community detection社区检测(二)embedding-based methods

嵌入式的方法是社区检测算法里最常见的一类了,这种方法为每个样本学习一个低维向量表示,然后可以对这些低维向量表示应用传统聚类算法划分聚类。因此这种方法的关键在于怎样为样本学得一个紧凑得表示,同时又要保留其图上得拓扑结构信息(和节点信息)。现在常用的模型有GAN,VAE等。
所以专门分享自己看到的几篇觉得还不错的这方面的文章。
先简单介绍一下,
第一篇是把对抗自编码器引入了图自编码器和图变分自编码器中,为样本生成一个更好的向量表示。
第二篇指出针对嵌入式方法+传统聚类这样两阶段式的方法缺乏目标导向型,因为提出了通过对低维向量表示z划分聚类生成软标签以指导学习向量表示的过程;同时设计了一个利用图结构和属性信息两方面设计attention权重的方法。
第三篇式针对高阶的社区发现问题,设计了一种新的结构motif,在其上构造新的邻接矩阵。
感觉这几篇论文各有侧重点,也算是这几年比较有代表性的工作了。
先介绍下前两篇文章的共同点把,方便大家比较。
这两篇都是基于自编码器AE做手脚。
AE的结构很简单,就是编码器+解码器,根据编码器为样本学到一个低维向量表示,然后利用解码器重构样本的某种信息以确保学到的向量表示确实是对应于该样本的。
那么在社区发现这个问题种,我们也是通过编码器为图上的节点学到一个向量表示z,然后在解码器部分,一般通过向量内积重构邻接矩阵A。
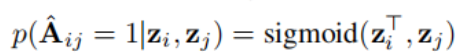

接下来看看这两篇文章在此基础上做了什么改进……
IJCAI18-Adversarially Regularized Graph Autoencoder for Graph Embedding
motivation
大多数现有的嵌入算法通常专注于保留拓扑结构或最大程度地减少图形数据的重构误差,但它们大多忽略了嵌入空间z的数据分布,这通常导致在实际图形数据中的嵌入效果较差。
Makhzani等人在17年的Adversarial autoencoders这篇文章中指出在实践中,无正则化的嵌入方法通常只会学习一种简单的身份映射,其中嵌入空间没有任何结构。在处理现实世界中稀疏和嘈杂的图形数据时,很容易导致表现不佳。处理此问题的一种常用方法是对嵌入空间引入一些正则化,并强制它们遵循某些数据分布。
受Makhzani的工作的启发,文章提出了一种新颖的图数据对抗图嵌入框架。该框架将图形中的拓扑结构和节点内容编码为紧凑的表示形式,在其上训练解码器以重构图形结构。此外,通过对抗训练方案来强制潜在表示以匹配先验分布。为了学习鲁棒的嵌入,开发了对抗方法的两种变体,即对抗正则化图自动编码器(ARGA)和对抗正则化变图自动编码器(ARVGA)。
上面的描述可能还是有些抽象,下面我会尽可能简单的解释这篇文章的思想和主要的工作原理。
这篇文章可以看作是图上的变分自编码器GVAE(GVAE就是VAE在图上的简单扩展)和对抗自编码器AAE的结合。因此首先要理解VAE和AAE。
首先对于VAE,如果对这方面不太了解建议先学习一下VAE。
推荐下大佬的文章,感觉对VAE和VGAE的原理写的很清晰。
简单来说,VAE是想通过编码器学习样本的低维向量表示的分布,是样本的低维向量表示(这样子通过对这个分布采样就可以生成与原样本不同的样本)。但是如果是对所有样本学习一个分布,则无法保证采样得到低维向量z与原样本x的对应关系,因此要为每一个样本学习一个分布。通常强迫这个分布逼近正态分布(方差为1,避免学到的分布直接完全学习原样本)。图变分自编码器GVAE正是VAE在图数据上的变体,编码器部分都一样,关键是解码器部分要重构邻接矩阵:
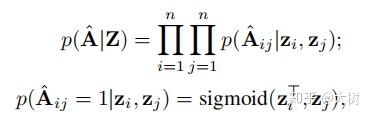
因此VAE的损失函数为
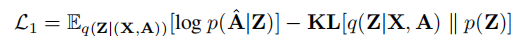

