如何理解‘机器学习不问因果只关问相关性,只作归纳不作演绎‘?

归纳式和直推式学习(Inductive vs. Transductive Learning)你可能在很多文章中遇到过这两个让人困惑的概念,这篇文章会让你理解这两种学习方式的区别,以及他们如何应用在我们实际场景中。
理解定义
根据维基百科:Transduction is reasoning from observed, specific (training) cases to specific (test) cases. In contrast, induction is reasoning from observed training cases to general rules, which are then applied to the test cases.
我们来拆解理解一下。
归纳式(Inductive)
归纳式学习是我们传统理解的监督学习(supervised learning),我们基于已经打标的训练数据,训练一个机器学习模型。然后我们用这个模型去预测我们没有从未见过的测试数据集上的标签。
直推式(Transduction)
和归纳式不同,直推式学习首先观察全部数据,包括了训练和测试数据,我们从观测到的训练数据集上进行学习,然后在测试集上做预测。即便如此,我们不知道测试数据集上的标签,我们可以在训练时利用数据集上的模式和额外信息。
典型的直推式学习方法有TSVM(transductive SVM)和LPA(graph-based label propagation algorithms)。
这两者的区别是什么?
主要区别是直推式学习时,在训练模型时已经同学用到了训练和测试数据,而归纳式学习训练时只使用了训练数据,在测试时从未见过测试数据。
直推式学习不会建立一个预测模型,如果一个新数据节点加入测试数据集,那么我们需要重新训练模型,然后再预测标签。然而,归纳式学习会建立一个预测模型,遇到新数据节点不需要重新运行算法训练。
简而言之,归纳式学习企图基于已观测训练数据,建立一个通用模型,用来预测任何新数据节点。你可以预测任何数据节点,不局限在无标记数据上。相比之下,直推式学习是基于所有已经观测到的训练和测试数据来建立模型的,这种方法是通过已经有标记的节点信息来预测无标记数据节点。
直推式学习在遇到新的输入数据时会变得比较费事,每当新数据来了,你需要重新运行。然而,归纳式学习一开始就建立了预测模型,因而在新数据来的时候可以用非常少的代价就打上标记。
一个实例
首先我们有个如图中的示例,考虑你有图1中的这些数据点。有四个点(A、B、C、D)已经有标签,我们的目标是给其余1-14号节点染色打上标签。如果我们使用归纳式学习,我们可以用这4个已经打标的节点训练一个监督学习模型。
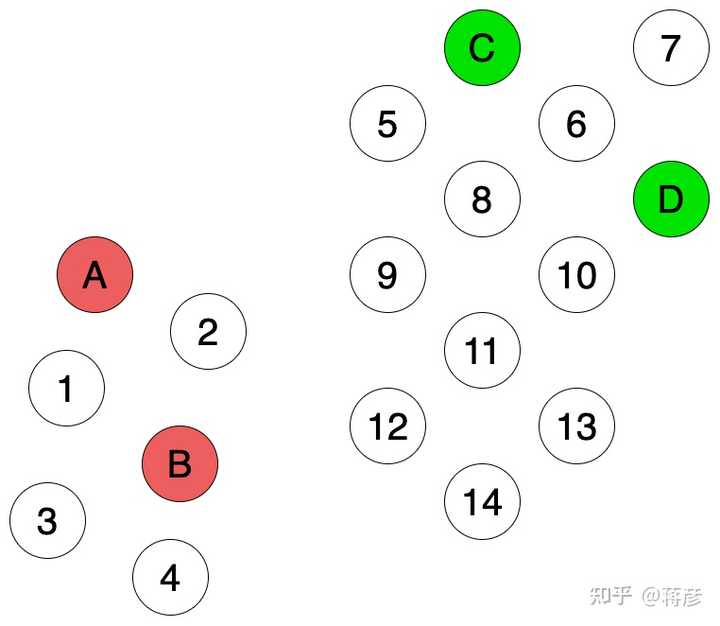

