语音识别中,声学模型与语言模型扮演什么角色?或者说是怎么通过两个模型进行语音识别的?


答主 @王赟 Maigo 的回答已经把声学模型,发音词典和语言模型的关系过程阐述的很清晰了,本回答主要针对神经网络语言模型在语音识别中的应用做一些补充。
神经网络语言模型
先来简单回顾一下神经网络语言模型。语言模型 (Language Models) 是语音识别系统中的重要组成部分,语音识别的核心公式如下
P(\boldsymbol W|\boldsymbol O)=\frac{ p(\boldsymbol O|\boldsymbol W)P(\boldsymbol W)}{p(\boldsymbol O)}\propto p(\boldsymbol O|\boldsymbol W)P(\boldsymbol W)\tag 1 \\
其中 P(\boldsymbol W) 就是语言模型,语言模型用于计算一段词序列 \boldsymbol W =\left \{ \boldsymbol w_1,\boldsymbol w_2,\dots,\boldsymbol w_n \right \} 的概率
P(\boldsymbol W) = P({{\boldsymbol w}_1,...,{\boldsymbol w}_n})=\prod_{t=1}^{n} P({{\boldsymbol w}_t|{\boldsymbol w}_{t-1},..., {\boldsymbol w}_1})\tag2\\
这可进一步表示为一系列单个词的条件概率的乘积,这些条件概率取决于它们各自的前文序列。这也是当前统计语言模型的核心公式,在大规模训练语料库中用合适的模型统计分析得到词与词之间的关系依赖,即语义信息。n 元语法模型就是用马尔科夫假设限制了前文的长度,然后用频率近似代替概率,是一种非常简单有效的建模方法。从公式 (2) 中可以看出统计语言建模的关键是学习长距离前文依赖关系 (long-span context depedency),但是用 n 元语法模型直接对长距离历史信息进行建模,即 n 的取值较大时,通常会由于需要统计的情况呈指数级增长,并且很多种情况不会出现在语料库中,从而导致严重的数据稀疏问题,这也是 n 元语法模型的局限。
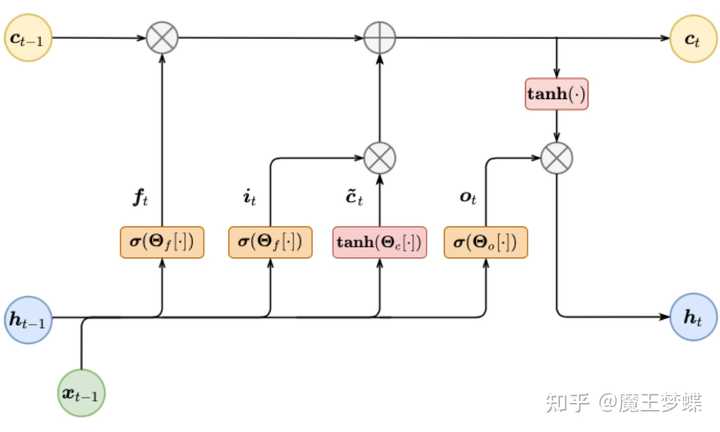
近些年随着深度学习的发展,神经网络语言模型 (neural network language model) 由于能将词向量映射到低维连续空间,因此逐渐成为主流方法,具备不错的泛化性能。最早的神经语言模型是基于前馈神经网络 (feedforward neural network, FNN) 的,初步实现了对长文本序列在低维连续空间的建模,但这种方法能够处理的文本长度依然受限于网络的输入长度,而后循环神经网络 (recurrent neural network, RNN) 为代表的语言模型利用循环结构则可以在理论上对无限长的文本建模,性能得到极大提升;而后基于长短期记忆循环神经网络 (long short-term memory recurrent neural network, LSTM-RNN) 的语言模型则适当解决了 RNN 在长历史序列建模时梯度消失的问题,如下图所示,在各种任务上都取得不错的效果。

