
情绪支持:Towards Emotional Support Dialog Systems

arXiv:https://arxiv.org/abs/2106.01144
作者:Siyang Liu,Chujie Zheng,Orianna Demasi,Sahand Sabour,Yu Li,Zhou Yu,Yong Jiang,Minlie Huang
Abstract
由于缺乏精心设计的任务和有效的情感支持对话语料库,在对话系统中还没有情绪支持相关的研究。作者提出了一个情绪支持(Emotional Support Conversation,ESC)任务及框架(基于 Helping Skills Theory)。另外文章还提供了一个情绪支持的数据集。
1 Introduction
研究表明,提供情绪支持(ES)并非凭直觉,因此建议使用程序和适当的对话技巧来提供支持,如图 1 所示。为了确定 help-seeker 痛苦的原因,supporter 首先探索 help-seeker 的问题。在了解 help-seeker 的情况后,supporter 可以通过各种技巧(如自我表露 Self-disclosure、表达自我感受 Reflection of Feelings 等)表达理解和同理心,以缓解求助者的挫败感。另外 supporter 如果只能安慰,那么将不能实质的帮助 help-seeker,因此 supporter 需要提出建议,帮助 help-seeker 解决问题。


文章提出了 Emotional Support Conversation (ESC)task,还提供了专用于 ES 的数据集。ESC 框架提出了三个阶段(Exploration,Comforting 和 Action),其中每个阶段包含几个支持策略(或技能)。为了促进情感支持对话的研究,文章构建了一个情感支持对话数据集 ESConv。
2 Emotional Support Conversation
2.1 Task Definition
Help-seeker 的情绪 label: e ,以及程度 l (1-5)。ESC 的子问题如下:
- 支持策略的选择;
- 情绪状态建模,以便于跟踪用户的情绪状态;
- 评估支持的有效性。除了评估对话的相关性、连贯性和用户参与度的传统维度外,ESC 还提出了评估 ES 有效性的新维度。
2.2 ESC Framework
ESC 有三个阶段,如图2所示。

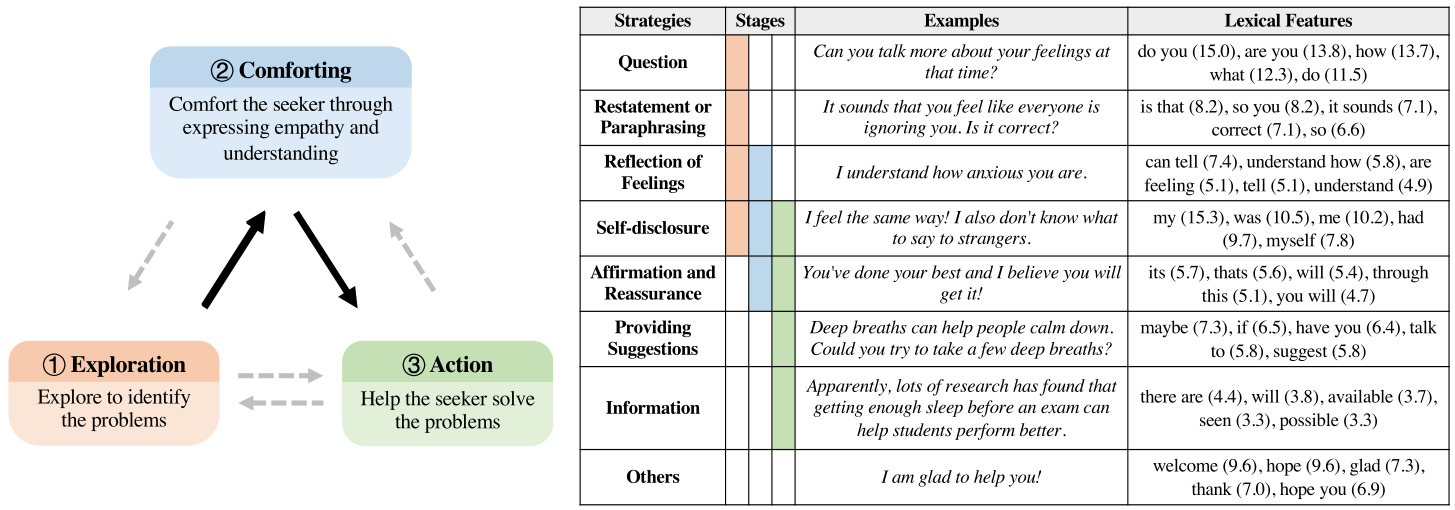
2.2.1 Stages
文章将 ES 分为三个阶段:exploration(探索 help-seeker 的问题),comforting(安慰) 和 action(提供建议解决问题)。这三个阶段并不一定按照顺序执行。
2.2.2 Strategies
文章为每个阶段提供了7种推荐的对话技巧。
3 Data Collection
文章通过大量设计并众包的形式制作了数据集:ESConv。Supporter 主要包括培训如何交流,如何根据策略回复,并且需要在对话之后进行打分。Help-seeker 需要填写调查问卷来指定自己的困境,并且在交流过程中需要对自己的情绪压力是否缓解进行打分,并在结束之后再填写一份调查问卷。
作者还设置了大量的标准来过滤低质量的数据。
4 Data Characteristics
4.1 Statistics
之后总共收集到了1,053 条对话数据,如表1所示。
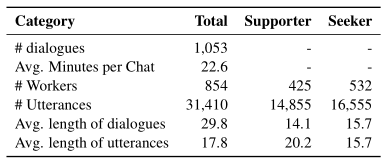
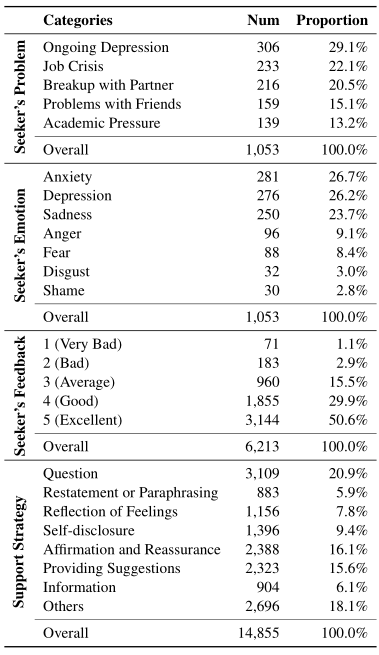
表2中提供了注释的统计数据。
4.2 Strategy Analysis
4.2.1 Lexical Features
通过计算每个策略的 log odds ratio,并使用 informative Dirichlet prior 来提取每个策略的词汇特征。最终结果在图2中列出了每个策略的前 5 个短语。
4.2.2 Strategy Distribution
图3左侧是数据集中的策略分布,右侧是机器人交互时采用的策略的分布,两个分布显示了模型很好的学习到了数据集的策略分析


