


LoFGAN: Fusing Local Representations for Few-shot Image Generation
Code Link:https://github.com/edward3862/LoFGAN-pytorch
介绍一篇南京大学李文斌老师课题组发表于ICCV2021的小样本图像生成文章,以局部特征融合的方式提升小样本场景下的生成图片质量,并且将生成图片作为增广数据,辅助于分类任务。
Background
现有的小样本图像生成定义其实不是很明确,小样本场景下的图像生成有文章用Few-shot Image Generation,也有文章用Training GANs under Limited Data,严格意义来说,本文的小样本图像生成是与小样本分类问题中的小样本问题定义是一样的,在Base Class(Seen Class)上面训练一个模型,然后让模型在每类有限的Support Set上学习一定的泛化能力,在Inference的阶段,Novel Class(Unseen Class)提供少量的测试样本。不同点在于分类问题是提供query samples做分类,而生成模型是用提供的少量图片用于生成同类但尽可能多样且真实的图片。
而另外一种数据有限场景下的小样本图像生成,通常直接指的就是一些领域或者一些图像数据,就只有很少的数量,私认为这个场景更应该被定义为数据及其有限场景下的图像生成。(近期我也会将二者的异同和相关的方法进行梳理后发布,敬请关注~)
Problem Definition
本文的方法属于第一种,跟小样本分类同源的小样本图像生成,问题定义为:
将给定数据集分为两部分:Seen Classes C_s 和Unseen Class C_u ,且 C_s\mathop{\cap}C_u=\emptyset 。在训练过程中,从 C_s 中采样多次训练任务,每个任务中包含Batchsize*K个样本,K为每一类的样本数,因此每次任务也就叫做K-shots Generation,在任务之间训练模型,希望模型能够学习到可迁移的生成能力;在测试阶段,从 C_u 中采样K张图片生成同类但足够真实和多样的图片。
Motivation
本文的动机其实比较直观,现有的小样本图像生成方法中,基于融合的方法取得了一定的成功,但是现有方法的融合是基于原始图片的线性插值融合,根据相似度对整张图片进行融合,这样会导致两个问题:
- 输入图片的语义属性可能是不对齐的,而全局的对输入图片进行插值,可能会导致生成图片存在伪影(aliasing artifacts);
- 由于输入图片语义区域的相对位置是固定的,简单的在图片层面处理会损失生成图片的多样性;
基于上述的观察,LoFGAN提出,在特征层面对图像特征进行局部融合,同时为了更好的保证图片的重构特征和生成真实性,记录下局部融合的区域并添加了局部重构损失,相较于全局的重构损失直接对齐pixel之间的关系,局部重构损失能够进一步提升生成样本的质量。
Related Work
- Generative Adversarial Networks:引出GAN以及近年来的进步与应用,但主要是为了引出小样本生成;
- Few-shot Generative Adaptation:这里讨论的跟上面讨论的问题比较类似,有部分文章探讨了GAN里面的预训练模型并将其迁移适配到小样本场景,这样的方法更适合被称为Few-shot Generative Adaptation,而不是小样本图像生成;
- Few-shot Image Generation:介绍与本文相关的对应小样本图像分类的小样本图像生成方法,包括Matching GAN,F2GAN,DAWSON,FIGR,GMN(不过居然没有介绍DAGAN)。
Method
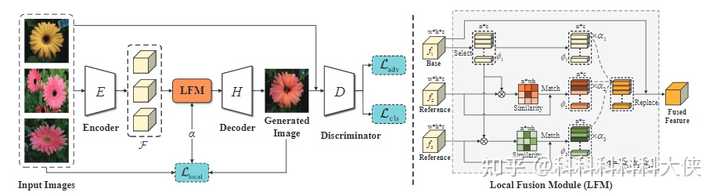