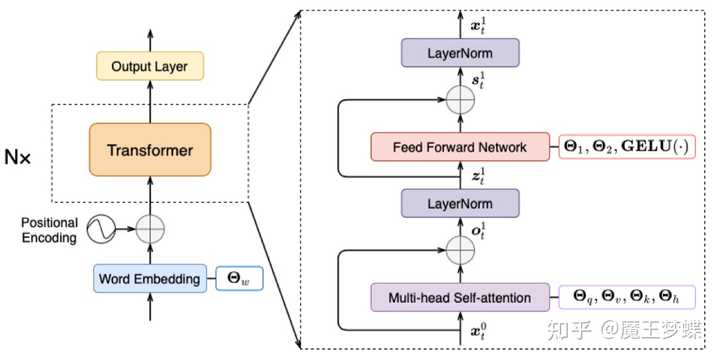
近年来基于 Transformer 的语言模型在自注意力机制作用下对长文本具有更强的建模能力,包括一个自注意力层和前馈层,以及残差连接,层归一化等模块,再利用位置编码引入单词序列的顺序信息,如图 2 所示,Transformer 语言模型在一系列自然语言和语音的任务上均取得最优性能。

从上述语言模型的发展中可以看出,研究核心在于如何提高模型对于长历史序列信息的建模能力,这也是神经语言模型在语音识别应用中需要考虑的核心问题。
语音识别中的语言模型重打分
从公式 (1) 中可以看出,语言模型 P(\boldsymbol W) 在语音识别任务中是作为一个先验项的,在贝叶斯公式中也确然如此。声学模型 P(\boldsymbol X|\boldsymbol W) 是为了找出能产生声学信号 \boldsymbol X 的最有可能的 \boldsymbol W ,但是在隐马尔科夫模型中我们可知实际上声学模型找到的是每一帧语音对应的最大概率的文本,因此只用声学模型得到文本序列是不考虑语义信息的,由于同音字词的存在识别结果往往很差;而语言模型就是在正常语料上训练,在声学模型得出的结果中选择出最符合语义和语法习惯的结果,因此语言模型虽然只是一个先验项,但在实际应用中是不可或缺的。
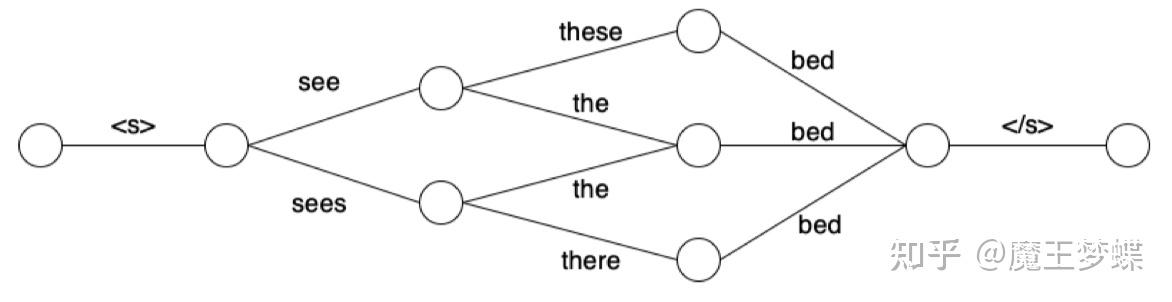
在声学隐马尔科夫模型上得到我们想要的结果的过程称为语音识别的解码 (decoding),使用较多的方法有动态网络 (dynamic network) 解码,有限加权状态转换器 (weighted finite state transducer) 解码等。在利用声学模型和发音词典把音素等信息解码为单词信息后,我们会在进行剪枝等一系列操作后把结果存储在一张图之中,称为词图 (lattice),如下图所示

