
unit3 350 5.48 174 339 361
direction = right:
distance emmean SE df lower.CL Welcome
unit1 200 5.48 174 189 211
unit2 300 5.48 174 289 311
unit3 400 5.48 174 389 411
Confidence level used: 0.95
$contrasts
direction = left:
contrast estimate SE df t.ratio p.value
unit1 - unit2 -50 7.75 174 -6.455 <.0001
unit1 - unit3 -100 7.75 174 -12.910 <.0001
unit2 - unit3 -50 7.75 174 -6.455 <.0001
direction = right:
contrast estimate SE df t.ratio p.value
unit1 - unit2 -100 7.75 174 -12.910 <.0001
unit1 - unit3 -200 7.75 174 -25.820 <.0001
unit2 - unit3 -100 7.75 174 -12.910 <.0001
P value adjustment: bonferroni method for 3 tests 注意:这里是按照先考察主效应及交互作用,再考察简单效应的步骤。但是如果我们在建模时的目的就是考察不同距离上,方向对反应时的影响,换句话说,不关心交互作用是否显著,只关心三个比较是否显著。此时,先前两个自变量的编码已经不适用了,我们需要定义因子变量的虚拟编码,这部分内容在以下的文章中已经比较详细的解释了,这里不再赘述了。
这里我们以左右一个距离单位为例,我们一共有6个条件,此时左右一个距离单位(也就是B_A变量中值为A1和A4时)需要设置为 \pm 0.5 ,其余设置为0。以此类推:
df['unit1'] = ifelse(df$direction == 'left', 0.5, -0.5) *
ifelse(df$distance == 'unit1',1,0)
df['unit2'] = ifelse(df$direction == 'left', 0.5, -0.5) *
ifelse(df$distance == 'unit2',1,0)
df['unit3'] = ifelse(df$direction == 'left', 0.5, -0.5) *
ifelse(df$distance == 'unit3',1,0)这里在原有的数据框中生成三个变量,可以预览一下(方向为左时为0.5,为右时为-0.5):
> library(tidyverse)
> df %>% group_by(B_A) %>% summarise(Unit1 = unique(unit1), Unit2 = unique(unit2), Unit3 = unique(unit3))
# A tibble: 6 x 4
B_A Unit1 Unit2 Unit3
<fct> <dbl> <dbl> <dbl>
1 A1 0.5 0 0
2 A2 0 0.5 0
3 A3 0 0 0.5
4 A4 -0.5 0 0
5 A5 0 -0.5 0
6 A6 0 0 -0.5此时,对这三个变量进行建模:
> Model2.3 = lm(data = df,
+ DV ~ unit1 + unit2 + unit3)
> summary(Model2.3)
Call:
lm(formula = DV ~ unit1 + unit2 + unit3, data = df)
Residuals:
Min 1Q Median 3Q Max
-138.634 -55.740 3.072 57.654 143.836
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.000e+02 5.123e+00 58.554 <2e-16 ***
unit1 5.000e+01 1.775e+01 2.817 0.0054 **
unit2 -3.669e-15 1.775e+01 0.000 1.0000
unit3 -5.000e+01 1.775e+01 -2.817 0.0054 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 68.74 on 176 degrees of freedom
Multiple R-squared: 0.08273, Adjusted R-squared: 0.06709
F-statistic: 5.291 on 3 and 176 DF, p-value: 0.001622结果显示,一个单位时,左边多50 ms,两个单位时,左右两边相等,三个单位时,右边多50 ms。这符合模拟数据中各条件的均值差异。
这里在考察一下模型的共线性问题,利用car 包中的vif()函数:
