目标检测中图像增强,mixup 如何操作?


随机混合图像,效果是不是会更好?
一直以来,在深度学习领域,图像分类是呈指数级增长的课题之一。传统的图像识别任务很大程度上依赖于一些专有的处理技术,如膨胀/消蚀、内核和频域转换等处理方法,然而特征提取的困难最终限制了这些方法所取得的进展。另一方面,神经网络关注的是寻找输入图像和输出标签之间的关系,为了实现此目的,需要对架构进行“调优”。虽然准确性提高得很显著,但网络通常需要大量的数据来进行训练,因此,现在有许多研究都关注数据增强——在现有数据集基础上增加数据量的过程。
本文介绍了一种既简单又有效的增强策略——Mixup,利用 PyTorch框架实现Mixup并对结果进行比较。
为什么在使用Mixup之前要增强数据?
根据给定的训练数据集来训练和更新神经网络体系结构中的参数。然而,由于培训数据只涵盖了整个可能数据分布的某一部分,因此网络可能过于适合分布的“可见”部分。因此,我们拥有进行训练的数据越多,理论上就能更好地描述整个分布。
虽然我们拥有的数据数量有限,但我们总是可以尝试稍微改变图像,并将它们作为“新”样本输入网络进行培训。这个过程被称为数据增强。
Mixup为何物?
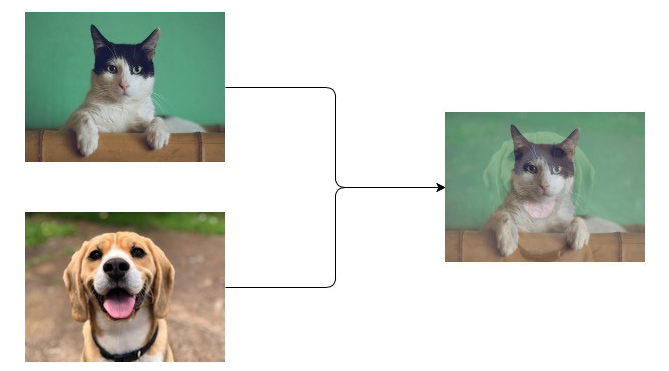

图1 图像Mixup的简单可视化图
假设需要对狗和猫的图像进行分类,给出一组带有标签的图像集合(即[1,0]代表狗;[0, 1] 代表猫),Mixup的过程是对两幅图像进行简单的平均,它们的标签对应一个新数据。
具体地说,Mixup可以用以下数学概念来描述:
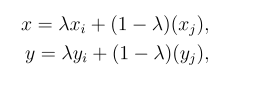
其中x,y是混合后的图像及其标签,其中,图像xᵢ(标签为yᵢ)和图像xⱼ(标签为yⱼ),λ为给定beta分布的随机数。
这为不同的类提供了连续的数据样本,直观地扩展了给定训练集的分布,从而使网络在测试阶段更加稳健。
在所有网络上使用Mixup
由于Mixup仅仅是一种数据增强方法,它与所有分类网络架构正交,这意味着可以在所有分类问题的神经网络中采用Mixup。
本文在 “Mixup:远不止将经验风险最小化”一文的基础上,对多个数据集和架构进行了实验,实验结果表明:Mixup的好处不是一次性的特例。
计算环境
运行库
整个项目通过PyTorch库(包括torchvision)来实现,Mixup需要从beta分布中生成样本,这可以方便地通过NumPy库实现,也可以使用随机库来Mixup随机图像。利用以下代码导入库:

数据集
作为演示,为了将Mixup的概念应用到传统的图像分类上, CIFAR-10数据集似乎是最可行的选择,CIFAR-10数据集包含10个类,多达60000幅彩色图像(每类6000个),以5:1的比例分为训练集和测试集。这些图像的分类相对简单,但比最基本的数字识别数据集MNIST要难。
有多种方法可以下载到CIFAR-10数据集,包括从多伦多大学的网站上下载或使用torchvision数据集。另一个值得一提的平台是Graviti Open Datasets 平台,该平台包含数百个数据集及其相应的作者,各个数据集对应训练任务的标签(即分类、目标检测)。也可以下载其他分类数据集,如CompCars或SVHN来测试不同场景下性能的优化。目前,该公司正在开发SDK,虽然现在加载数据会比较费时,但未来不久将可能会有所改进,因为他们正在优化快速批量下载。
硬件要求
最好在GPU上训练神经网络,因为GPU能显著提高训练速度。但是,如果手上只有CPU可用,仍然可以测试该程序。只需使用以下操作,便可以确定运行程序的硬件要求:

实施情况
网络
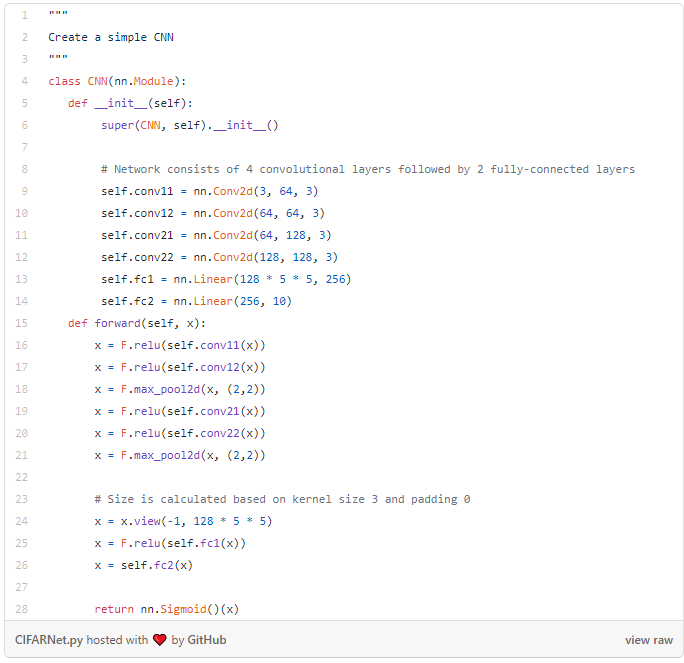
实验目的是要看到Mixup的结果,而不是神经网络本身。因此,为了达到演示的目的,实现了一个简单的4层卷积神经网络(CNN),后随 2层全连接层。注意,对于Mixup和非Mixup训练程序,均采用相同的神经网络以确保其公平性。
构建以下简单网络:

Mixup
在数据集加载过程中完成Mixup,首先必须编写自己的数据集,而不是使用torchvision.datasets提供的默认数据集。
以下是利用NumPy中包含的beta分布函数实现Mixup的代码:


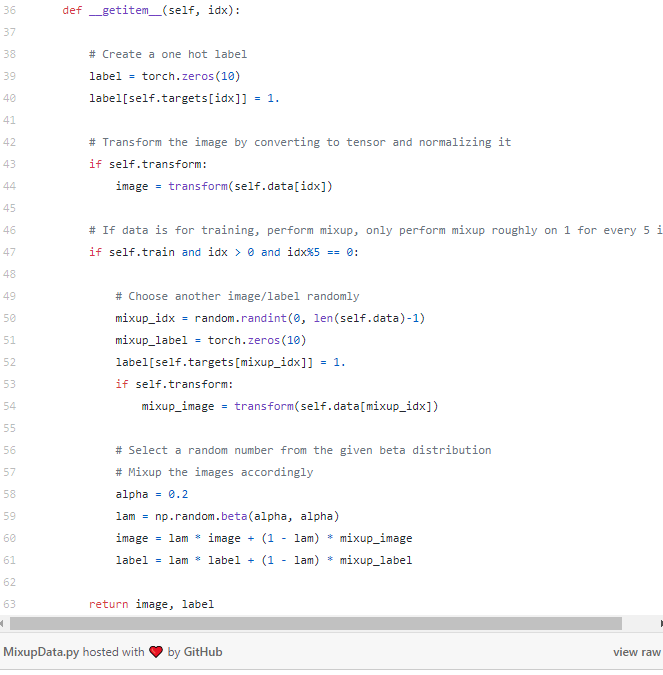

注意,上述程序并没有对所有图像应用Mixup,而是对大约五分之一的图像应用Mixup。此外,还使用了0.2的beta 分布,可以根据不同的实验来修改分布参数和图像的数量,以期取得更好的结果!
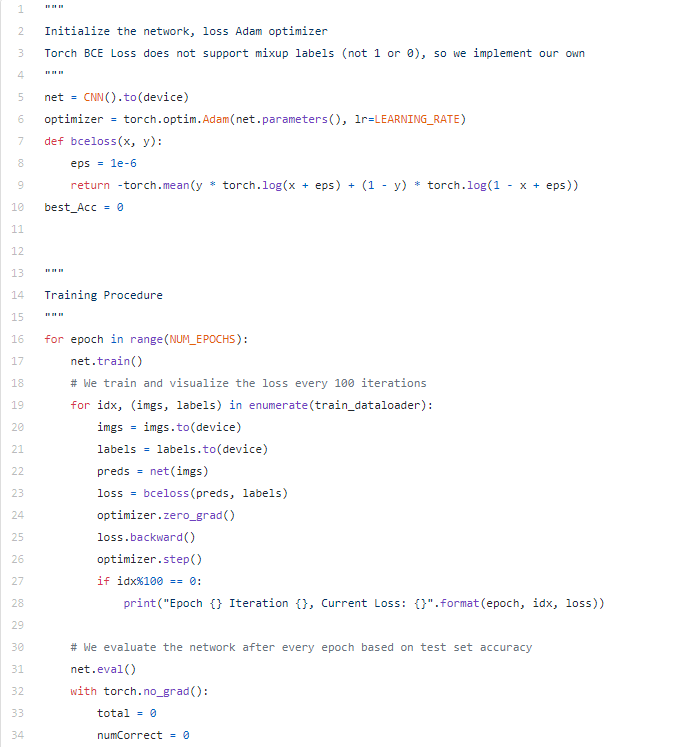
训练与评估
以下代码为训练程序,将批处理大小设置为128,学习速率设置为1e-3,epochs总数设置为30。整个训练进行了两次,一次是带Mixup的,一次是不带Mixup;损失也由自己定义,因为目前,BCE损失不允许带有小数的标签:

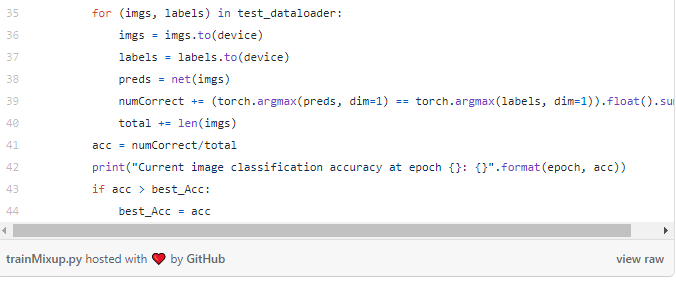

为了评估Mixup的效果,分别对带有Mixup和不带Mixup各自计算了三次准确率。在没有Mixup的情况下,网络对测试集的准确率约为74.5%,而在带有Mixup时,准确率提高到76.5%左右!
图像分类之外的拓展
Mixup不但提高了图像分类的准确性,研究表明,而且它的优势已经扩展到其他计算机视觉任务中,如能提高对抗性样本的鲁棒性。同时,研究文献也将这个概念扩展到三维表示中,已经证明非常有效(例如:PointMixup)。
结论
希望这篇文章能带给你一个关于如何在训练图像分类网络时应用Mixup的基本概述和指南。可以在以下Github仓库中找到完整的实现代码:

谢谢拨冗阅读本文!后续将发布更多关于计算机视觉/深度学习的不同领域的文章。一定要看看关于VAE的其他文章,通过一次性学习,汲取更多知识!