方法的整体框架如上图所示,方法核心是图中右半部分的局部融合模块,整个生成模型包括一个Encoder、一个Decoder以及一个Discriminator,Encoder将输入图片提取为特征表示,然后经过局部融合模块,得到新的特征表示,输入到Decoder后得到生成图片,交由判别器进行判别。
- Local Fusion Module
局部融合模块由上右图所示,整体思路就是首先在K张图片中随机选择一张作为Base,然后其他的所有图片作为Reference,将Base的局部特征通过(K-1)张图片的局部特征进行融合,得到新的融合后的特征,然后输入到解码器。包含三个阶段:
(1)Local Selection:与现有的方法的不同点在于,这里的局部选择随机的确定特征的某一块,由参数η确定;
(2)Local Mathing:在确定选择的是哪一部分局部特征后,计算Reference图片特征对应位置与Base图片的相似度:
\begin{equation} M^{(i, j)}=g\left(\phi_{\text {base }}^{(i)}, f_{\text {ref }}^{(j)}\right) \end{equation}
得到一个相似度map,然后就可以找到与Base图片最相似的局部特征进行融合。
(3)Local Replacement:对选定的局部特征,我们此时有k-1个候选可用于替换的局部特征,那就可以将所有局部表示进行融合,并且将base特征中原始的部分替换掉:
\begin{equation} \phi_{\text {fuse }}^{(t)}=\alpha_{\text {base }} \cdot \phi_{\text {base }}^{(t)}+\sum_{i=1, \ldots, k, i \neq \text { base }} \alpha_{i} \cdot \phi_{\text {ref }}^{(i)}(t) \end{equation}
(4)Local Reconstruction Loss:这里的局部重构就是将上述特征层面的局部融合在图像层面实现,具体来说,记录下了替换的base图片的特征位置,然后将各个位置还原映射到图片大小,这样就得到了对应位置的经过局部融合后的图片,对这一位置进行局部重构:
\begin{equation} \mathcal{L}_{\text {local }}=\|\hat{x}-\operatorname{LFM}(X, \boldsymbol{\alpha})\|_{1} \end{equation}
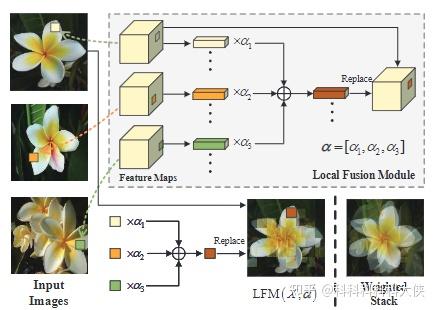

由上图也可以看出,特征图中的每一个位置其实也对应着原始图片,选择替换的特征快对应着就是图片的不同patch。
- Objective Function
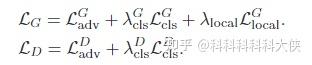
G包含了对抗损失、辅助分类损失和局部重构损失;
D包含了对抗损失、辅助分类损失。
Experiments
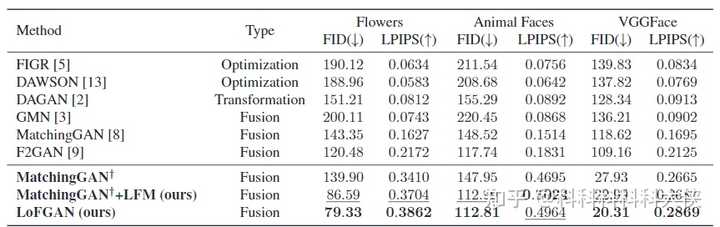
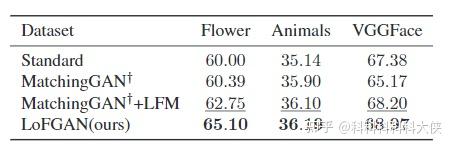
- 定量分析:对FID、LPIPS的指标进行比较,可以看出在每个数据集上本方法都有显著的提升。

- 定性分析:从可视化结果对生成多样性和真实性进行分析,与MatchingGAN相比,LoFGAN在多样性方面表现更好,且相对来说,伪影更少出现。


- 学习相似度的可视化:这里就是用于说明模型是否正确的学习到了不同图片的语义相似度,举例来说,蓝色的部分对于话来说相似度高的应该是花瓣,对于过来说应该是毛发,对于人脸来说应该是鼻子,可以从图中看出,对应位置的位置都有更高的相似度,说明了模型学习到了不同图片的语义相似度,这样对特征局部语义进行融合也是合理的。

- 局部选择特征大小 η的影响:其实就是对特征层面选择多少进行融合替换对生成结果的影响,如果是全部替换,那就变成了一张不同的图片


- Augment for Classification:将生成的图片用于数据扩充,对应类别的数据生成固定张数后用于分类,可以看出小样本图像生成的图片用于扩充数据辅助下流分类任务是可行的,且本文所方法具有更大的促进作用,也进一步说明了所提方法生成图片的质量较高

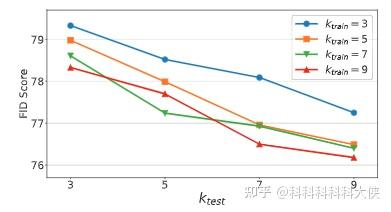
- 不同的K的影响,即每类图片不同张数对结果的影响,越多越好
Conclusion
这篇文章是个人在第一类小样本图像生成方法中最喜欢的一篇文章,写的很清晰,实验做的也比较详细,并且方法动机都很具有insight,同时性能也提升很大,当然,还有最重要的一点就是,不像MatchingGAN系列的文章,代码非常乱结果也复现不出来。我自己跑了的结果跟文章相当,且论文与代码细节一一对应。另外就是类似于元训练用于小样本图像生成这类的文章其实没有数据有限场景下的样本生成涌现那么多文章,但辅助于下流任务分类也很有意义。也是针对小样本问题且做不动超大规模生成模型训练的一个好方向。