数据科学之路:因果推断入门

1. 数据科学
数据科学家被哈佛商业评为21世纪最具新引力的职业之一。这并非空穴来风,近十年以来,数据科学家一直站在聚光灯下,人工智能专家的收入一定程度上可以与体育明星一较高下。在这场追求名利的浪潮中,许许多多从业人士在这场热潮中熙熙攘攘,以尽快获得数据科学家的title。各种各样割韭菜方式层出不穷,满眼的“AI入门到精通”的网络教程都在教你如何在21天成为一名数据科学家,并且不需要你看一眼数学公式;数据科学顾问许诺一旦采纳他们的方案,可以为公司带来百万美金的回报,每个人都赚得破满钵满。
事实真的如此吗?数据科学是什么?数据科学和AI是什么关系呢?
在这个小学生都可以顺口溜出几个大数据的名词的时代中,我们的很多领域专家依旧在延续着“传统”的数据分析之道上进行耕耘:经济学家尝试各种方式研究教育程度如何影响收入、生物统计学家试图解释饱和脂肪如何导致心脏病、心理学家试图分析肯定的话与幸福婚姻的关系。我们想说的是数据科学家并不是一个新兴领域,只是由于媒体的大肆营销和宣传,这一职业才进入了大众视野,从而显得很“年轻”。
如果平时喜欢喝啤酒,你最终会发现,在倒酒姿势正确的前提下,酒杯中会呈现下面的状态:
- 酒杯中表面有一层泡沫,最终会破灭(啤酒越好,持续时间越长)
- 酒杯下面绝大多数是啤酒,这层才是口感最好的部分


