![论文阅读:[CVPR 2020 oral & TPAMI] Old Photos](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
论文阅读:[CVPR 2020 oral & TPAMI] Old Photos

CVPR 2020 oral:Bringing Old Photos Back to Life
TPAMI 2020:Old Photo Restoration via Deep Latent Space Translation
论文链接:https://arxiv.org/abs/2004.09484 (CVPR oral)
https://arxiv.org/pdf/2009.07047v1.pdf (TPAMI)
开源代码:microsoft/Bringing-Old-Photos-Back-to-Life
Title
香港城市大学和微软亚研院团队的超强老照片修复框架Bring Old Photos Back to Life,中了2020 CVPR oral还中了TPAMI,方法很强大,效果十分显著,代码和预训练模型已经开源(train部分代码暂未开源)。两版文章内容基本一致,个人感觉TPAMI版本的文章稍微详细一些,但这里为了方便,选择在CVPR版的文章上做笔记。
Abstract
作者团队通过使用深度学习,对严重退化(severe degradation)的老照片进行修复和还原。与可以通过监督学习(supervised)解决的常规还原任务不同,real photos的退化很复杂,并且合成图像(synthetic images)与真实老照片之间的domain gap使得网络无法很好地泛化。因此作者团队提出了一个新的三重态域转换网络(triplet domain translation network),该网络使用真实照片和大量合成图像对进行训练。
具体来说,首先训练两个变分自动编码器(variational autoencoders, VAEs),两个VAE分别将老旧照片和干净照片映射到两个隐空间(latent space);并使用生成的成对数据学习两个隐空间之间的转换/映射。因为在紧凑的隐空间中(compact latent space),domain gap很近,所以这种转换/映射可以很好地泛化到真实图片上。
此外,为了解决一张老照片中混合的多种退化问题,作者团队设计了一个全局分支(global branch),该分支使用一个可以解决结构化缺失(structed defects,例如划痕和灰尘)的partial nonlocal block;还设计了一个局部分支(local branch),该分支用于解决非结构化缺失(unstructed defects,例如噪声和模糊)。在隐空间中融合两个分支,从而提高了从多种退化中还原老照片的能力。提出的方法在视觉质量方面优于现有的老照片修复方法。
1. Introduction
拍照是为了留住往日逝去的幸福时刻。即使时间流逝,人们仍然可以通过查看过去的照片来回忆过去。但是,如果将老照片在较差的环境下打印出来,则会导致其质量下降,从而导致永久性损坏宝贵的照片内容。幸运的是,随着移动相机和扫描仪的使用越来越方便,人们现在可以将照片数字化并请专家进行修复,但是手工修复通常费时费力,这使得大量的老照片无法修复。因此,设计自动算法进行老照片修复是十分吸引人的。
在深度学习发展之前,有一些尝试通过自动检测局部缺陷(例如划痕和污点)并使用修补(inpainting)技术填充受损区域来修复照片。然而,这些方法着重于补全缺失的内容。但它们都不能修复空间中均匀的缺陷(例如胶片颗粒,褪色等),因此与现代摄影图像相比,修复后的图片仍然显得过时。随着深度学习的出现和发展,人们可以通过利用卷积神经网络的强大表达能力来解决各种低级图像修复问题。