> car::vif(Model2.3)
unit1 unit2 unit3
1 1 1 没有共线性问题。
细心的人会发现,这里的p值比简单效应分析中的p值大,说明利用虚拟变量来考察类似于简单效应的效应时,效应会减弱。这个也容易理解,毕竟两种方法的前提假设是不同的,简单效应是基于交互作用显著的情况下进行的,而虚拟变量的方法是不考虑交互作用的。
任务2-4:请考察反应时随距离(不考虑方向)的一次线性变化趋势是否显著。
这里考察的是一次线性的变化,而不是某两个水平的差异,此时需要用到多项式回归,不过这里只考虑一次项的变化。
我们先考虑一个问题:体重随着身高的一次线性变化是否显著。这个比较简单,按照weight ~ height的建模公式即可,因为身高本身就是连续变量。现在自变量为因子变量,所以需要先对其进行编码,将其转为连续变量,这里说的转为连续变量和上面提到的虚拟编码其实是一回事,只是采用了不同的编码方式。R中可以用poly()函数获取因子变量不同水平对应的虚拟变量,这里水平距离一共有三个水平。
获取一次线性变化:
> poly(1:3, 1)
1
[1,] -7.071068e-01
[2,] -7.850462e-17
[3,] 7.071068e-01
attr(,"coefs")
attr(,"coefs")$alpha
[1] 2
attr(,"coefs")$norm2
[1] 1 3 2
attr(,"degree")
[1] 1
attr(,"class")
[1] "poly" "matrix"这里按从一个单位到三个单位,依次赋值:
df['distance.linear'] = ifelse(df$distance == 'unit1', poly(1:3,1)[[1]],
ifelse(df$distance == 'unit2', poly(1:3,1)[[2]],
poly(1:3,1)[[3]]))预览一下
> df %>% group_by(B_A) %>% summarise(Linear = unique(distance.linear))
# A tibble: 6 x 2
B_A Linear
<fct> <dbl>
1 A1 -7.07e- 1
2 A2 -7.85e-17
3 A3 7.07e- 1
4 A4 -7.07e- 1
5 A5 -7.85e-17
6 A6 7.07e- 1接着根据新的变量建模:
> Model2.4 = lm(data = df, DV ~ distance.linear)
> summary(Model2.4)
Call:
lm(formula = DV ~ distance.linear, data = df)
Residuals:
Min 1Q Median 3Q Max
-99.111 -23.705 0.994 21.969 104.017
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 300.000 2.689 111.58 <2e-16 ***
distance.linear 106.066 4.657 22.78 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 36.07 on 178 degrees of freedom
Multiple R-squared: 0.7445, Adjusted R-squared: 0.7431
F-statistic: 518.8 on 1 and 178 DF, p-value: < 2.2e-16可以看到一次线性的变化趋势是显著的,且是正向的变化,距离越大,反应越慢。
任务2-5:请在一个模型中同时考察当水平向左和向右时,反应时随距离的一次线性变化趋势是否显著。
和上一个任务类似,只不过需要对左右两边分别编码,同时,编码左边时,右边的三个条件需为0,反之亦然。
df['distance.linear.left'] = ifelse(df$distance == 'unit1', poly(1:3,1)[[1]],
ifelse(df$distance == 'unit2', poly(1:3,1)[[2]],
poly(1:3,1)[[3]])) *
ifelse(df$direction == 'left', 1, 0)
df['distance.linear.right'] = ifelse(df$distance == 'unit1', poly(1:3,1)[[1]],
ifelse(df$distance == 'unit2', poly(1:3,1)[[2]],
poly(1:3,1)[[3]])) *
ifelse(df$direction == 'left', 0, 1)预览一下:
> df %>% group_by(B_A) %>% summarise(Linear.left = unique(distance.linear.left), Linear.right = unique(distance.linear.right))