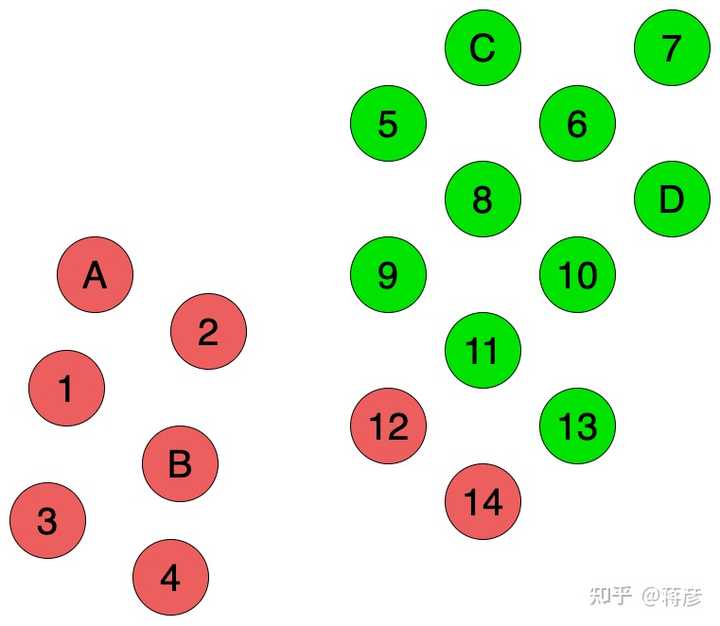
粗看一眼,我们有两个独立聚簇,然而在归纳式学习时,我们因为训练数据较少,我们很难建立一个能把握整体数据结构的预测模型。例如,如果我们使用最近邻方法,那么12、14号会被打上红色标签,因为相较于C、D,他们距离A、B更近,见图2.

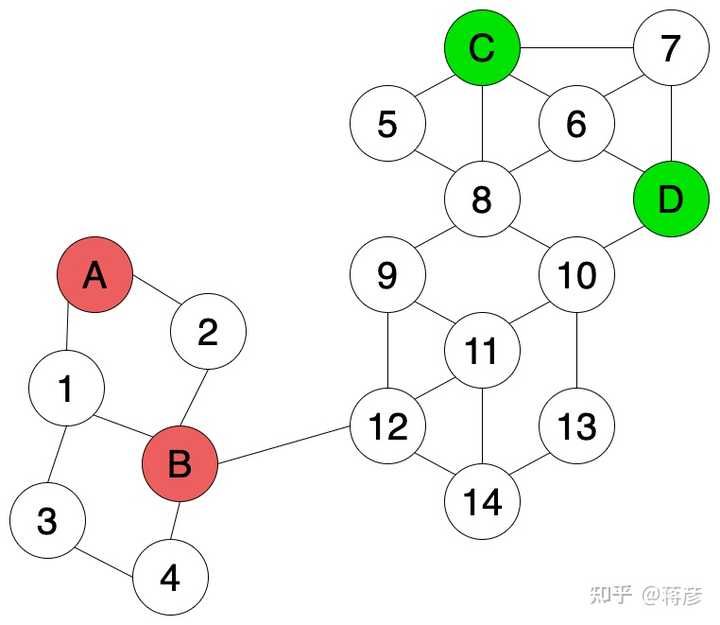
如果我们有一些额外信息例如基于一些距离之类的特征建立的连接关系,如图3,我们可以利用这些额外信息来训练模型和给数据打标。

例如,我们可以用直推式学习,例如基于半监督图网络的LPA算法,来像图4那样给数据打标。像12、14这样的边界节点,因为与更多的绿色节点产生连接,因此也被打上绿色标签,而非红色标签。
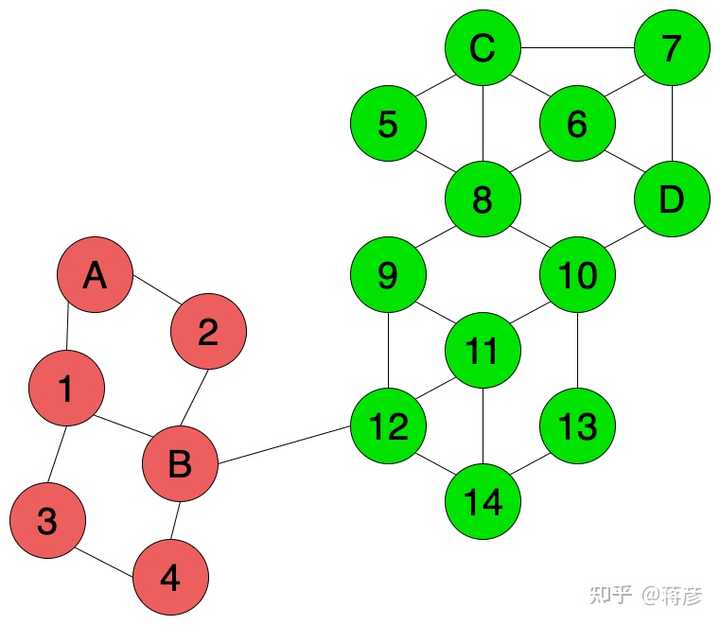

注意我们可以使用直推式学习是因为我们最开始就使用了全部的训练和预测数据,并且测试数据有一些额外有用的信息。如果一开始我们没有测试数据,我们就不得不使用归纳式学习方法了。
最后思考
我们讨论了归纳式和直推式学习方法并且讲了一个具体案例,现在你应该对他们的区别有了一些概念,之后你可以利用这些知识去建立你下一个机器学习模型了。
译自:https://towardsdatascience.com/inductive-vs-transductive-learning-e608e786f7d