Transformer统治的时代,LSTM模型并没有被代替,LSTM比Tranformer优势在哪里?

不认为LSTM除了比Transformer轻量以外有任何的优势。
最近打算写一个efficient transformer的系列文章,会系统汇总当前主流的efficient transformers,他们的底层逻辑以及优缺点。感兴趣的同学可以关注一下这个账号follow一下。
下面强行插入我的专栏文章,有兴趣的读一下哈哈(逃
若你想每天学一点新理论,可以关注一下本账号,以方便读到之后的文章。
Cheers~
近年来transformer在深度学习领域掀起了一股腥风血雨。作为一个NLP模型,它在NLP的各个子任务比如NER,POS,机器翻译,对话系统,语音识别等几乎所有任务上获得了不俗的效果。其它领域比如CV,推荐系统,生物,交通等也衍生出了很多transformer的变种来解决各自的问题。尽管有不少论文质疑transformer的有效性和必要性(后续文章会讨论),但它在各大榜单的不俗表现也是事实。本系列旨在从多个角度去思考与归纳Transformer及其最前沿各大变种的技术细节,有效性与必要性,以及与其它方法的联系,从而带给读者一些启发。
本文将带领读者从一个不同于教科书的叙述方式来思考一些transformer的本质与细节。即使你从来没有了解过transformer,本文的介绍方式也会引导你更快地入门transformer。本文不长,建议细读。
希望读完这篇文章之后,它能帮助你理解transformer背后的思想和逻辑。我们的知识是由少到多的,每一个这样关键的知识点或理解都能帮你扫清未来面试或做实验时的障碍,让你的研究之路一帆风顺!
一般来说,Transformer 用于解决序列或集合的建模任务。其关键的部分有两个,一个是multi-head self-attention,让词的representation中有侧重点地包含了其它词汇的信息。还有一个是encoder-decoder attention,和在RNN中引入attention 思想一样,这种模型不单单是简单地凭借前一个或者前几个词的信息来sequential地解出下一个词汇,而且它在解下一个词汇的同时会有focus地与源语言进行对比,看看当前词汇的生成更依赖源语言中哪些词汇(attention),这样十分符合人类在翻译时的习惯。
1. Self-attention
一句话概括self-attention:用句子中所有单词向量的加权和来代表某一个单词的向量。
回顾一下如何在machine-translation的encoder-decoder RNN中引入attention机制:
Machine-translation 中基于RNN的encoder-decoder模型(无attention)利用了RNN能够传递前后隐层信息的特性,在encoder中输入sentence的所有信息都被压缩到了最后一个隐层中,然后再通过decoder基于这个隐层的输出向量进行解码。Decoder中每一个state的输入是上一个state生成的单词,并且能接收上一个隐层的信息,所以它能够一个一个地解码隐层。但是这种方式仅用一个向量来表示所有encoded tokens,显然表达能力是受限的。
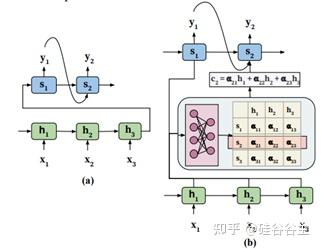
并入attention机制的作用,简单概括来说,就是decoder的某一个state在解码的时候,能够把之前encode的每一个state vector也能直接考虑进来,并且是有倾向性的考虑(这样网络能够知道哪一个/几个单词所对应的状态对你当前要生成的单词比较重要),如上图所示。
回到self-attention,和上述的attention机制一样,唯一的不同在于它attention的target是当前这个单词,而source是当前句子里面的其它所有单词,而不是其它的句子里的单词。
它是如何运算的呢?首先,对于输入的每一个单词都生成三个vector,分别是query,key和value。这三个vector如何生成?将embedding层输出的向量分别输入三个神经网络,三个神经网络输出的向量就是query,key和value. 这三个神经网络是随着其它部分一起端到端训练的。
attention的具体运算的过程是这样的:
总览:针对句子中的某一个单词W,计算其余单词以及它自身所对应的权重,由此可以知道这个句子当中每一个单词对目标单词的重要性。最后将这些单词按照权重的softmax加权相加,代表原来的目标单词W的向量。
对句子中某一个单词,计算他的权重的过程是这样的:
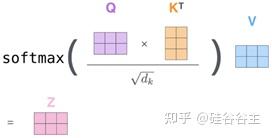
首先,用这个单词的query向量和句子中其余单词的key向量挨个相乘,对应每一个单词都得到一个值,这就是初始的权值。
然后,用用这个权值除以根号下key向量的长度,即将这个权值放缩,按照“Attention is all you need”的说法,softmax里面的值太大会导致梯度为零。
接下来就是将放缩以后的权值用softmax归一化,这样各个word所对应的权值加起来等于一。
最后将各个word的value向量按照权重进行加权求和,来代表这个单词本身的词向量。(可以看出,这里的value从某种意义上代表了原单词的embedding向量。)
如果针对N个词所组成的batch,完全可以像下图所示,使用矩阵来进行同时操作,这样还能进行并行计算。其中 d_{k} 是key vector的dimension。
2. Multi-head Attention
多个‘head’的self-attention。具体流程见下图:
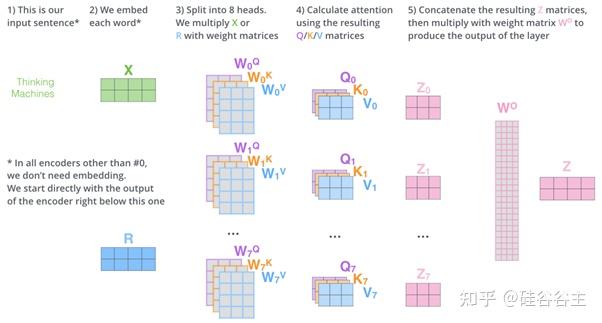

可以看到,模型initialize了多个Q,K,V组合,也由此给每一个单词多种不同的self-attention结果( Z_{0},Z_{1},Z_{2},…,Z_{7} 中的每一个都是一个句子中所有单词对应的self-attention结果组成的batch,对应一个句子),意在让单词focus一个句子的不同position。将这些Z并联拼接, 最后用一个神经网络来将它们映射到和输入一样的形状。这样的一个multi-head的结构可以增强模型的拟合能力和对不同任务的适应能力。
3. Positional Encoding
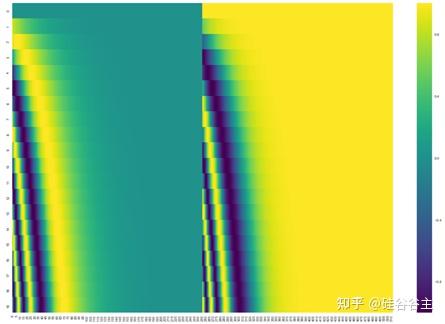
因为transformer不是sequential的model,在实现了并行计算的同时丢失了位置信息,所以这个位置信息要用positional encoding来实现。
即在单词embedding的vector上加上一个position vector,这样embedding vector就有了单词的位置信息。
可以参照下面对应20个单词的position vector来加深对position vector的理解。

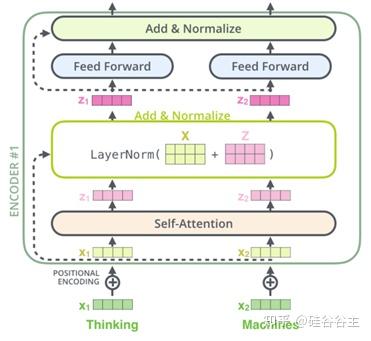
4. Transformer中的残差和normalization结构
Transformer中采用后置的add & norm来实现如下图所示的残差与normalization结构。注意原文中是layer normalization而不是batch normalization。
5. Transformer Decoder
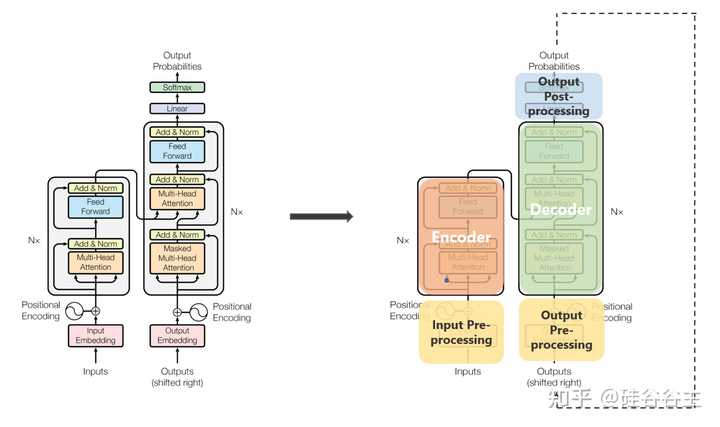

Decoder也由若干个layers 堆砌而成。上层的layer接受下层的layer的输出作为输入,这和encoder是一样的。
Decoder每一层的结构和encoder也很类似,只不过在最下面的multi-head self-attention是经过masked(之后讨论),并且多了上面那一层“encoder-decoder multi-head attention”。“masked multi-head self-attention”生成decoder 输入每一个word对应的representation作为query,这个query在“encoder-decoder multi-head attention”中与encoder输出的Keys和Values做运算,就能知道哪些源语言的hidden state对当前词比较重要,然后输出原来sentence一个新的representation。