但是,同样的框架难以应用于老照片修复。首先,老照片的退化过程十分复杂,目前没有能够真实再现老照片伪影的退化模型。因此,从这些生成数据上学习到的模型难以在真实照片上很好地泛化。其次,老照片中充斥着各种各样的退化现象,而需要不同的处理策略:空间上均匀的非结构化缺陷unstructured defects(例如胶片颗粒film grain和褪色color fading),应通过利用邻域像素进行修复;而结构化缺陷structured defects(例如划痕scratches和灰尘dust spots),需要利用全局图像上下文进行修复。
为了避免这些问题,作者团队将老照片修复问题建模成一个三域转换问题(triplet domain translation)。不同于以往的转换方法,作者团队使用三个域的数据(real old photos, synthetic images和对应的ground truth),在隐空间(latent space)进行translation。合成图像和真实图像首先通过一个共享的变分自动编码器(VAE)映射到同一个隐空间。同时,训练另外一个VAE来将ground truth映射到对应的隐空间。然后利用合成图像对,学习两个隐空间之间的映射,将损伤图像恢复为干净的图像。隐空间恢复的好处在于,因为第一个VAE中的域对齐(domain alignment),学习到的隐空间还原可以很好地泛化到真实照片上。此外,还区分了混合退化,提出一个partial nonlocal block用于考虑隐空间特征的long-range依赖,以专门解决隐空间转换过程中的结构化缺陷。
2. Related Work
2.1. Single degradation image restoration
现有的图像退化大致分为两类:非结构化退化unstructured degradation(例如噪声、模糊、褪色和低分辨率),以及结构化退化structed degradation(例如孔、划痕和斑点)。对于前者,传统方法通常会假设不同的图像先验,包括非局部自相似性(non-local self-similarity)、稀疏性(sparsity)和局部平滑度(local smoothness)。最近,还提出了许多基于深度学习的方法来解决不同的图像退化问题。
与非结构化退化相比,结构化退化更具挑战性,通常被建模为图像修复(image inpainting)问题。得益于强大的语义建模能力,现有的大多数表现最好的修复方法都是基于学习的。(具体的相关工作请参考文章自行了解)。
无论是非结构化还是结构化退化,尽管上述基于学习的方法都可以取得显著的成绩,但它们都是在合成数据上进行训练的,因此,它们在真实数据集上的性能高度依赖于合成数据的质量。对于真实的旧图像,由于它们常常有着未知的严重的混合退化,因此很难准确地描述潜在的退化过程。换句话说,仅使用合成数据训练的网络会有着domain gap的问题而在真实老照片上表现较差。在本篇文章中,作者团队将真实老照片修复建模为一个新的triplet domain translation问题,并采用了一些新技术来最小化domain gap。
2.2. Mixed degradation image restoration