AAE的思想是利用GAN让低维向量表示的分布尽可能和我们预先设定的分布相同,这样我们就可以直接利用这个先验分布采样通过解码器生成真实样本。
感觉这篇文章就是结合这两点,以此可以生成更鲁棒的低维向量表示。
方法
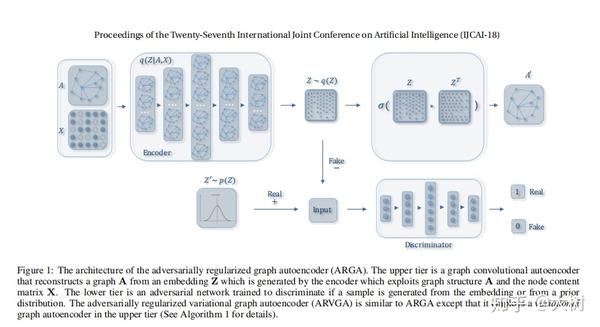

如图,文章整体也是一般自编码器结构,不同的是,为嵌入表示z还引入了一个对抗正则化模块。
Graph Convolutional Autoencoder
Encoder
Graph Encoder
使用GCN堆叠构成encoder
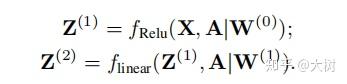
Variational Graph Encoder
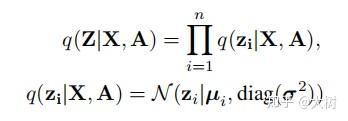
其中 \mu=Z^{(2)} 是矩阵向量 z_{i} 构成的矩阵.
Decoder
根据学到的表示z重构邻接矩阵
对于graph encoder,损失函数如下
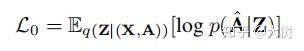
对于variational graph encoder,损失函数如下
假设Z服从高斯分布。
Adversarial Regularization
该模型的关键思想就是通过对抗训练模型强制潜在表示Z匹配先验分布。
损失函数如下:
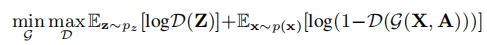

最后整体的算法流程如下图所示:


