时间序列数据分析101 - (7) 自相关模型autoregressive model

大纲
1.概述
2.准备和处理时间序列数据
3.探索式分析(EDA)
4.基于统计学的时间序列分析方法
4.1 自回归模型
5.基于状态空间模型的时间序列分析方法
6.基于机器学习的时间序列分析方法
7.基于深度学习的时间序列分析方法
8.模型优化的考虑
所有源代码和markdown在github同步更新
https://github.com/skywateryang
4. 基于统计学的时间序列分析方法
本章将正式开始时间序列分析方法的内容,我们会先从统计学方法开始讲起,这类方法最为传统,在学术研究和工业模型等领域都已经有了十分广泛的应用。这类方法和线性回归有一定类似,会用到线性回归来解释不同时间下数据点之间的关系。和一般线性回归的区别是一般线性回归分析假定不同数据点之间是独立的,而时间序列数据分析的一个重要前提是各个数据点之间存在关联。
4.1 自回归模型(Autoregressive)
自回归模型基于的基础是可以用历史预测未来,也就是时刻t的数据能用之前时刻的函数来表示。
自回归模型是很多人在拟合时间序列数据时最先尝试的模型,尤其是在对该数据没有额外的了解时。它的基本公式可以用以下公式表示, y_t = b_0 + b_1 * y_{t -1} + e_t
这个最简单的模型称为AR(1),其中括号中的1表示时间间隔为1,也就是当前时刻的数据值的计算只考虑到前一个时刻的值。从公式可以看出,它和常规的线性回归十分类似, b_0,b_1 分别代表截距项和回归系数, e_t 表示t时刻的错误项,其中错误项均值为0,具有固定方差。这个公式表示的是用t-1时刻的时间序列值来拟合t时刻的时间序列值。
AR模型可以扩展到p个近邻时间值,此时称为AR(p)。 y_t = \phi_0 + \phi_1 * y_{t -1} + \phi_2 * y_{t -2} + ... + \phi_p * y_{t - p} + e_t 其中 \phi 表示一系列回归系数。
python实战演练
在实战中我们应当注意使用AR模型的两个前提假定:
- 过去发生的数据能够用来预测未来的数据(也就是数据之间是非独立的)
- 时间序列数据时平稳的
如果数据集是不平稳的,需要使用一些操作将数据去除趋势项和季节项使其变得平稳。
冷知识:平稳性非为强平稳性和弱平稳性,其中强平稳性要求数据的分布不随时间变化,而弱平稳性仅仅要求数据的一阶距和二阶矩(均值和方差)不随时间变化。
import matplotlib.pyplot as plt
import pandas as pd
from statsmodels.tsa.ar_model import AutoReg
from statsmodels.tsa.seasonal import seasonal_decompose
%matplotlib inline
# 导入销售数据,绘制原始图像
sales_data = pd.read_csv('data/retail_sales.csv')
sales_data['date']=pd.to_datetime(sales_data['date'])
sales_data.set_index('date', inplace=True)
sales_data.plot()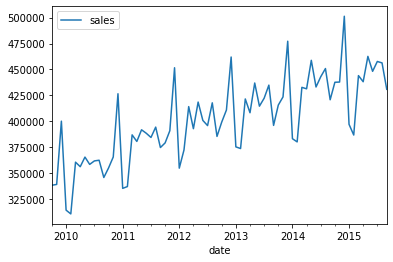
我们提到使用AR模型的两个前提假设,相关性和平稳性。 因此先来检验相关性。
检验相关性有两种方法 - pandas提供了autocorrelation_plot方法用于检验整体自相关性 - 使用pandas的lag_plot方法检查单个时间间隔的相关性
pd.plotting.autocorrelation_plot(sales_data['sales'])
# 从自相关性图中可以看到在lag<=12时,acf值在临界点以外,表现出极强的相关性。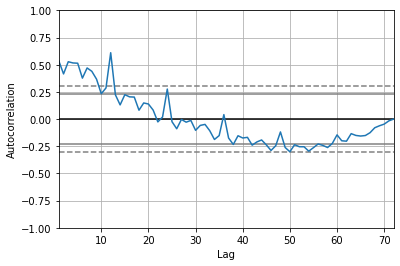
# 将上图中相关性最强的lag=12单独画散点图,观察相关性
pd.plotting.lag_plot(sales_data['sales'],lag=12)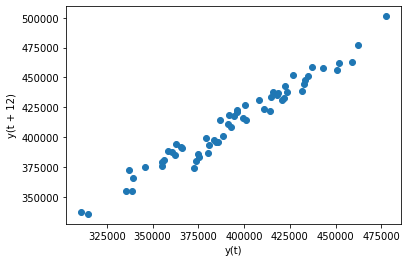
第二步检查平稳性,一个最快捷的方法之一是使用statsmodels中的seasonal_decompose方法进行趋势项和季节项的分解。
# 数据集存在明显趋势项(图二单调递增)和季节项(图三周期性变化)
decomposed = seasonal_decompose(sales_data['sales'], model='additive')
x = decomposed.plot()

幸好statsmodel包的AutoReg方法增加了对趋势和季节项特征的处理,直接使用该方法即可
# 划分训练集合测试集
X = sales_data['sales']
train_data = X[1:len(X)-12]
test_data = X[len(X)-12:] #以最后十二个点作为待预测值
# 训练AR模型
model = AutoReg(train_data,lags=15,missing='drop',trend='t',seasonal=True)
model_fitted = model.fit()