在现实世界,损坏的图像可能会遭受复杂的缺陷,包括划痕、低分辨率、褪色和胶片噪点。但是,解决混合退化的研究却很少。先前工作中有设计设计多个轻量级网络,每个网络负责特定的退化。然后学习一个controller,从toolbox中动态选择轻量级网络,并行执行不同的卷积运算,并使用注意力机制选择最合适的运算组合。但是这些方法仍旧依赖于合成数据进行监督学习,不能很好地泛化到真实照片。此外,它们只关注了unstructured defects,而不支持structured defects。
2.3. Old photo restoration
老照片修复是一个典型的混合退化问题,但现有方法大多只关注于修复。它们遵循一种相似的模式:根据底层特征识别划痕和斑点等缺陷,然后借用附近的纹理进行修补。然而他们的模型和底层特征很难很好地检测和修复此类缺陷。此外,这些方法都没有考虑到修复一些非结构化损失(褪色和低分辨率)。
3. Method
与传统的图像修复问题相比,老照片修复更具有挑战性。首先,老照片包含更复杂的退化,很难将其进行实际建模,并且合成照片与真实照片之间存在domain gap。因此,仅通过从合成数据中学习,网络通常无法很好地泛化到真实照片。其次,老照片的缺陷是多种退化的混合,因此本质上需要不同的修复策略。可以通过利用local patch内的像素,使用空间均匀的滤波器(spatially homogeneous filters)来修复非结构性缺陷,例如胶片噪声、模糊和褪色等。另一方面,应该通过考虑全局上下文来修复划痕和斑点等结构化缺陷,以确保结构一致性。在下文中,作者团队提出了分别解决上述generalization issue和mixed degradation issue的解决方案。
3.1. Restoration via latent space translation
为了减小domain gap,我们将老照片修复公式化为image translation问题,其中干净图像和老照片视为来自不同domain的图像,我们希望学习它们之间的映射关系。然而,与跨两个域的image translation方法不同,我们跨三个域进行translation:真实照片域 \mathcal{R} ,合成域 \mathcal{X} (该域内的图像进行人为退化),和对应的ground truth domain \mathcal{Y} 。这个triplet domain translation至关重要,因为它利用了未标记的真实照片和与ground truth相关的大量合成数据。
将3个域的图像分别表示为: r\in \mathcal{R}, x\in \mathcal{X}, y\in \mathcal{Y} ,其中 x,y 为生成的成对数据,即 x 是从 y 退化得到的。直接从真实图像 \{r\}_{i=1}^N 学习到干净图像 \{y\}_{i=1}^N 的映射是非常困难的,因为它们并没有配对,不适合进行监督学习。因此,作者团队按两阶段分解进行translation,如下图所示。
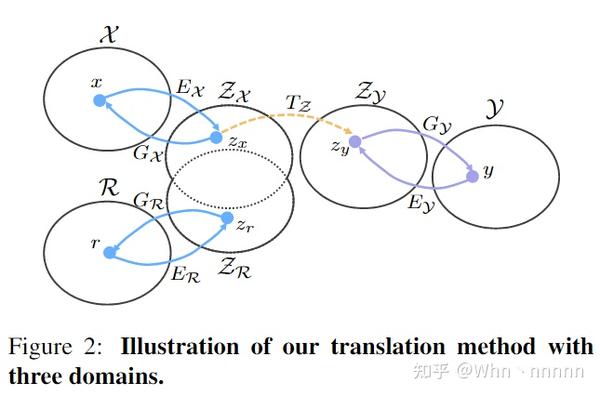

首先将通过 E_\mathcal{R}: \mathcal{R}\rightarrow \mathcal{Z}_\mathcal{R}, E_\mathcal{X}: \mathcal{X}\rightarrow \mathcal{Z}_\mathcal{X}, E_\mathcal{Y}: \mathcal{Y}\rightarrow \mathcal{Z}_\mathcal{Y} 将\mathcal{R}, \mathcal{X}, \mathcal{Y} 映射到对应的隐空间。因为生成图像和真实老照片都是受损的,有相似的外观,通过施加一些约束将它们的隐空间对齐到共享域中,因此我们有 \mathcal{Z}_{\mathcal{R}} \simeq \mathcal{Z}_{\mathcal{X}} 。