对词图直接解码往往可以产生多条候选结果,我们可以利用性能更好的语言模型,重新评估所有的候选序列,得到最优的识别结果。在之前搜索与解码一节中,讲述了在解码初期通常会加入一些简单的 n 元语法模型作为先验,这是由于 n 元语法模型相对简单,历史序列较短且自带概率信息,而神经语言模型每次概率值都需要计算,其输出层的 Softmax 函数计算复杂度较高,且更适合长文本序列的建模,因此神经语言模型并不适用于早期解码过程,一般都是用于对初次解码结果进行重打分,有 N-best list 重打分和词图重打分 (lattice rescoring) 两种方法。
N-best list 重打分
N-best list 重打分较容易理解,就是直接在词图上进行解码得到 N 条最好的结果,称为 N-best list。然后引入一个神经语言模型对所有结果重新打分然后排序,选出最好的结果。由于神经网络语言模型对自然语言的建模能力比 n 元语法模型更强,因此,神经网络语言模型重打分对语音识别结果的准确率有较大的提升,如下图所示
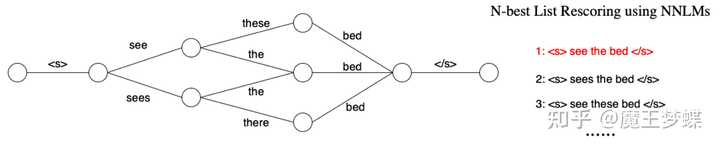

然而 N-best list 重打分的性能很大程度上依赖于 N 的取值,当 N 取值较大时,会出现大量的冗余信息导致重复计算,而当 N 取值较小时,实际上的搜索空间很小,很难保证所取 N-best list 包含较好的结果,导致很多有用信息丢失,扩展性不强。而且这种方法需要将整个句子输入后才能得到最终识别结果,在实时语音应用场景中会出现一定延迟。
词图重打分
另一种方法是直接在词图上重打分,词图重打分是对于初始解码生成的词图进行遍历扩展,利用语言模型将词图中所有的边上的分数重新计算,存储为新的词图,取词图中的最优路径得到解码结果。这种方法采用拓扑排序的方式遍历词图的每一条边,并且在遍历时记录下从开始节点到当前节点路径上的词序列,作为当前词的历史信息,因此可以充分利用此图中所有信息。
由于词图是一种图的表示形式,必然会出现某一个节点是多个节点的后继,可以称为汇聚节点,如图 4 中两条边 the 汇聚到同一节点。对于汇聚节点,由于有存在多条路径于它和开始节点之间,使得当前词存在多个历史。在遍历到汇聚节点时,我们需要构造出该节点的拷贝节点,将其扩展成一系列节点,并将其连接的边全部复制过来,如下图 5 所示,边 the 之后的节点会存在两条不同的序列。因此这种方法存在搜索空间巨大的问题,尤其是神经语言模型是基于长历史序列建模,为了在计算后面单词时考虑所有可能的路径,需要对词图进行扩展,而这种扩展会呈指数级增长,计算资源和内存消耗大,解码速度慢。
为了解决这一问题,减小运算复杂度,可以使用一些历史聚类或剪枝等策略。所谓历史聚类 (history clustering),就是对于两个不同的历史向量,用一定的方法测量到两者的相似度,当两者相似度达到一定程度时,可以近似认为是同一路径。可以采用 n 元语法模型或其他方法进行聚类,把合并相似的路径,降低计算量。这种方法一定程度上借鉴了马尔科夫假设,即认为长距离的词其对当前词的影响会逐步减少,因此对最近的一段序列进行聚类,如下图 5 所示
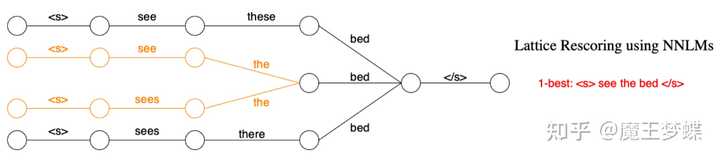

可以看出,在图 4 的原始词图进行回溯时,相似的路径 <s> see the 和 <s> sees the 可以视为相同的路径。历史聚类由于能在汇聚节点处将相似的历史通过聚类方法合并,因此对汇聚节点进行扩展时,可有效减少扩展次数,从而减少神经网络语言模型的计算量,这种在词图重打分的方法产生出的 1-best 路径可以取得和 n-best list 重打分相当的效果,而且可以在每一步都产生出当前最优的序列,因此也可以广泛用于实时语音识别等任务中。