动态滤波器卷积|DynamicConv


paper: https://arxiv.org/abs/1912.03458
该文是MSRA的研究员提出的一种动态卷积。它是在卷积的基础上进行了“魔改”,不同于传统卷积采用单一卷积核方式,作者提出了一种动态卷积机制,它有助于提升模型的特征表达能力。
Abstract
相比高性能深度网络,轻量型网络因其低计算负载约束(深度与通道方面的约束)导致其存在性能降低,即比较有效的特征表达能力。为解决该问题,作者提出动态卷积:它可以提升模型表达能力而无需提升网络深度与宽度。
不同于常规卷积中的单一核,动态卷积根据输入动态的集成多个并行的卷积核为一个动态核,该动态核具有数据依赖性。多核集成不仅计算高效,而且具有更强的特征表达能力(因为这些核通过注意力机制以非线性形式进行融合)。
通过简单地额替换动态卷积,MobileNetV3-small取得了2.3%的性能提升且仅增加了4%的FLOPS,在COCO关键点检测任务中取得了2.9MAP性能提升。
Method
动态卷积的目标在于:在网络性能与计算负载中寻求均衡。常规提升网络性能的方法(更宽、更深)往往会导致更高的计算消耗,因此对于高效网络并不友好。
作者提出的动态卷积不会提升网络深度与宽度,相反通过多卷积核融合提升模型表达能力。需要注意的是:所得卷积核与输入相关,即不同数据具有不同的卷积,这也就是动态卷积的由来。
Dynamic Perceptron
首先,作者定义传统的感知器为y = g(W^Tx +b),其中W,b,g分别表示权值、偏置以及激活函数;然后,作者定义动态感知器如下:
y = g(\tilde{W}^T x + \tilde{b}) \\ \tilde{W} = \sum_{k=1}^{K}\pi_k(x) \tilde{W}_k \\ \tilde{b} = \sum_{k=1}^{K} \pi_k(x) \tilde(b)_k \\ s.t. 0 \le \pi_k(x) \le 1, \sum_{k=1}^{K} \pi_k(x) = 1 \\
其中\pi_k表示注意力权值。注意力权值并非固定的,而是随输入变化而变化。因而,相比静态卷积,动态卷积具有更强的特征表达能力


相比静态感知器,动态感知器具有更大的模型。它包含两个额外的计算:(a)注意力权值计算;(2)动态权值融合。尽管如此,这两点额外计算相比感知器的计算量可以忽略:
O(\tilde{W}^T x +\tilde{b}) >> O(\sum \pi_k \tilde{W}_k) + O(\sum \pi_k \tilde{b}_k) + O(\pi(x)) \\
Dynamic Convolution
类似于动态感知器,动态卷积同样具有K个核。按照CNN中的经典设计,作者在动态卷积后接BatchNorm与ReLU。
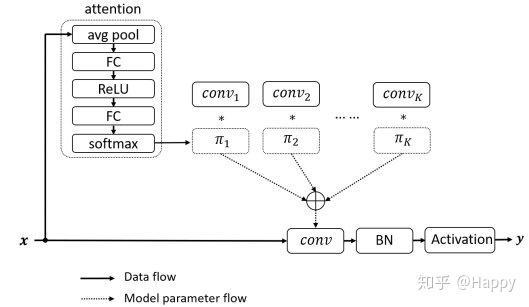

- 注意力:作者采用轻量型的
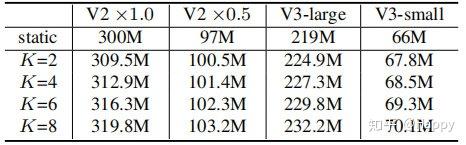
squeeze and excitation提取注意力权值\pi_k(x),见上图。与SENet的不同之处在于:SENet为通道赋予注意力机制,而动态卷积为卷积核赋予注意力机制。 - 核集成:由于核比较小,故而核集成过程是计算高效的。下表给出了动态卷积与静态卷积的计算量对比。从中可以看到:计算量提升非常有限。

- 动态CNN:动态卷积可以轻易的嵌入替换现有网络架构的卷积,比如1x1卷积, 3x3卷积,组卷积以及深度卷积。与此同时,它与其他技术(如SE、ReLU6、Mish等)存在互补关系。
Training Strategy
训练深层动态卷积神经网络极具挑战,因其需要同时优化卷积核与注意力部分。下右图蓝线给出了DY-MobileNetV2的训练与验证误差,可以看到收敛较慢且性能仅为64.8%还不如其静态卷积版本的65.4%。
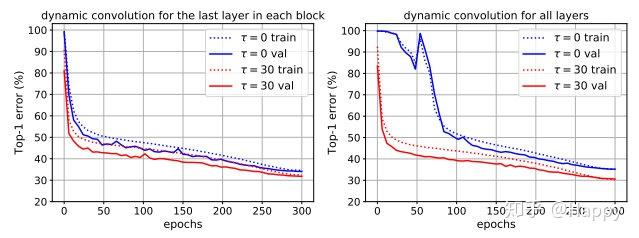