实验
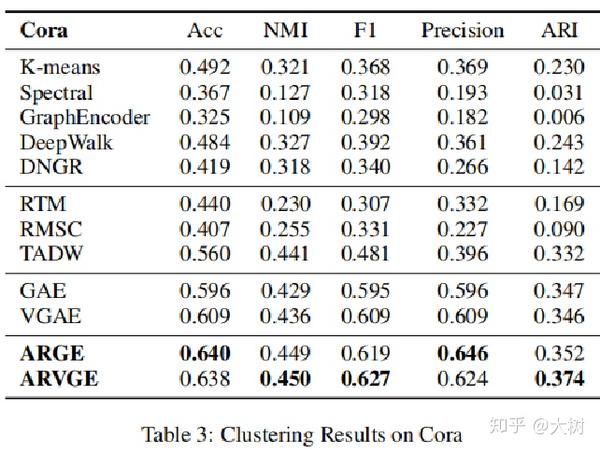

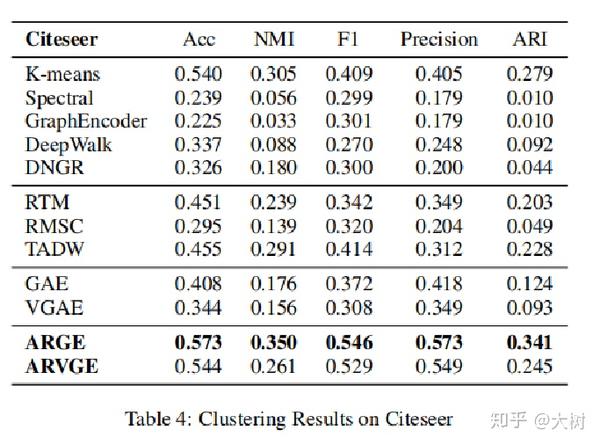

IJCAI19-Attributed Graph Clustering: A Deep Attentional Embedding Approach
motivation
1)如名,这篇文章的侧重点之一是想探索更好的利用节点信息。
2)大部分嵌入式方法都在开发深度学习方法以学习更好的的图形嵌入,然后在其上应用经典的聚类方法。但是这样两阶段式的方法由于缺乏目标导向通常会导致性能欠佳。针对这个问题已经有了一些针对分类任务的嵌入式方法,但是针对聚类任务的尚缺乏研究。
本文提出了一种目标导向的深度学习方法,简称DAEGC。DAEGC通过使用注意力网络来捕获相邻节点对目标节点的重要性,将图形中的拓扑结构和节点内容编码为紧凑的表示形式,在该表示形式上训练内部乘积解码器来重建图的结构。此外,会根据图嵌入本身生成软标签,以监督自训练图聚类过程,从而逐步完善聚类结果。通过将图嵌入到统一框架中,共同学习和优化自我训练过程。
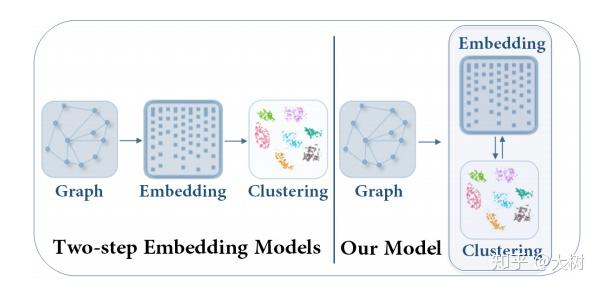

如图,左边是传统的两阶段式的模型,右图是文中提出的模型,在一个统一的框架中共同学习图形嵌入并执行聚类。
方法
模型整体框架如下图所示
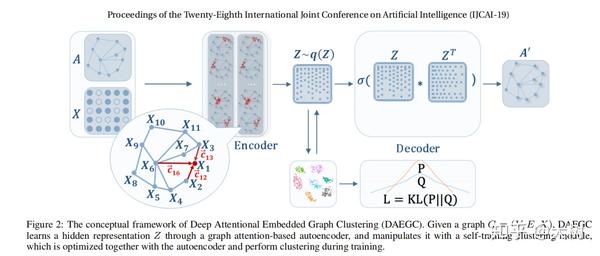

DAEGC模型整体由两部分构成:图注意力自编码器、自优化聚类。
图注意力自编码器
编码器
通过关注每个节点的邻居来学习每个节点的隐藏表示,将属性值与潜在表示中的图结构结合起来。 为了衡量各个邻居的重要性,引入attetion机制对邻居表示赋予不同的权重
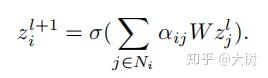
其中 N_{i} 表示第i个节点的邻居节点。
关键就是如何得到注意力权重 a_{ij} 。因为作者任务划分社区的基本思想是,同一群集中的节点通常是:(1)在图结构方面彼此靠近; (2)更可能具有相似的属性值,所有作者认为要同时考虑节点的信息和拓扑结构。
首先从节点信息来看
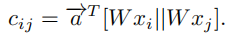
从拓扑结构上来看,邻居节点是通过边来影响目标节点的表示。由于图中经常由复杂的关联结构,文中提出要利用高阶邻居的信息。因此得到了下式中的亲和矩阵。
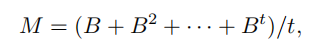
其中B通过如下规则构造:
B_{ij}=1/d_{i},if e_{ij}\in E,else B_{ij}=0\\
因此M矩阵表示了节点j到节点i直到t阶的拓扑相关性。这时 N_{i} 表示在M矩阵上节点i的邻居节点。
同时考虑节点信息和拓扑信息距离,得到最终的注意力权重
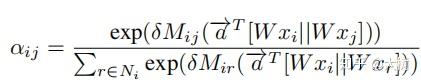