Decoder根据encoder给的Values和Keys先decode出第一个单词。接着将这第一个单词作为最下面masked multi-head attention的输入,经过positional-encoding,加上self-attention,输出原来sentence的一个self-attention representation,与Values和Keys一起输入中间的“encoder-decoder multi-head attention” layer,然后decode出第三个单词 ... 直到遇到结束符号[EOS]。
需要注意的是,在训练的时候,为了parallel的训练,decoder的输入是整句句子。因此在训练的时候需要使用一个mask来把整个句子中属于当前词之后 的词汇屏蔽掉。实际做法是在self-attention之前把future positions的Q*K都换成极小的数,即让当前的词不要关注未来的词(具体看下一节)。这样在做self-attention的时候就不会把未来的词也考虑进去了(否则就是你已经知道了下一个词的信息的情况下去预测下一个词,就属于cheating prediction)。而evaluate的时候则是生成几个就输入几个。
6. 对transformer进行一下宏观的总结
Transformer对语言的一些特征如sequential,syntax等等都没有预先的inductive bias,因为它的attention是全连接的结构。通常它适用于大的数据集。
Encoder和decoder拥有几乎一样的结构;他们的区别在于decoder在self-attention以后多了一层encoder-decoder attention layer。因此,
encoder的结构:(self-attention, add-norm); (linear layer2048, linear layer512, add-norm); (softmax: optional)
decoder的结构:(self-attention, add-norm); (encoder-decoder attention, add-norm); (linear layer2048, linear layer512, add-norm); (softmax: optional)
由于encoder,decoder中间的每一层都不会改变input的形状,因此encoder和decoder的input和output的形状都是(S, N, D),如果是batch_first,那么形状就是(N, S, D)。即训练时他们的输入输出都是一个batch的sequence,inference时输入输出都是单个sequence。
现在我们不考虑batch, 对其计算过程进行分析。Encoder的输入是source sentence,输出是memory sentence,长度为S,形状相同为(S, D);decoder的输入是target sentence, 输出是output sentence,长度为S,形状相同为(S, D)。其中decoder中self-attention的输出sequence长度为S,这个sequence与memory sentence计算encoder-decoder attention,计算方法就是用这个sequence计算Q,形状为(S, D), 用memory sentence计算K和V,然后用计算self-attention的方式去计算这个attention(本质原理是对于decoder self-attention的输出vector sequence中每一个vector,分别计算它和memory sentence中每一个vector的attention weight,然后加权和,得到一个新的vector,形状为(D, 1),从而得到一个新的vector sequence, 形状为(S, D))。
由于训练时decoder的输入是一个sentence (这里是teaching force的训练,现在不考虑batch),输出希望预测的也是一模一样的sentence,因此这其实是不符合原理的,因为sequence的预测做的是根据当前已预测出来的sequence来预测下一个词,所以不能把future information给考虑进来。
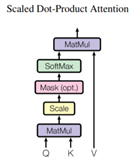