为什么说啤酒这个例子呢?因为但凡媒体鼓噪的领域均存在不同程度的泡沫,现在数据科学、人工智能的热潮也不会例外。只有泡沫破灭,最有价值的部分(啤酒)才会显露出来,这个才是数据科学、人工智能真正的归宿和价值所在。
在成为数据科学家(姑且这么叫吧)、人工智能从业者这条路上,也不存在什么捷径,更不要去信21天称为人工智能专家的规划,培训机构的镰刀时刻向你敞开。作为一个数据科学的入门选手,最基本的操作应该是避开哪些泡沫、避免成为韭菜,数学和统计学是绕不开的知识壁垒,持续不断的学习能力也是绕不开的话题,加油!
2.Predict-based的机器学习算法
目前大家谈论的机器学习算法都是Predict-based的算法,这类算法非常擅长解决的事情是预测问题,利用机器学习算法解决问题的唯一要求是将问题定义为预测问题:
- 识别人脸,构建一个 ML 模型,该模型预测图片中是否存在人脸
- 识别是否点击广告,构建一个CTR模型,模型预测该广告是否被点击
Predict-based的机器学习算法虽然普适性很好,但是基本是基于目标和特征的相关性进行决策,决策结果可能会带来一些问题:在许多行业中,低价格与低销量呈现相关性,如酒店行业,旅游旺季以外的时候价格低,而需求旺盛、酒店爆满时价格高。Predict-based的机器学习算法决策的结果可能是一个ML模型的预测结果可能表明提高价格会导致酒店出售更多的房间。
Predict-based的机器学习算法在这种逆因果关系类型的问题上显得力不从心。因为它们要求我们回答“what if”问题,经济学家称之为反事实(counterfactual),这些例子在现实空间不可能存在,除非我们有一个平行空间供我们选择:
如果我目前商品的定价不是这个价格,而是使用另一个价格,会发生什么情况?
如果我不再进行低脂饮食,而是改为低糖饮食,会发生什么?
这些问题的核心在于我们希望研究现象与效果之间的量化关系,现有的相关性模型不能够满足因果性研究的需求,从而引出了一个新的AI分支--因果推断。
因果推断是在一个较大系统内部确定指定现象(因)的实际、独立效果(果)的过程。因果推断和相关性推断的主要区别是前者分析结果变量在其原因变量变化时发生的回应。 研究事物起因的科学则称作原因论。因果推断可给出因果关系推理建立的因果关系模型的证据
因果问题在日常问题中随处可见:
- 例如销售公司如何提高销售额?
- 移民是否会降低个人找工作的机会(移民是否会导致失业率上升)?
- 向穷人汇款会降低犯罪率吗?
不管你在哪个领域,很可能你也需要处理某种类型的因果问题,因果推断就成为我们研究这些因果问题的有效手段。
3. 相关性≠因果性
从common sense的角度,很容易理解为什么相关不是因果关系,但是如何量化和解释这种因果性的关系是一个需要深入研究的话题:
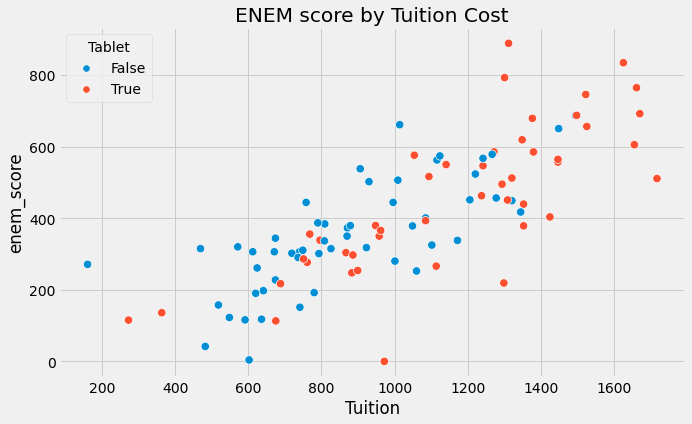
如果有人告诉你,给学生提供平板电脑的学校比不给学生提供平板电脑的学校学生成绩更好。你可能会很快指出,有平板电脑的学校更有钱、师资好等因素是导致成绩好的原因,即使没有平板电脑,它们也会比平均水平的学校成绩更好。所以不能得出结论,给孩子提供平板电脑会提高他们的学习成绩。(这里使用的ENEM可以参考链接)
所以在这个case上,只能说学校提供平板电脑与成绩表现正相关。
import pandas as pd
import numpy as np
from scipy.special import expit
import seaborn as sns
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
np.random.seed(123)
n = 100
tuition = np.random.normal(1000, 300, n).round()
tablet = np.random.binomial(1, expit((tuition - tuition.mean()) / tuition.std())).astype(bool)
enem_score = np.random.normal(200 - 50 * tablet + 0.7 * tuition, 200)
enem_score = (enem_score - enem_score.min()) / enem_score.max()
enem_score *= 1000
data = pd.DataFrame(dict(enem_score=enem_score, Tuition=tuition, Tablet=tablet))
plt.figure(figsize=(6,8))
sns.boxplot(y="enem_score", x="Tablet", data=data).set_title('ENEM score by Tablet in Class')
plt.show()