该对齐的隐空间对所有损坏的图像(合成图像和真实图像)的特征进行编码。然后,学习隐空间中的图像恢复。具体而言,通过利用合成数据对 \{x,y\}_{i=1}^N ,学习从受损图像的隐空间 \mathcal{Z}_{\mathcal{X}} 到ground truth的隐空间 \mathcal{Z}_{\mathcal{Y}} 的映射 \mathcal{T}_{\mathcal{Z}}:\mathcal{Z}_{\mathcal{X}}\rightarrow\mathcal{Z}_{\mathcal{Y}} ,随后 \mathcal{Z}_{\mathcal{Y}} 可以通过生成器 \mathcal{G}_{\mathcal{Y}}:\mathcal{Z}_{\mathcal{Y}}\rightarrow \mathcal{Y} 还原回 \mathcal{Y} 。通过学习隐空间的转换,真实老照片 r 可以依次通过映射 r_{\mathcal{R}\rightarrow {\mathcal{Y}}}=G_\mathcal{Y}\circ T_\mathcal{Z} \circ E_\mathcal{R}(r) 进行修复。
3.1.1. Domain alignment in the VAE latent space
该方法的关键之一是要满足这样的假设: \mathcal{R} 和 \mathcal{X} 编码到同一个隐空间中。为此,我们使用变分自动编码器(VAE)来以紧凑的表示形式将图像编码,它们的domain gap进一步通过一个对抗鉴别器(adversarial discriminator)。使用下图的网络结构来实现这一概念。
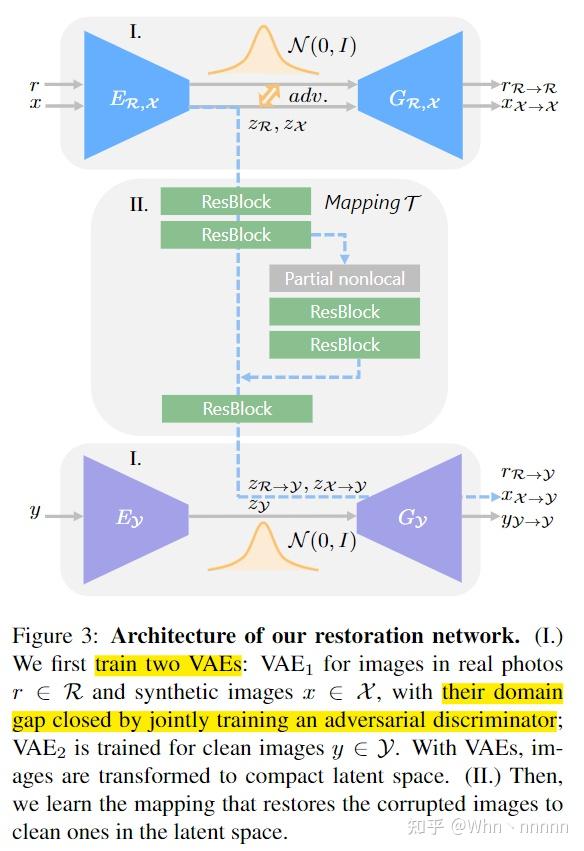
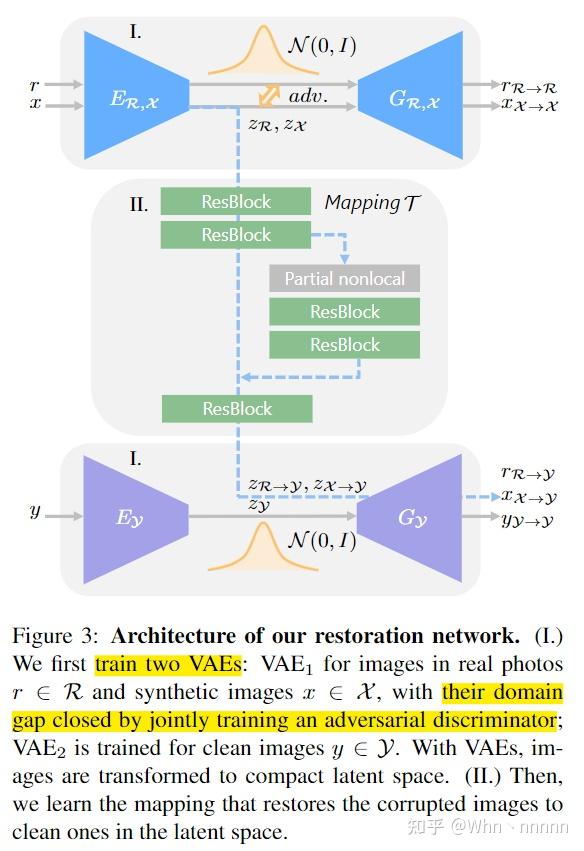
在第一阶段,学习两个VAE用于隐空间表示。老照片 \{r\} 和生成图像 \{x\} 共享第一个VAE,记作 VAE_1 ,编码器为 E_{\mathcal{R},\mathcal{X}} ,生成器为 G_{\mathcal{R},\mathcal{X}} ;而ground truth图 \{y\} 被输入到第二个VAE中,记作 VAE_2 ,编码器和生成器为 \{E_{\mathcal{Y}},G_{\mathcal{Y}}\} 。 VAE_1 被 r 和 x 共享以确保受损域的图片都能够被映射到同一个共享的隐空间。VAE假设隐空间编码(latent codes)的分布为高斯先验(Gaussian prior),所以图片可以通过从隐空间采样来重建。使用re-parameterization trick来实现可微随机抽样,并使用数据 \{r\} 和 \{x\} 优化 VAE_1 。 \{r\} 的优化目标定义为: \mathcal{L}_{VAE_1}(r) = KL(E_{\mathcal{R},\mathcal{X}}(z_r|r)||\mathcal{N}(0,I))+\alpha E_{z_r\sim E_{\mathcal{R},\mathcal{X}}(z_r|r)}[|| G_{\mathcal{R},\mathcal{X}}(r_{\mathcal{R}\rightarrow\mathcal{R}}|z_r) -r ||_1] + \mathcal{L}_{VAE_1, GAN}(r) ,其中 z_r\in \mathcal{Z}_{\mathcal{R}} 是 r 的隐空间编码, r_{\mathcal{R}\rightarrow\mathcal{R}} 为生成的输出。