# 查看模型结果
model_fitted.summary()| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| trend | 839.9681 | 362.378 | 2.318 | 0.020 | 129.721 | 1550.216 |
| seasonal.0 | 2.213e+05 | 8.34e+04 | 2.653 | 0.008 | 5.78e+04 | 3.85e+05 |
| seasonal.1 | 2.808e+05 | 8.08e+04 | 3.476 | 0.001 | 1.22e+05 | 4.39e+05 |
| seasonal.2 | 1.924e+05 | 8.7e+04 | 2.212 | 0.027 | 2.19e+04 | 3.63e+05 |
| seasonal.3 | 1.689e+05 | 8.69e+04 | 1.945 | 0.052 | -1331.228 | 3.39e+05 |
| seasonal.4 | 2.263e+05 | 8.29e+04 | 2.728 | 0.006 | 6.37e+04 | 3.89e+05 |
| seasonal.5 | 2.335e+05 | 7.98e+04 | 2.926 | 0.003 | 7.71e+04 | 3.9e+05 |
| seasonal.6 | 2.09e+05 | 8.26e+04 | 2.530 | 0.011 | 4.71e+04 | 3.71e+05 |
| seasonal.7 | 2.318e+05 | 8.32e+04 | 2.785 | 0.005 | 6.87e+04 | 3.95e+05 |
| seasonal.8 | 2.33e+05 | 8.41e+04 | 2.771 | 0.006 | 6.82e+04 | 3.98e+05 |
| seasonal.9 | 2.224e+05 | 8.4e+04 | 2.648 | 0.008 | 5.78e+04 | 3.87e+05 |
| seasonal.10 | 1.901e+05 | 8.46e+04 | 2.246 | 0.025 | 2.42e+04 | 3.56e+05 |
| seasonal.11 | 2.123e+05 | 8.59e+04 | 2.473 | 0.013 | 4.4e+04 | 3.81e+05 |
| sales.L1 | 0.2604 | 0.155 | 1.685 | 0.092 | -0.042 | 0.563 |
| sales.L2 | 0.1237 | 0.158 | 0.785 | 0.433 | -0.185 | 0.433 |
| sales.L3 | 0.0379 | 0.150 | 0.252 | 0.801 | -0.256 | 0.332 |
| sales.L4 | -0.2515 | 0.149 | -1.691 | 0.091 | -0.543 | 0.040 |
| sales.L5 | 0.2431 | 0.163 | 1.496 | 0.135 | -0.075 | 0.562 |
| sales.L6 | -0.1179 | 0.163 | -0.722 | 0.470 | -0.438 | 0.202 |
| sales.L7 | -0.1311 | 0.164 | -0.799 | 0.424 | -0.453 | 0.190 |
| sales.L8 | -0.0212 | 0.196 | -0.108 | 0.914 | -0.406 | 0.363 |
| sales.L9 | 0.2763 | 0.201 | 1.374 | 0.169 | -0.118 | 0.670 |
| sales.L10 | 0.0443 | 0.200 | 0.222 | 0.825 | -0.347 | 0.436 |
| sales.L11 | 0.1980 | 0.203 | 0.975 | 0.330 | -0.200 | 0.596 |
| sales.L12 | 0.1034 | 0.202 | 0.512 | 0.609 | -0.292 | 0.499 |
| sales.L13 | -0.4173 | 0.206 | -2.029 | 0.042 | -0.820 | -0.014 |
| sales.L14 | 0.0320 | 0.192 | 0.166 | 0.868 | -0.345 | 0.409 |
| sales.L15 | 0.0085 | 0.206 | 0.041 | 0.967 | -0.396 | 0.413 |
# 预测测试集
predictions = model_fitted.predict(
start=len(train_data),
end=len(train_data) + len(test_data)-1,
dynamic=False) # dynamic参数表示是否用预测值动态预测下一个时刻的值
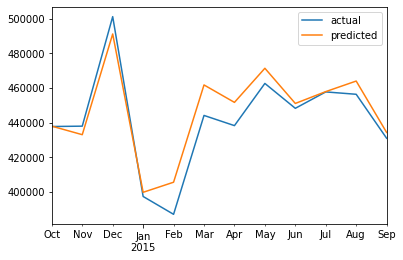
# 比较真实值和预测值
compare_df = pd.concat(
[sales_data['sales'].tail(12),
predictions], axis=1).rename(
columns={'sales': 'actual', 0:'predicted'})
compare_df.plot()