机器学习训练秘籍


本文内容均来自吴恩达的《机器学习训练秘籍》,算是对其的概括以及自身对该书的理解感悟
很多开发工程师会嘲笑搞算法的,你们的工作不就是调调参吗?你们用的模型都是20年前的,只不过凭借互联网时代积累的大数据加上近年计算能力的提升,现在才取得了巨大的进展。
对此,你只要置之不理即可。
言归正传。算法工程师的工作内容确实包括调参,但也不仅仅只限于此,而且这一工作内容并不好做。
当你发现loss曲线上下波动,怎么也降不下去,你是否有过抬头问苍天到底为什么的苦闷场景。作为一名合格的算法工程师,我们不能把这一切归结为玄学,从而心安理得的简单调参。接下来,就介绍机器学习领域大师吴恩达,对于训练模型的一些建议。
当我以前面试的时候,面试官经常问我的一个问题就是,如果模型效果不好,你会怎么办?
对此,有很多套路式的回答。比如:
- 收集更多数据
- 丰富收集数据。或利用裁剪、旋转(CV领域),近义词替换、语句调换(NLP领域)等方式进行数据增强。
- 增加梯度下降的迭代次数
- 提高神经网络的复杂性
- 改变神经网络的架构
如果你只是一个应届毕业生来面试,这种回答应该是可以勉强蒙混过关的。但是进入实际工作中,要求高效、可复用的、可持续的优化,就无法再像打比赛一样祈求玄学,最好还是有一套合理的调参原则。
第一点 : 走进训练集、验证集,测试集
我们首先来了解一下训练集、验证集、测试集这三个概念。
训练集用于训练你的算法模型,验证集用来调参或调整网络结构,测试集用来测试算法模型的最终泛化能力。
打个很好的比喻。训练集就好像在教室上课,验证集就好像模拟考,测试集就好像最终参加高考。
训练集是模型学习参数的直接对象,自然不能用它来测试模型的泛化能力。对于新手,也许有人迷惑为何不能用验证集来测试模型的泛化能力,这是因为,验证集是你用来调整参数和网络结构的,如果用其来衡量,其自然是最适合当前的参数和网络结构的。
所以,只有测试集,才可以用来衡量网络最终的泛化能力。也是模型上线前的最后一步。
第二点 :训练集和测试集要服从同一分布
这里的训练集包括训练集和验证集。
如果我们在做一个船舶图片分类系统。我们有1000张可见光图片,1000张红外图片,我们将可见光图片做训练集,红外图片做测试集是显然不行的。
第三点 :样本规模
当模型效果不好,扩大数据集是一种常见的做法。可数据集到底扩充到什么程度?如何分配训练集与测试集呢?
这里有一些原则。
验证集的规模要尽可能大,至少要能区分所尝试的不同算法的性能差异。比如A分类器准确率达90%,B分类器准确率达90.1%,可如果仅有100个样本,将无法检测出这0.1%的差异。
测试集的分配原则是尽可能和训练集独立同分布,从而可以高度可信全面的评估系统,又能体现很好的泛化能力。其规模最好是整个数据集的30%左右。
第四点 :偏差和方差
机器学习模型的误差主要来源于两个方面,偏差和误差。
偏差是指模型在训练集上产生的误差,方差是指模型在验证集上的表现比在训练集上差多少。
举个例子。一个舰船分类器,其训练集上的误差是15%,验证集上的错误率为16%。那么该模型的偏差为15%,方差为1%。
说的通俗一点,因为模型本身的问题,导致其分类错误率达15%。放到验证集上,因为有一个数据泛化的过程,多了1%的错误率,这个错误率就是方差。所以方差也可以理解为数据泛化过程中的误差。
深入理解方差和偏差,可以帮助我们很好得选择提高模型正确率的方法。
下面举例说明。
- 某系统偏差1%,方差10%。这种典型的低偏差,高方差,说明模型在训练集上效果很好,但是泛化能力不强。俗称过拟合。此时可以采用扩大数据规模,正则化等方式去解决。
- 某系统偏差15%,方差1%。这种典型的高偏差,低方差,说明模型本身对训练集适应性很差,放到验证集上也差不多。俗称欠拟合,即模型本身出了问题。可以采取提高模型复杂度等方式来解决。
- 某系统偏差15%,方差15%。高偏差,高方差,即模型本身不好,其放在验证集上效果更是差的多。这种就要双管齐下。从偏差、方差两个角度去解决问题。
- 某系统偏差0.5%,方差0.5%。恭喜该系统可以上线了。
对于新手来说,需要注意的是:增大数据规模往往可以降低方差,但对偏差无影响。而且很多方法,往往存在着厚此薄彼,即降低方差的同时,会提高偏差。比如减小模型规模、加入正则化、提前终止等手段会在降低偏差的同时提高方差。请谨慎使用。
总得来说,增大数据规模和提高模型复杂度是有益无害的。提高模型复杂度对提高方差的影响可以通过加入合理正则化来抵消。
第四点 :学习曲线
学习曲线可以将开发集的误差与训练集样本的数量进行关联比较。想要绘制出它,你需要设置 不同大小的训练集来运行算法。
假设有 1000 个样本,你可以选择在规模为 100、200、300 ... 1000 的样本集中分别运行算法,接着便能得到开发集误差随训练集大小变化的曲线。图1是一个例子:
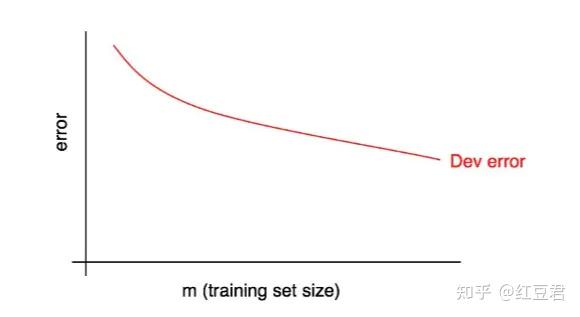