算式中的第一项为KL散度,用于惩罚高斯先验下的隐空间分布差异。第二项 l_1 项使得VAE能够重建输入,使得latent codes能够捕捉图片的主要信息。此外,引入了least-square loss(LSGAN),记作\matl \mathcal{L}_{VAE_1, GAN} 用于处理VAE中的过渡平滑问题,进一步鼓励VAE以高度真实感重建图像。 \{x\} 的优化目标记作 \mathcal{L}_{VAE_1}(x) 也以类似的方式定义。并且针对域 \mathcal{Y} 的 VAE_2 进行相似的训练,以确保对应的隐空间表示 z_y\in\mathcal{Y} 可以正确得出。
我们使用VAE而不是普通的autoencoder是因为VAE由于KL正则化而具有更密集的隐空间表示,并且这有助于为 \{r\} 和 \{x\} 产生更近的隐空间,进而得到更小的domain gap。为了进一步缩小domain gap,建议使用对抗网络来检查residual latent gap。具体来说,训练另一个鉴别器 D_{\mathcal{R},\mathcal{X}} 来区分 \mathcal{Z}_{\mathcal{R}} 和 \mathcal{Z}_{\mathcal{X}} ,其loss定义为 \mathcal{L}_{VAE_1, GAN}^{latent}(r,x) = E_{x\sim\mathcal{X}}[D_{\mathcal{R}, \mathcal{X}}(E_{\mathcal{R},\mathcal{X}}(x))^2] + E_{r\sim \mathcal{R}} [(1-D_{\mathcal{R}, \mathcal{X}}(E_{\mathcal{R},\mathcal{X}}(x)))^2] ,同时, VAE_1 的编码器试图欺骗discriminator,通过一个contradictory loss来确保 \mathcal{R} 和 \mathcal{X} 映射到同一个隐空间。与latent adversarial loss结合, VAE_1 的总的目标函数定义为 \min_{E_{\mathcal{R}, \mathcal{X}}, G_{\mathcal{R}, \mathcal{X} }} \max_{D_{\mathcal{R}, \mathcal{X}}} \mathcal{L}_{VAE_1}(r) + \mathcal{L}_{VAE_1}(x) + \mathcal{L}_{VAE_1 , GAN }^{latent} (r,x)
3.1.2. Restoration through latent mapping
第二阶段,利用VAE捕获的隐空间编码,利用合成图像对 \{x, y\} 并通过映射它们的隐空间来学习图像的还原。隐空间还原的优点在于三方面。首先, \mathcal{R} 和 \mathcal{X} 对齐到同一个隐空间,那么从 \mathcal{Z}_{\mathcal{X}} 到 \mathcal{Z}_{\mathcal{Y}} 的映射可以很好地泛化到修复 \mathcal{R} 中的图片;其次,在紧凑的低维隐空间中的映射在原理上比高维图像空间中更容易学习。另外,由于两个VAE是独立训练的,并且两个流的重建不会彼此干扰。给定从 \mathcal{Z}_{\mathcal{X}} 映射得到的隐编码 z_{\mathcal{Y}} ,生成器 G_{\mathcal{Y}} 总是可以得到干净没有退化的图像,而如果我们学习像素级的translation,退化可能仍然存在。