# A tibble: 6 x 3
B_A Linear.left Linear.right
<fct> <dbl> <dbl>
1 A1 -7.07e- 1 0.
2 A2 -7.85e-17 0.
3 A3 7.07e- 1 0.
4 A4 0. -7.07e- 1
5 A5 0. -7.85e-17
6 A6 0. 7.07e- 1根据新的变量建模:
> Model2.5 = lm(data = df,
+ DV~distance.linear.right + distance.linear.left)
> summary(Model2.5)
Call:
lm(formula = DV ~ distance.linear.right + distance.linear.left,
data = df)
Residuals:
Min 1Q Median 3Q Max
-74.111 -19.716 1.729 19.768 79.017
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 300.000 2.217 135.32 <2e-16 ***
distance.linear.right 141.421 5.431 26.04 <2e-16 ***
distance.linear.left 70.711 5.431 13.02 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 29.74 on 177 degrees of freedom
Multiple R-squared: 0.8273, Adjusted R-squared: 0.8253
F-statistic: 423.9 on 2 and 177 DF, p-value: < 2.2e-16结果显示左右两边都有线性的趋势,但是右边的趋势似乎更大一些。
任务2-6:请考察左右方向上,反应时的一次线性变化趋势是否有显著差异。
注意,这里不再是单独考察两个方向上的线性趋势了,而是考察两个线性趋势的差异。比如我们设定用左边的线性趋势去和右边的趋势比较 (左边 - 右边),那么左边仍然按照先前的方式编码,右边的编码需要变为相反数:
df['distance.linear.compare'] = ifelse(df$distance == 'unit1', poly(1:3,1)[[1]],
ifelse(df$distance == 'unit2', poly(1:3,1)[[2]],
poly(1:3,1)[[3]])) *
ifelse(df$direction == 'left', 1, -1)预览一下:
> df %>% group_by(B_A) %>% summarise(Linear.compare = unique(distance.linear.compare))
# A tibble: 6 x 2
B_A Linear.compare
<fct> <dbl>
1 A1 -7.07e- 1
2 A2 -7.85e-17
3 A3 7.07e- 1
4 A4 7.07e- 1
5 A5 7.85e-17
6 A6 -7.07e- 1建模:
> Model2.6 = lm(data = df, DV ~ distance.linear.compare)
> summary(Model2.6)
Call:
lm(formula = DV ~ distance.linear.compare, data = df)
Residuals:
Min 1Q Median 3Q Max
-138.634 -55.740 3.072 57.654 143.836
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 300.000 5.095 58.886 < 2e-16 ***
distance.linear.compare -35.355 8.824 -4.007 9.04e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 68.35 on 178 degrees of freedom
Multiple R-squared: 0.08273, Adjusted R-squared: 0.07757
F-statistic: 16.05 on 1 and 178 DF, p-value: 9.039e-05结果显示,左右的线性趋势差异显著,左边的线性趋势较弱,右边较强。
任务2-7:请考察从左边三个距离单位处,到右边三个距离单位处,反应时的二次线性变化趋势是否显著。
这里不再是一次线性变化,而是二次线性变化了,同样可以用poly()函数可以获取(注意,这里是6个条件了):
> poly(1:6,2)
1 2
[1,] -0.5976143 0.5455447
[2,] -0.3585686 -0.1091089
[3,] -0.1195229 -0.4364358
[4,] 0.1195229 -0.4364358
[5,] 0.3585686 -0.1091089
[6,] 0.5976143 0.5455447第一列为1次项,第二列为2次项。
接下来是编码,这里需要注意,因为有6个一一对应的条件,如果用ifelse()的话非常麻烦,需要迭代5次。注意到,数据是按照B_A变量顺序排列的,因此,只需要把poly编码每个数值重复30次即可:
> df['distance.linear'] = rep(poly(1:6, 2)[,1], each = 30)
> df['distance.quadratic'] = rep(poly(1:6, 2)[,2], each = 30)根据新的变量建模:
> Model2.7 = lm(data = df, DV ~ distance.linear + distance.quadratic)
> summary(Model2.7)
Call:
lm(formula = DV ~ distance.linear + distance.quadratic, data = df)
Residuals:
Min 1Q Median 3Q Max
-150.777 -44.937 0.013 47.029 136.208
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 300.00 4.62 64.937 < 2e-16 ***
distance.linear 71.71 11.32 6.337 1.88e-09 ***
distance.quadratic 49.10 11.32 4.339 2.40e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 61.98 on 177 degrees of freedom
Multiple R-squared: 0.25, Adjusted R-squared: 0.2415
F-statistic: 29.49 on 2 and 177 DF, p-value: 8.817e-12结果显示,二次线性变化趋势是显著的。
小结一下,本文主要涉及到以下知识点:
- 如何在R中利用线性模型处理因子设计的实验数据。
- 如果获取主效应和交互作用。
- 如何进行简单效应分析。
- 如何进行事先设置的对比。
- 线性模型中因子变量的虚拟编码是怎么回事(理解了这个,分析数据会更灵活)。
最后,还是强调那句话,线性回归是很多常见分析方法的“母体”,理解并熟练运用线性回归对分析数据有极大的帮助。
参考文献:
Schad, D. J., Vasishth, S., Hohenstein, S., & Kliegl, R. (2020). How to capitalize on a priori contrasts in linear (mixed) models: A tutorial.Journal of Memory and Language,110, 104038.