通常会如图1所示,随着训练集规模增大,验证集误差降低。
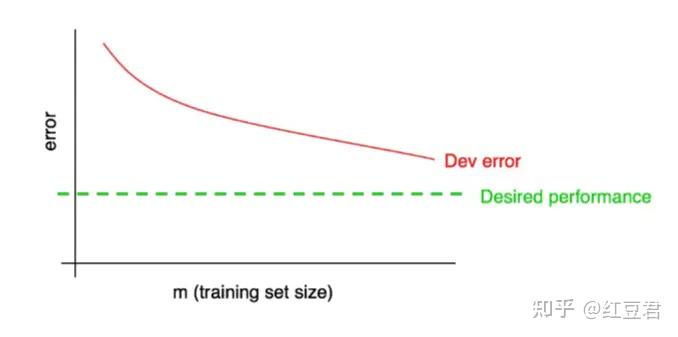

通常还会有个最优错误率的概念,如图2中的绿线。它通常源自对问题本身的先验知识。
根据该图我们可以清楚的知道,算法在何时陷入了瓶颈,在什么情况下,增大数据规模是徒劳的。
随着训练集大小的增加,开发集(和测试集)误差应该会降低,但你的训练集误差往往会随之 增加。
让我们来举例说明一下。假设你的训练集只有两个样本:一张猫图和一张非猫图。学习算法很 轻易地就可以“记住”训练集中这两个样本,并且训练集错误率为 0%. 即使有一张或两张的样本 图片被误标注了,算法也能够轻松地记住它们。
现在假设你的训练集包含 100 个样本,其中有一些样本可能被误标记,或者是模棱两可的 (图像非常模糊),所以即使是人类也无法分辨图中是否有一只猫。此时,或许学习算法仍然 可以“记住”大部分或全部的训练集,但很难获得 100% 的准确率。通过将训练集样本数量从 2 个增加到 100 个,你会发现训练集的准确率会略有下降。
下面我们将训练误差曲线添加到原有的学习曲线中:
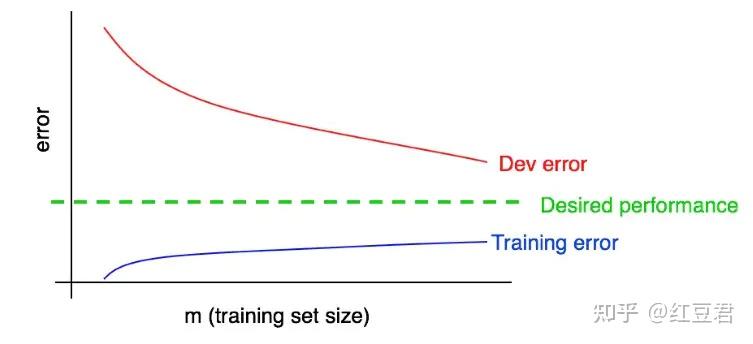