作者认为注意力的稀疏使得仅有部分核得到训练,这使得训练低效。这种低效会随着网络的加深而变得更为严重。为验证该问题,作者在DY-MobileNetV2变种模型(它仅在每个模块的最后1x1卷积替换为动态卷积)上进行了验证,见上左图。可以看到训练收敛更快,精度更高(65.9%)。
为解决上述问题,作者提出采用平滑注意力方式促使更多卷积核同时优化。该平滑过程描述如下:
\pi_k = \frac{exp(z_k/\tau)}{\sum_j exp(z_j/\tau)} \\
从上图可以看到,改进的训练机制可以收敛更快,精度更高。
Experiments
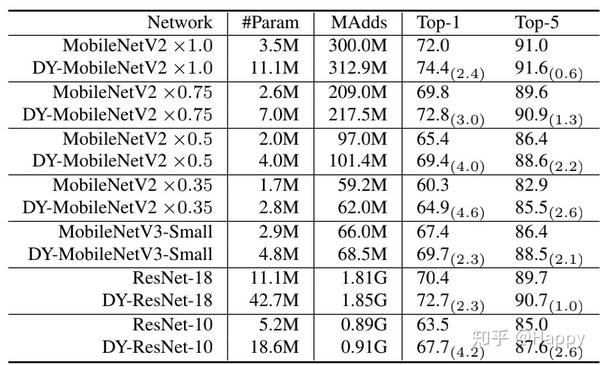
作者在ImageNet数据集上对所提方法的有效性进行了验证。对标模型包含MobileNetV2/V3,ResNet等。动态卷积中的核数目K设置为4,注意力权值归一化因子\tau=30。整体实验对比结果如下所示,可以看到:动态卷积可以一致性得到性能提升,而计算量增加仅为4%。DY-ResNet可以得到2.3%的性能提升,DY-MobileNetV2可以得到2.4%的性能提升,DY-MobileNetV3-small可以得到2.3%的性能提升。

作者对动态卷积的期望属性为:(1)每层的动态卷积具有灵活性;(2)注意力机制 与输入 有关。对于第一个属性(如果不具有灵活性,那么不同的注意力会导致相似的性能,而实际上差异非常大),作者采用了不同的注意力进行验证,性能对比见下表。
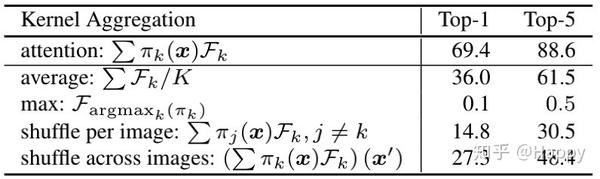

下表给出了注意力是如何跨层影响模型性能的,注:个人感觉这个表不具有说服力,baseline的准确率只有36%,这个是不可能的嘛。
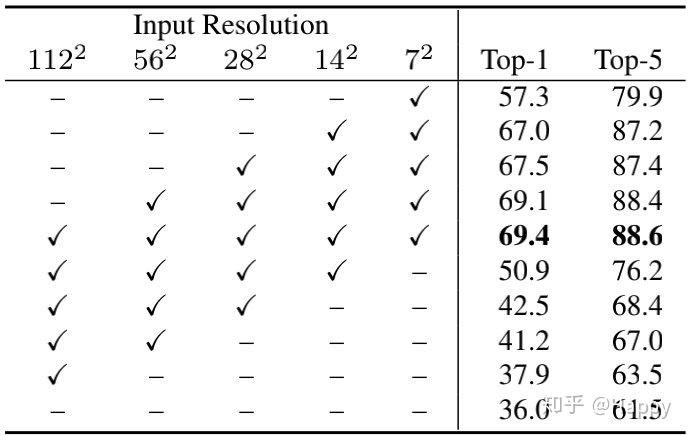

更多的实验结果与数据分析建议查看原文,这里不再进行翻译赘述。
Conclusion
作者引入一种动态卷积,它可以自适应根据输入融合多个卷积核。相比于静态卷积,动态卷积可以明显的提升模型表达能力与性能,这有助于高效CNN架构设计。该动态卷积具有“即插即用”特性,可以轻易嵌入到现有网络架构中。
欢迎关注AIWalker公众号,在这里您将得到独家深度学习经验分享与个人思考。想支持Happy继续写下去就点个赞关注一下吧!