通过堆叠两层上述的attention结构,得到最终的节点表示 z_{i} 。
解码器
通过节点内积重构邻接矩阵
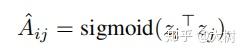
因此目标函数邻接矩阵A的重构损失
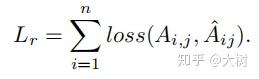
自优化嵌入
聚类任务面临的一个挑战就在于缺乏监督信息的指导。针对这个问题,文中提出了一种自优化的嵌入算法。
除了在解码器部分的重构损失外,文章还将学到的节点表示z输入到自优化聚类算法中,导出下面的损失函数。
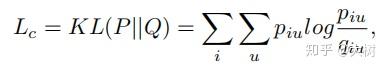
这是一个KL散度,关键是其中的 q_{iu} 和 p_{iu} 的意义。
首先 q_{iu} 使用学生t分布测量节点嵌入 z_{i} 和群集中心嵌入 \mu_{u} 之间的相似性,它也可以看作是每个节点的软聚类分配。聚类中心 \mu_{u} 通过kmeans算法获得。
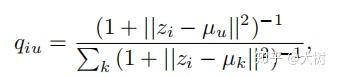
另一方面, p_{iu} 是目标分布,定义为
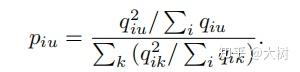
因为作者认为高概率的软分配(靠近群集中心的节点)被认为在Q中是可信赖的。因此,目标分布P将Q提高到第二次方,以突出那些“自信分配”。
由此狗仔聚类损失,即使当前分布Q接近目标分布P,从而将这些“自信分配”设置为软标签,以监督Q的嵌入学习。
接下来就可以使用损失函数 L_{c} 来更新z和 \mu 。
最终的损失函数如下
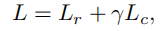
最后可以直接通过学习学到的Q来获得节点的聚类标签。
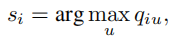
完整的算法如下图所示。


注意在每次迭代中用Q更新目标P都是危险的,因为目标一直变化会阻碍学习和收敛。 为了避免优化过程中的不稳定,实际在实验中每5次迭代更新一次P。
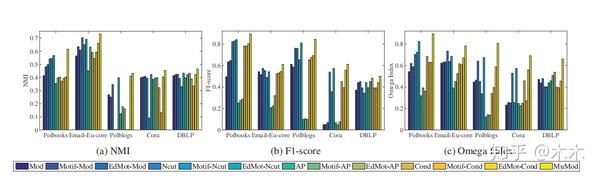
实验
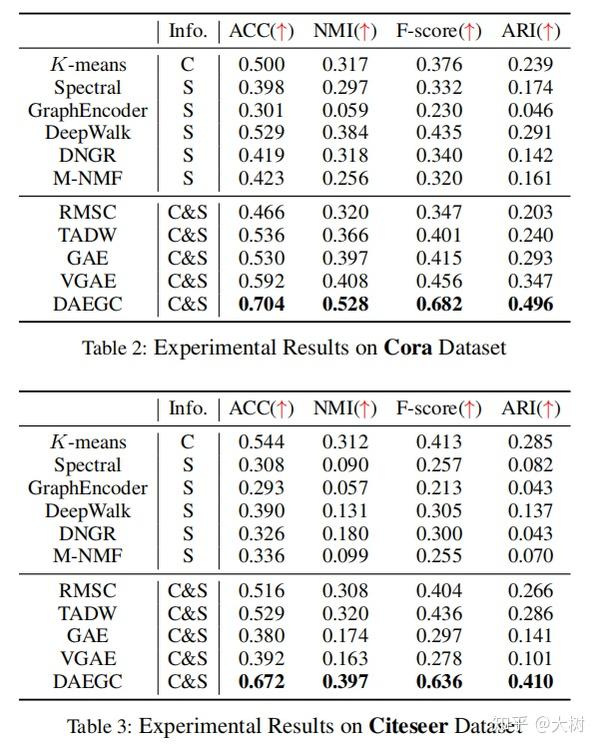