在深入探讨之的过程中,引入的变量名如下:
i :表示第 i 个体(unit);
T_i :对个体 i 施加的干预(treatment);
T_i=\begin{cases} 1 \ \text{if unit i received the treatment}\\ 0 \ \text{otherwise}\\ \end{cases}
Y_i :表示在个体 i 上观察到的结果(outcome)输出,也就是因果推断的果
Y_{0i} :表示个体 i 没有施加Treatment的潜在结果(potential outcome);
Y_{1i} :表示个体 i 施加Treatment的潜在结果(potential outcome)
上面提到的考试成绩的问题中,关键问题是我们如何量化平板电脑 T 对学习成绩( Y )的影响,但是现实的约束是在于我们永远无法同时观察到在同一个体上施加干预和不施加干预的结果,这也导致了因果性问题的复杂度远超于Predict-based的机器学习算法。
那我们应该如何解决这种counterfactual约束呢? 在因果性问题的研究过程中,经常会提到potential outcomes这一概念。之所以称为potential,是因为Treatment并未发生下的outcome(counterfactual):
潜在结果模型(Potential Outcomes Model)是其中最重要的理论模型之一,其核心是比较同一个研究对象(Unit)在接受干预(Treatment)和不接受干预(Control)时结果差异,认为这一结果差异就是接受干预相对于不接受干预的效果。对于同一研究对象而言,通常我们不能够既观察其干预的结果,又观察其不干预的结果。对于接受干预的研究对象而言,不接受干预时的状态是一种“反事实”状态;对于不接受干预的研究对象而言,接受干预时的状态也是一种“反事实”状态;所以该模型又被某些研究者称之为反事实框架(Counter factual Framework)。潜在结果模型的主要贡献者是哈佛大学著名统计学家唐纳德·鲁宾(Donald B.Rubin),因此该模型又被称为鲁宾因果模型(Rubin Causal Model)。不过,鲁宾(Rubin,2005)并不认同“反事实框架”的概念,他认为结果的出现与否主要取决于干预机制(Assignment Mechanism),这并不意味着一种结果不存在,只是我们事实上只能够看到一种结果。对于鲁宾而言,潜在结果是一个更合适的概念。考虑到这一理论主要是由鲁宾开创并持续推动这一研究,我们在介绍该理论时,也使用了潜在结果模型的概念。
回到学校学生成绩的例子, Y_{1i} 表示有平板电脑的学生的成绩, Y_{0i} 表示没有平板电脑的学生的成绩,需要明确的是:对于一个学生而言,我们只能观察到 Y_{1i} 或 Y_{0i} ,而不能同时观察到两者。当观察到Y_{1i}时,Y_{1i}即观察到的实际结果,而Y_{0i}即反事实的潜在结果(counterfactual potential outcome),因为我们观察不到。

在潜在结果框架下,个体因果效应(individual Treatment effect)可以表示为:
Y_{1i}-Y_{0i}
在counterfactual的约束下,永远无法计算ITE,所以在推断上使用平均因果效应(average Treatment effect)来代替ITE,其定义如下:
ATE = E[Y_1 - Y_0]
其中 E[...] 是期望值,另一个较容易量化的ITE近似值是在Treatment下的平均因果效应:
ATT = E[Y_1 - Y_0 | T=1]
在potential outcomes framework下,我们可以近似使用ATE、ATT来近似个体在不同Treatment下的outcome。在这个框架下,可以量化两种Treatment下的potential outcome。假设收集了 4 所学校的数据,数据包含是否向学生提供平板、考试成绩,在这里 T=1 表示给予学生平板电脑, Y 表示考试成绩:
pd.DataFrame(dict(
i= [1,2,3,4],
y0=[500,600,800,700],
y1=[450,600,600,750],
t= [0,0,1,1],
y= [500,600,600,750],
te=[-50,0,-200,50],
))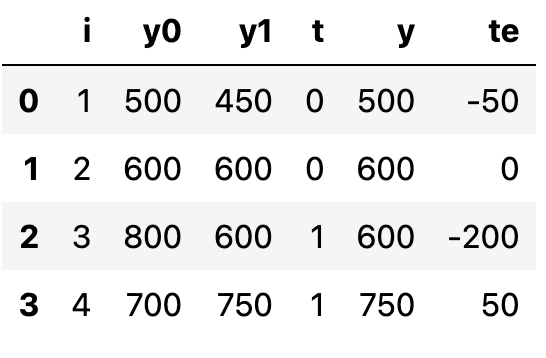