可以看到,蓝色的“训练误差”曲线随着训练集大小的增加而上升,而且算法在训练集上通常比 在开发集上表现得更好;因此,红色的开发误差曲线通常严格位于蓝色训练错误曲线之上。
接下来,我们把学习曲线和偏差、方差结合起来,加深对这三者的理解。
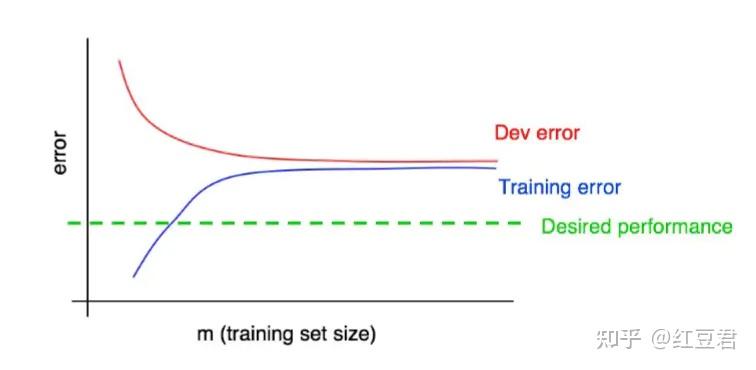

从图4可以看出,验证集上的误差随着样本增大虽然在逐渐降低,但是远高于最优错误率,而训练集误差远高于最优错误率,并逐渐接近验证集误差。
这其实不就是低方差(验证集训练集误差差不多),高偏差(训练集效果很差)!这张图也可以很好的解释,为何高偏差问题无法用增大数据规模来解决(该调整模型结构了,考虑使用更复杂的模型吧!)。
正常情况下,学习曲线图应是图3的样子,即低方差、低偏差。
同理,图5应是高方差,低偏差的例子。
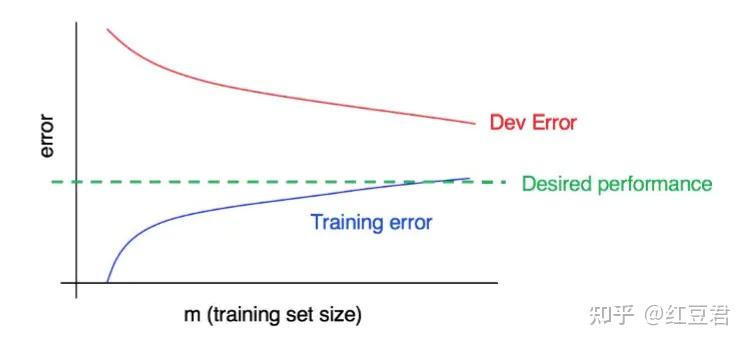

同理,图6是高偏差,高方差的例子。
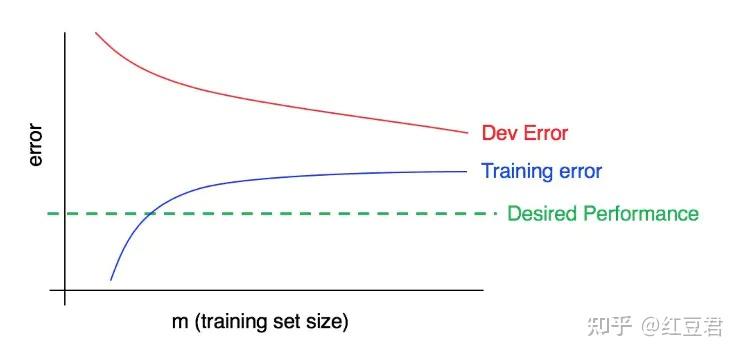

最后提一点,绘制一个学习曲线的成本可能非常高!
例如,你可能需要训练 10 个模型,其中 样本规模可以是 1000 个,然后是 2000 个,一直到 10000 个。使用小数据集训练模型比使用 大型数据集要快得多。因此,你可以用 1000、2000、4000、6000 和 10000 个样本来训练模型,而不是像上面那样将训练集的大小均匀地间隔在一个线性的范围内。
这仍然可以让你对学 习曲线的变化趋势有一个清晰的认识。当然,这种技术只有在训练所有额外模型所需的计算成本很重要时才有意义。

