JSIS3D论文笔记

JSIS3D: Joint Semantic-Instance Segmentation of 3D Point Clouds with Multi-Task Pointwise Networks and Multi-Value Conditional Random Fields(CVPR2019)
论文链接:https://arxiv.org/abs/1904.00699
代码(pytorch)链接:pqhieu/jsis3d


Problem & Motivation
在3D场景理解中,语义分割和实例分割通常是分开处理的。要么是单独进行语义分割,要么是单独进行实例分割,要么是在语义分割后再进行实例分割。但是作者认为目标的语义种类及其实例是相互依赖的,比如,从某个实例上提取的shape和appearance信息能够帮助该实例进行种类预测,另外,如果点云中的两个点被语义分割成了两种类别,那么这两个点是不可能会属于同一个实例的。基于这一认识,作者提出了同时处理3D点云语义分割和实例分割的网络——JSIS3D,并在S3DIS和SceneNN数据集上达到了点云语义分割的SOTA。
Method
整体的网络结构如下图所示:对于输入的完整场景的点云,作者首先用重叠的3D windows对其进行扫描将点云分块输入到MT-PNet(Multi-Task Point-wise Network)子模块中,在该模块中同时进行点云的语义和实例分割并产生语义类别标签预测和实例嵌入标签预测,之后再将MT-PNet的输出融合起来馈入到MV-CRF(multi-value conditional random field)子模块中进行变分推断(对上一步的预测结果进行refine),最终输出整个点云的语义和实例分割结果。
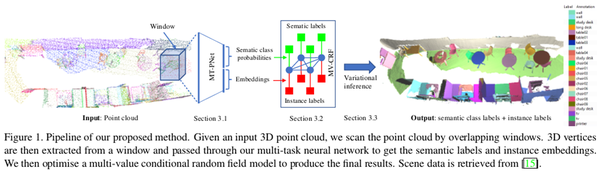

- MT-PNet
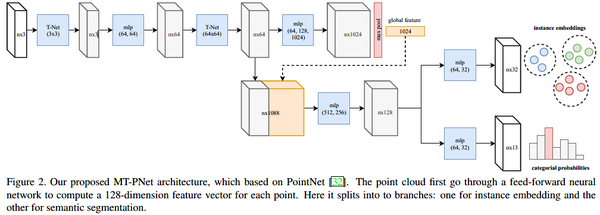

MT-PNet是基于pointnet的改进,主要是将输出变成了两个分支,一个是语义分割head,一个是实例嵌入head,其损失函数如下:
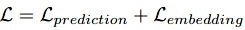
也由两个部分组成,第一个语义类别预测部分和pointnet一样定义为普通的交叉熵损失;第二个实例嵌入部分定义为:
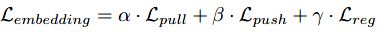
其中Lreg用于回归每个实例的重心点,Lpull用于聚集每个实例的嵌入点,Lpush用于排斥各个不同实例的重心点。
2、MV-CRF
定义
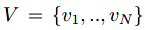
为输入的点云,
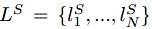
为与输入的点云对应的语义label,
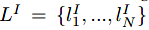
为与输入点云对应的实例label。作者将带有两个label的结点V所表示的概率图定义为MV-CRF。因此,对点云V的语义 - 实例分割可以通过最小化下面的能量方程来实现:
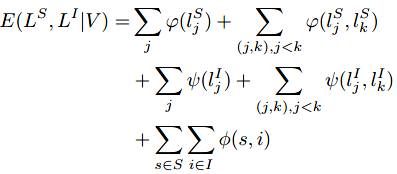
其中概率

表示每个点vj语义分类的cost,pair-wise的概率
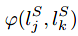
为j点和k点语义分类的分数相似性,
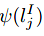
使得属于同一个实例的嵌入点尽可能地接近该实例所有嵌入点的平均值,pair-wise的概率
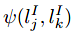
表示j点和k点的实例lable的相似性(该相似性由j点和k点的位置、表面法向量、颜色等属性联合确定),
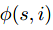
使得语义label和实例label保持一致性(比如,如果两个点预测为相同的实例,则这两个点也应该预测为相同的语义类别)。
Experiments
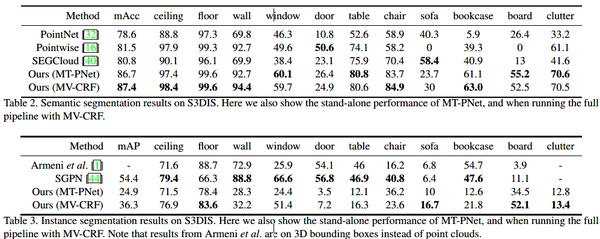
S3DIS上语义分割和实例分割的结果:

SceneNN上语义分割和实例分割的结果:


S3DIS和SceneNN上语义分割和实例分割的效果图:


Thoughts
- 作者将点云的语义分割和实例分割结合起来同时处理,确实可以相互促进,在以后对点云的处理当中也可以进行借鉴;
- JSIS3D能够在语义分割上达到SOTA,但在实例分割上做不到,我觉得其原因可能是因为基于点云嵌入的实例分割方法相比于基于proposal的实例分割方法其objectness还是不够,如果能够找到别的强objectness的算法,该网络的性能应该会有进一步的提高。