令 r_{\mathcal{R}\rightarrow\mathcal{Y} }, x_{\mathcal{X}\rightarrow\mathcal{Y} }, y_{\mathcal{Y}\rightarrow\mathcal{Y} } 为 r,x,y 的最终变换输出。在此阶段,仅训练隐空间映射网络 \mathcal{T} 的参数而固定两个VAEs。损失函数 \mathcal{L}_{\mathcal{T}} 既存在于隐空间又存在于生成器 G_{\mathcal{Y}} 的最后,由三部分组成: \mathcal{L}_{\mathcal{T}} (x,y) = \lambda_1 \mathcal{L_{\mathcal{T} ,l_1}} + \mathcal{L}_{\mathcal{T}, GAN} + \lambda_2 \mathcal{L}_{FM} ,其中,隐空间损失 \mathcal{L}_{\mathcal{T} , l_1}=E (|| \mathcal{T}(z_x) -z_y||_1) 用于惩罚隐空间编码的 l_1 距离。仍旧以LSGAN的形式引入对抗损失 \mathcal{L}_{\mathcal{T}, GAN} 以鼓励网络使得合成图像 x_{\mathcal{X}\rightarrow\mathcal{Y} } 看起来更真实。此外,引入了一个特征匹配损失(feature matching loss) L_{FM} 来稳定GAN的训练。具体来说, L_{FM} 匹配对抗网络 D_M 和预训练的VGG网络的多层激活函数(也称为perceptual loss): \mathcal{L}_{FM}=E[\sum_i \frac{1}{n_{D_{\mathcal{T}}} ^i} ||\phi_{D_{\mathcal{T}}} ^i (x_{\mathcal{X}\rightarrow\mathcal{Y} } )-\phi_{D_{\mathcal{T}}} ^i (y_{\mathcal{Y}\rightarrow\mathcal{Y}} ) ||_1 + \sum_i \frac{1}{n_{VGG} ^i} ||\phi_{VGG} ^i (x_{\mathcal{X}\rightarrow\mathcal{Y} } )-\phi_{VGG} ^i (y_{\mathcal{Y}\rightarrow\mathcal{Y}} ) ||_1 ] ,其中 \phi_{D_{\mathcal{T}}}^i (\phi_{VGG}^i) 表示discriminator(VGG)的第 i 层特征图,而 n_{D_{\mathcal{T}}}^i (n_{VGG}^i)表示那一层的activations数量。
3.2. Multiple degradation restoration
使用残差块进行的隐空间还原仅集中于局部特征(local features),因为每一层的感受野大小有限。尽管如此,结构性缺陷仍需要合理的修复,该修复程序必须考虑到long-range dependencies以确保全局结构一致性。由于老照片通常包含混合退化,因此我们必须设计同时支持这两种机制的修复网络。为了实现这一目标,作者团队使用global branch增强隐还原网络,它由考虑全局上下文的nonlocal block和几个残差块组成。我们的nonlocal block会显式地使用mask,因此不会采用损坏区域中的像素来填补这些区域。因为考虑的上下文是特征图的一部分,我们将为latent inpainting设计的模块记作partial nonlocal block
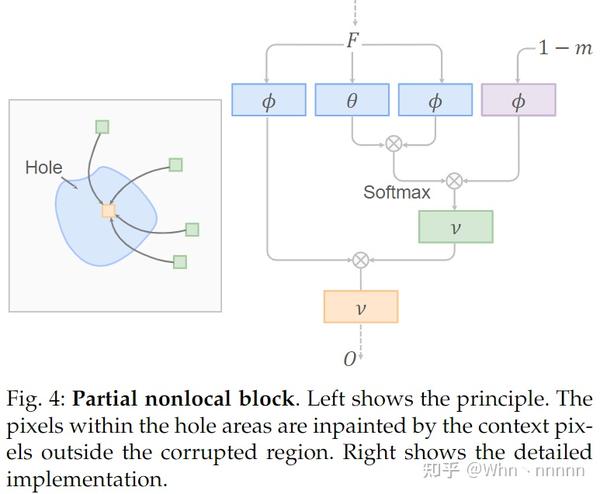