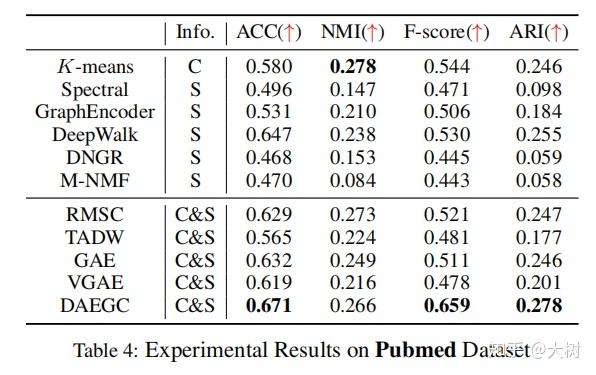

其中C,S和C&S表示算法是否仅使用内容,结构或同时使用内容和结构信息。
AAAI20-MuMod: A Micro-Unit Connection Approach for Hybrid-Order Community Detection
首先解释下这篇文章针对的高阶社区发现问题,这个高阶与低阶相对,低阶社区发现指的是依赖于单个节点和边缘的连通查找社区,而高阶则可以利用一些更大的结构譬如子图等发现社区。
最后看文章标题hybrid-order是因为本文提出的模型不仅利用了高阶连通性还利用了低阶连通性。
对于高阶社区发现问题而言,一个常用的方法是构造基于motif的超图。
首先看看motif的定义,
motif:一个密集的子网络模式在指定图结构中出现的次数要比在其他随机生成的图中出现的次数多。
根据此定义可以看出,motif代表了一个图网络中经常出现的某种模式。
通常根据Z-score选取motif
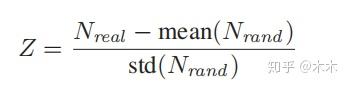
其中 N_{real} 是指该motif在该网络中出现的此时, N_{rand} 是指该motif一个大小为N的随机重组网络中出现的次数。
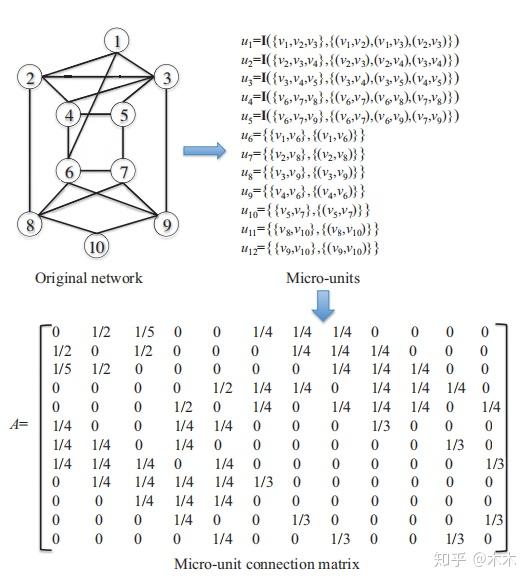
选定motif后,可以看看书中给的一个里生成motif实例与连接矩阵的例子。
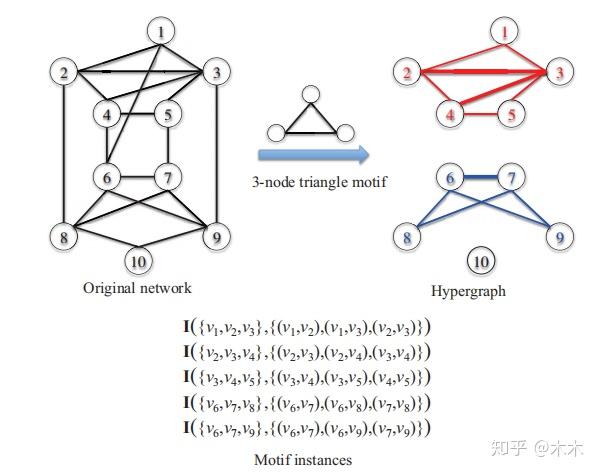

假设已经根据Z-score选出motif模式为三节点的全连接图,那么在这个网络中可以根绝这个模式找到五个符合的实例。
接下来可以根据找到的motif构造超图,即上图右边所示。可以看到,这个超图由两个连通分支和一个独立节点组成。这是因为超图的构造过程没有考虑低阶的连接,只考虑了高阶的连接,那么得到的超图必然比原来的图更稀疏。在实际应用的时候往往会导致原来的节点被过渡划分,丧失了一些重要连边。
因此作者提出要利用高阶联通的时候也要利用低阶连通性。
首先,作者提出了一个新的定义,Micro.
Micro:一个micro单元u可以是一个motif或者是一个没有出现在motif中的边。
(1) 如果micro是一个motif, u=I(\{v_{x_{1}},…,v_{x_{p}}\},\{e_{y_{1}},…,v_{e_{q}}\})
(2) 如果micro是一个边,u=\{\{v_{i^{'}},v_{i^{''}}\},{e_{i}}\}
micro的联通
定义两个micro之间的连接权重为
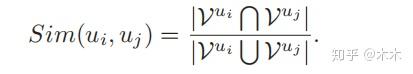
那么针对三节点全联通模式的motfi对应的micro,对应的权重有如下可能。
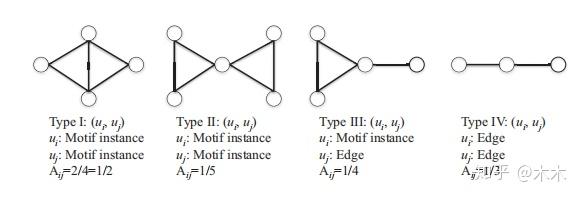