所以ATE可以近似使用最后一列( te )来近似ITE:
ATE=(-50 + 0 - 200 + 50)/4 = -50
这意味着平板电脑会使学生的学习成绩平均降低 50 分,ATT可以表示为 t=1 的情况下最后一列( te )的均值;
ATT=(- 200 + 50)/2 = -75
这表明对于 Treatment=1 的学校,平板电脑使学生的学习成绩平均降低了 75 分。
当然,现实世界中我们永远无法观测到上面分析结果,实际中的收集的数据可能如下:
pd.DataFrame(dict(
i= [1,2,3,4],
y0=[500,600,np.nan,np.nan],
y1=[np.nan,np.nan,600,750],
t= [0,0,1,1],
y= [500,600,600,750],
te=[np.nan,np.nan,np.nan,np.nan],
))

可以使用干预的平均成绩减去未干预过的平均成绩近似ATE吗?
ATE=(600+750)/2 - (500 + 600)/2 = 125
答案是否定的,因为这种估计结果是建立在相关性=因果性的假设前提下的(很显然这一结果并不成立)。
4.偏差(Bias)
数据偏差是相关性!= 因果关系的主要原因。回到上面考试成绩的例子,即使没有平板电脑,这些学校也可能会获得更高的考试成绩:
提供平板电脑的学校比其他学校有更多的钱;可以聘请更好的教师、负担更好的教室等。施加Treatment的学校(平板电脑)与没有施加干预的学校本来在资源规模上就没有可比性。
在在potential outcomes framework下:
- 实验组的 Y_0 和对照组的 Y_0 是不同的
- 实验组的 Y_0 是反事实的,无法观察到它,但可以推理
从社会的基本常识可以得出实验组的 Y_0 是大于对照组的 Y_0 的,因为为孩子提供平板电脑的学校也能具备其他有助于提高考试成绩的因素(具有更多的社会资源统筹能力)。
从数学角度描述一下为什么相关不是因果关系?
- 相关性的Treatment effect可以表示为 E[Y|T=1]−E[Y|T=0]
- 因果性的Treatment effect可以表示为 E[Y_1−Y_0]
为了清晰的表示相关性和因果性之间的关系,可以将观察到的结果替换为潜在结果。对于实验组,观察到的结果是 Y_1 , 对于对照组,观察到的结果是 Y_0 :
E[Y|T=1]−E[Y|T=0]=E[Y_1|T=1]−E[Y_0|T=0]
同时考虑到 E[Y_0|T=1] ,这是一个counterfactual的推理:E[Y|T=1]−E[Y|T=0]=E[Y_1|T=1]−E[Y_0|T=0]+E[Y_0|T=1]−E[Y_0|T=1]
即得到:
E[Y|T=1] - E[Y|T=0] = \underbrace{E[Y_1 - Y_0|T=1]}_{ATT} + \underbrace{\{ E[Y_0|T=1] - E[Y_0|T=0] \}}_{BIAS}
这个公式包含了我们在因果问题中会遇到重要问题:
- 这个等式说明了为什么相关不是因果关系,相关等于对实验组的Treatment效果加上一个偏差项
- 偏差是由实验组和对照组在干预前的差异决定的
回到上面的例子,这就解释了对”平板电脑对学习成绩有促进作用“这一结论的不置信,因为在干预前 E[Y_0|T=0]<E[Y_0|T=1] ,即有能力为学生提供平板电脑的学校本身( E[Y_0|T=1] )就比没有能力为学生提供平板电脑的学校( E[Y_0|T=0] )在学习成绩的表现上更好
因果推断的关键在于消除偏差!
如果深入去研究bias产生的原因,是因为许多我们控制一些不可观测的变量(or 不在认知范围内的变量)跟Treatment之间的相关性导致的。也就是说上面例子中,上面这些学校不仅是否给予学生平板电脑上有所不同,更深层次上在社会资源、师资、学生质量等方面都有显著性的不同。所以如果需要准确的量化平板电脑对学习成绩的影响这个问题中,需要剔除调社会资源、师资、学生质量等因素造成的bias(下图是考试成绩跟学费的相关性结果,可能比平板电脑这个Treatment更具影响力)。