5 Experiments
实验主要关注两个问题:
- 带有策略注释的 ESConv 可以在多大程度上改进最先进的生成对话模型?
- 这些模型是否能够从 ESConv 学会提供有效的情感支持?
5.1 Backbone Models
使用了两个最先进的预训练模型作为 variant models 的 backbones:
- BlenderBot:这是一个由多种沟通技巧,包括 empathetic responding 训练而成的模型。因此,BlenderBot 能够在一定程度上为用户提供 ES;
- DialoGPT:由 GPT-2 在对话数据集上训练而成的模型。
5.2 Variant Models
以上述每个预训练模型为 Backbone,作者构建了以下 Variant Models:
- Vanilla:Backbone 模型直接在 ESCov 上进行微调,不使用策略注释。 形式上,对话历史是 \mathbf{x} ,目标回复是 y ,模型最大化条件概率: \mathbb{P}(\mathbf{y} \mid \mathbf{x})=\prod_{i=1}^{|\mathbf{y}|} \mathbb{P}\left(y_{i} \mid \mathbf{x}, \mathbf{y}_{\leq i}\right) 。
- Variants with strategy:为了将策略注释合并到 Backbone 模型中,作者使用了一个特殊的 token 来表示每个策略。Supporters 的每次回复 y ,都会在前附加相应的策略 token: \tilde{\mathbf{y}}=[\mathrm{st}] \oplus \mathbf{y} 。然后,将 x 作为输入,模型生成以第一个预测(或指定)策略 token 为条件的回复: \mathbb{P}(\tilde{\mathbf{y}} \mid \mathbf{x})=\mathbb{P}([\mathrm{st}] \mid \mathbf{x}) \prod_{i=1}^{|\mathbf{y}|} \mathbb{P}\left(y_{i} \mid \mathbf{x},[\mathrm{st}], \mathbf{y}_{<i}\right)
在后面的实验中研究了三种使用策略注释的 variants。
- Oracle:根据gold reference strategy tokens 生成回复;
- Joint:根据预测(采样)的策略标记生成回复;
- Random:根据随机选择的策略生成回复。
5.3 Automatic Evaluation
为了研究使用支持策略对以 BlenderBot 或 DialoGPT 作为 Backbone 的模型性能的影响,文章比较了上述 Vanilla、Joint 和 Oracle 的性能。评价标准 automatic metrics 包括 perplexity (PPL)、BLEU-2、ROUGE-L 和 BOW Embedding-based Extrema matching score。
5.4 Human Interactive Evaluation
参与者随机与训练的模型与其余对话机器人对话后来评价模型效果。