上图在计算multi-head self-attention的时候把Q*K^T得到的方阵让这个方阵与一个mask相加:
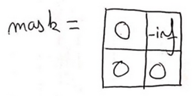
这样经过softmax计算以后 Q*K^T 对应位置的值就是0:
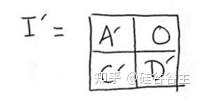
这意味着什么呢?我们考虑self-attention会输出S个vector,这S个vector每一个都会与memory计算一个attention来更新自己,然后继续向前传递;因此这里每一个vector就对应了output sentence中的一个vector,即对应一个词,S个词的vector就与output中S个词的prediction一一对应,只不过这里是同步进行的,而RNN中是异步进行的。也就是说我们不想让self-attention输出的sequence中的某个vector包含未来的信息,因此具体就体现于在计算self-attention的时候加上述的mask,Q*K^T中每一行对应self-attention输出的sequence中的一个vector,即对应output sentence中 某一个单词的prediction,那把右边的位置设为0意思就是在加权的时候V里面对应位置的vector我就不考虑了,也就是未来的词我把它忽视掉,这样经过softmax后,上图中A’位置的值近似为1。那对于output sentence中第二个单词的prediction,因为可以参考的单词+1, 因此计算加权的时候我也就多考虑一项。这里需要注意的是decoder的输入是shifted right。如果第一个token已知,想要预测下一个token(比如language model),那么起始token就是这个已知token;若起始token未知,则第一个token应该是[sos] (开始符号),因此有一个位置的偏移量,输入[sos]时预测第一个token,输入[sos]和第一个token时预测第二个token,以此类推。不论如何,第一个token都不会出现在output端的target sentence中。
7. A Few More Words
本文针对基于attention的模型 - transformer梳理了一些我认为关键的知识点,并将之与其它熟知的方法或模型进行对比,以提供一些不一样的思考。本文只是这个transformer系列文章最基础的一篇,后续本专栏会更新更多对于transformer及其变种的汇总和思考。
希望读完这篇文章之后,它能帮助你理解transformer背后的思想和逻辑。我们的知识是由少到多的,每一个这样关键的知识点或理解都能帮你扫清未来面试或做实验时的障碍,让你的研究之路一帆风顺!
你的功力又增强了!:-D
如果你觉得本文对你有所启发,欢迎左下角点赞,你们的分享与支持是我不断输出的动力(full-time Ph.D.,搬砖不易!)。我会不定期update一些新的思考与前沿技术,我update的内容一定也是对我自己的research有所启发的。若你想跟我一起进步,可以关注一下本账号,以方便读到之后的文章。
Peace
推荐阅读:
硅谷谷主:一文掌握Byte Pair Encoding(BPE) — NLP最重要的编码方式之一0 赞同 · 0 评论文章
硅谷谷主:一文理解强化学习中policy-gradient 和Q-learning的区别8 赞同 · 0 评论文章
一文搞懂Language Modeling三大评估标准23 赞同 · 2 评论文章
硅谷谷主:为什么训练的时候warm up这么重要?一文理解warm up原理1 赞同 · 0 评论文章
作者:硅谷谷主
参考内容:
1. Vaswani, Ashish, et al. "Attention is all you need."Advances in neural information processing systems. 2017.
2. Tay, Yi, et al. "Efficient transformers: A survey."arXiv preprint arXiv:2009.06732(2020).
3. The Illustrated Transformer