形式上,令 F\in R^{C\times HW} 为 M 中的中间特征图( C,H,W 分别为通道数、高度和宽度), m\in\{0,1\}^{HW} 表示相同大小的二进制mask, 1 表示要修复的缺陷区域, 0 表示完整区域。在 F 中的位置 i^{th} 和位置 j^{th} 之间的亲和度(affinity)记作 s_{i,j}\in R^{HW\times HW} 可以通过 F_i 和 F_j 之间的相关性来计算并根据mask (1-m_j) 进行调制: s_{i,j} = (1-m_j) f_{i,j} / \sum_{\forall k }(1-m_k) f_{i,k} ,其中 f_{i,j} = exp(\theta(F_i)^T · \phi(F_j)) 。
\theta, \phi 将 F 映射到高斯空间用于计算亲和力。根据 s_{i,j} ,考虑mask上的holes,最终输出 O_i= \nu (\sum_{\forall j} s_{i,j} \mu(F_j)) ,它是每个位置的相关特征的加权平均值。使用 1\times1 卷积来实现 \theta, \phi, \mu, \nu
作者专门为inpainting设计了global branch并且希望无孔的区域保持不变,所以将global branch和local branch在mask的指导下进行融合: F_{fuse} = (1-m) \odot \rho_{local}(F) + m \odot \rho_{global}(O) ,其中 \odot 表示按元素乘, \rho_{local},\rho_{global} 表示残差块两个分支的非线性变换。这样,两个分支结构构成了隐空间i恢复网络,该网络可以处理老照片中的多种退化。
4. Experiment
4.1. Implementation
4.1.1. Training Dataset
使用Pascal VOC数据集中的图像来合成旧照片,为了呈现真实的缺陷,还收集了划痕和纸张纹理,这些纹理进一步增加了弹性形变。使用具有随机不透明度级别的layer addition,lighten-only和screen模式来添加划痕纹理。为了模拟大面积的照片损坏,作者生成了带有羽毛状和随机形状的孔,引入薄膜颗粒噪声和随机模糊来模拟非结构缺陷。此外,还收集了5718张老照片,形成了老照片数据集。
4.1.2. Scratch detection
为了检测partial nonlocal block的结构化区域,训练了另一个U-Net结构的网络,首先仅使用合成图像训练检测网络,使用focal loss来纠正正负检测的不平衡。为了进一步提高在真实老照片上的检测功能,团队对783张收集的老照片进行了划痕标注,其中400张用于finetune。
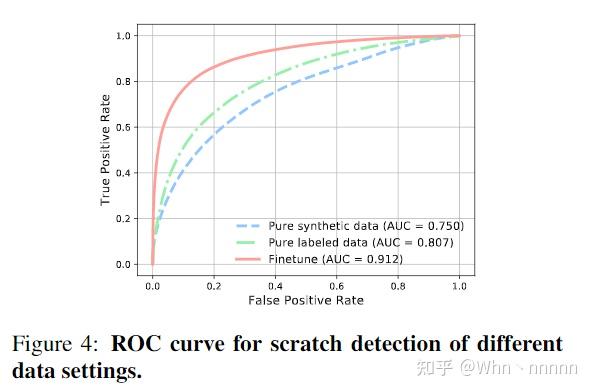

4.1.3. Training details
使用Adam优化器 (\beta_1=0.5,\beta_2=0.999) ,前100个epochs的学习率设置为 0.0002 并逐渐线性减小为 0 .在训练过程中,随机将图片裁成 256\times 256 ,所有的实验中都设置之前式子中的超参数 \alpha=10,\lambda_1=60, \lambda_2=10
4.2. Comparisons
内容实在有点多,这部分写不动了,所以写的略一些,只挑我觉得比较重点的部分,其他贴图,详细还请参考原文进行学习。
4.2.1. Baselines
为了公平比较,使用相同的训练数据集(Pascal VOC),在DIV2K数据集和老照片数据集的测试集上进行测试。比较了如下几个方法:
- Operation-wise attention:使用一个attention机制来选择合适的分支用于处理混合退化恢复;
- Deep image prior:可以进行blind image inpainting
- Pix2Pix
- CycleGAN
- BM3D等一系列传统方法串联
4.2.2. Quantitative comparison
以PSNR和SSIM作为数值指标,此外为了更好地评估视觉效果,还引入了LPIPS指标进行评估(learned perceptual image patch similarity,数值越低越好,可以参考我专栏中关于LPIPS的文章进行更详细的学习和了解)
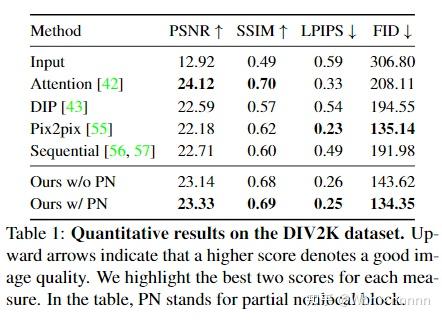
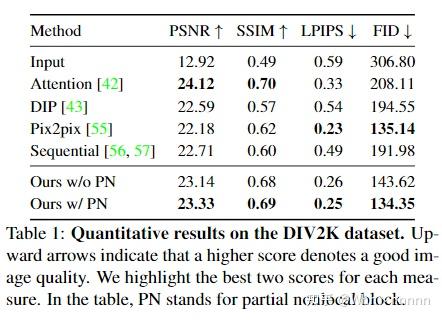
4.2.3. Qualitative comparison
在生成图像和真实照片之间的domain gap是导致方法难以良好地泛化的关键因素。


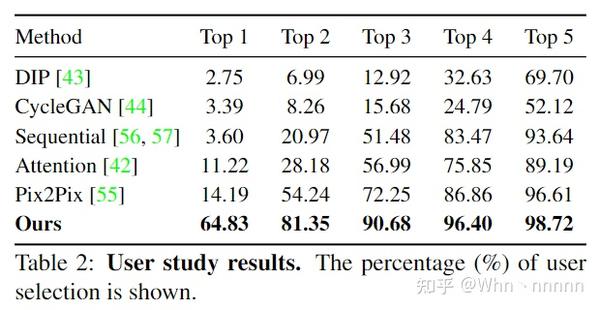
4.2.4. User study
为了更好地反映客观质量,随机从测试集中选择了25张老照片用于user study,选取22位测试者的客观评价得出结论。结果如下,由每位受试者选出效果TOP 5的5个方法并最终计算各自所占的比例。可以非常客观地反映出作者团队的方法的优秀效果,几乎碾压其他所有SOTA方法。

4.3. Ablation Study
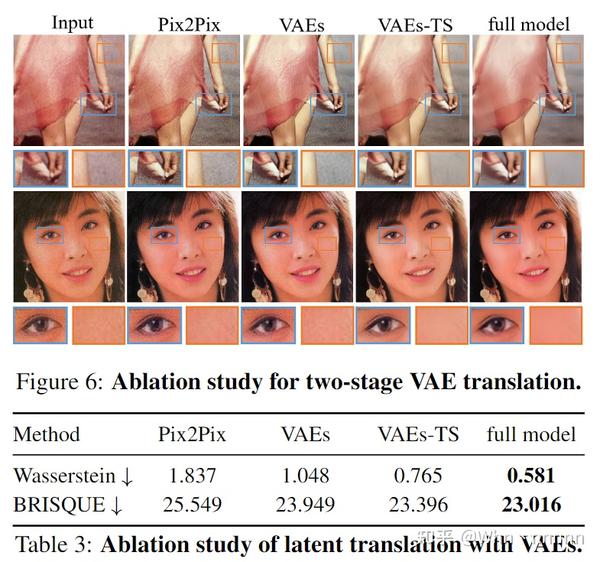

4.3.1. Latent translation with VAEs
这里的几种实验条件具体设置请参考原文对应部分进行了解。消融实验部分得出的结论是,domain gap越小,则模型泛化到真实图像修复时的泛化能力就越好。
4.3.2. Partial nonlocal block


5. Discussion and Conclusion
作者团队提出了一种新的三域转换网络(triplet domain translation network)来修复老照片中的混合退化。减小了老照片和生成图像之间的domain gap,并且在隐空间(latent space)中学习退化图像到干净图像的转换/映射。与基于先验的方法相比,作者团队的方法的泛化问题更少。此外,作者团队还提出了一个partial nonlocal block用于利用全局上下文来恢复隐特征(latent features),因此可以对划痕进行修补,使其具有更好的结构一致性(structural consistency)。作者团队的方法在修复严重退化的老照片时表现出了良好的性能。但是,也有一定的局限性,难以处理某些复杂的阴影,这是因为作者的数据集中几乎没有带有此类缺陷的旧照片。可以通过显式地增加此类数据进行训练以解决该问题。
6. What I want to say
Bring Old Photos Back to Life这篇文章采用的方法效果十分强大,连中CVPR oral和TPAMI的大神团队,2020年暑期时代码还未开源,目前已经开源并且有7.5k星!代码实际实现时还针对人脸是老照片中的关键主体元素这一点进行了额外的处理,包括人脸检测和人脸部分的修复。并且该模型还能从整体上在色彩方面对老照片进行修复,使得老照片重获生机。目前GitHub上已开源测试代码和预训练模型,预计以后会进一步开源训练代码,不过单从预训练的模型来看,仅部分预训练模型的大小就已经达到1G,如此庞大的网络应该是很难自己从零复现并达到理想的效果的。再给开发团队点个赞~