什么情况下,相关性=因果性?
通过上面可以得出,只有在 E[Y_0|T=1]=E[Y_0|T=0] 情况下相关性=因果性。 E[Y_0|T=1]=E[Y_0|T=0] 表示在Treatment干预前,实验组和对照组没有明显的差异。在这种情况下相关性=因果性,也就是说在这种情况下bias项可以不用考虑,ATT表示为:
E[Y|T=1]- E[Y|T=0] = E[Y_1 - Y_0 | T=1] =ATT
如果实验组和对照组仅仅在Treatment上面存在差异,也就是 E[Y_0|T=1]= E[Y_0|T=0] ,那么Treatment的Causal effect可以表示为:
\begin{align} E[Y_1-Y_0|T=1] &= E[Y_1|T=1]-E[Y_0|T=1] \\&= E[Y_1|T=1]-E[Y_0|T=0]\\ &= E[Y|T=1]-E[Y|T=1] \end{align}
在这种情况下,ATE效果如下(蓝点表示没有收到平板电脑,红点想反):
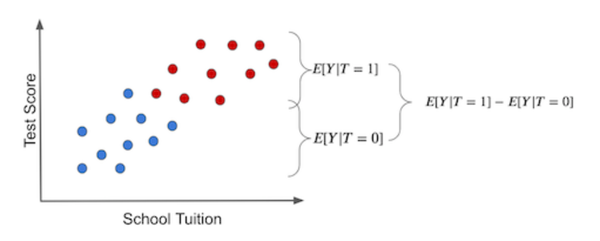

通过上面的分析可以得出造成因果推断在outcome的评估上可以拆解为两个问题:
- The treatment effect,也就是上面说的平板电脑对学习成绩的提升效果
- 非Treatment因素因素引起的outcome变化,在这个例子中如资源、学费、师资等
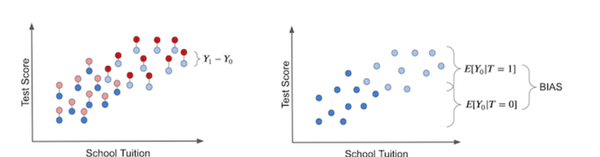
但是真正的Treatment effect,我们只有平行宇宙的能力下才能够观察到potential outcome,跟下面的左图一样。如果没有平行宇宙的手段,ITE的效果只能通过个体的实际outcome和理论框架inference的outcome进行拟合,如下图的右图所示:

RCT(Randomized Controlled Trial,随机对照试验)
现在考虑另外一种随机化实验情况,可能会显著性降低bias项的影响:完全随机确定平板电脑给予哪个学校。在这种情况下,资源多、少的学校均有平等机会获得平板电脑这一Treatment,可能的结果如下图:
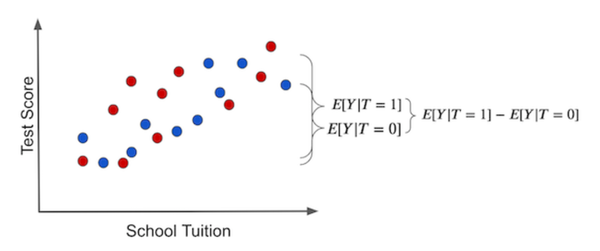

在RCT的条件下,treated和untreated的diff就可以作为ITE的一个表征手段。在这种情况下outcome的情况完全由Treatment确定(假设随机程度满足要求):
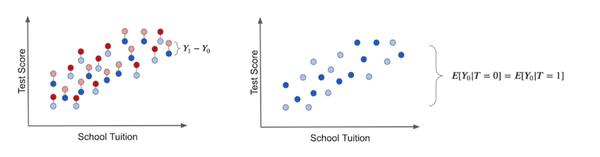

上面就是Causal Inference探究的重要问题,使用各种方法进行消偏(减小bias项的影响)!