由此可以定义micro间的连接矩阵
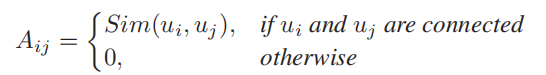

再次回到之前给的图例,根据我们刚才定义的micro可以得到如下连接矩阵

以上都是作者针对motif构造的超图缺乏低阶连通性提出的micro及其相关概念。下面就是要根据得到的超图进行聚类划分了,即将得到的micro-based network划分为几个不相交的micro组,记为S。
划分的目标是要找到紧密联系的micro组。 对于每个组s∈S,组s中的micro连接强度的总和和组s中的预期micro连接强度的总和相比应尽可能大。因此作者基于Newman提出的模块度的概念,提出了基于micro的模块度


类似于经典的模块化方法,从micro连接网络A构造随机重新连边的邻接矩阵 A^{'} ,同时要保持每个micro-unit的度分布相同。由于每个micro-unit有为两种类型,对于任何两个微单元 u_{i}和 u_{j} ,预期的连接强度具有以下四种情况。
(1) u_{i} 为motif,u_{j}为motif
A_{ij}^{'}=\frac{d_{i}^{MM}\cdot d_{j}^{MM}}{2\mu^{MM}}\\
其中 d_{i}^{MM} 表示 u_{i} 和其所有邻接motif的连接强度(类似于度的概念), \mu^{MM}=\frac{1}{2}\sum_{i}{d_{i}^{MM}}
(2)u_{i} 为边,u_{j}为边
A_{ij}^{'}=\frac{d_{i}^{EE}\cdot d_{j}^{EE}}{2\mu^{EE}}\\
其中 d_{i}^{EE} 表示 u_{i} 和其所有邻接的边的连接强度, \mu^{EE}=\frac{1}{2}\sum_{i}{d_{i}^{EE}}
(3)u_{i} 为motif,u_{j}为边
A_{ij}^{'}=\frac{d_{i}^{ME}\cdot d_{j}^{EM}}{2\mu^{ME}}\\
其中 d_{i}^{ME} 表示 u_{i} 的所有邻接的边的连接强度,d_{i}^{EM} 表示 u_{i} 的所有邻接的motif的连接强度, \mu^{ME}=\frac{1}{2}\sum_{i}{d_{i}^{ME}}=\frac{1}{2}\sum_{j}{d_{j}^{EM}}
(4)u_{i} 为边,u_{j}为motif
类似(3),就不再赘述了。
通过上面对于 A_{ij}^{'} 的定义,可以将Q重写为
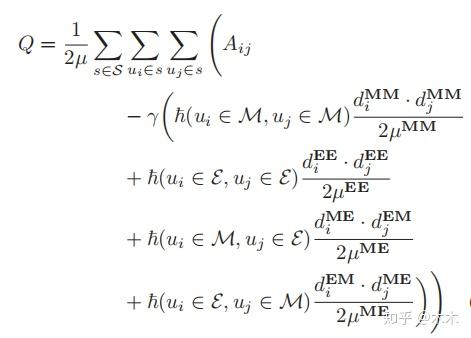

其中h(x,y)为指示函数,当x,y均为真时才为1,否则为0。\mu=\frac{1}{2}\sum_{i,j=1}^{|\{u\}|}A_{ij} .
进一步,可以引入基于micro的模块度矩阵B简化上式。
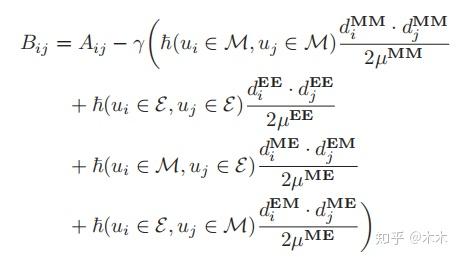

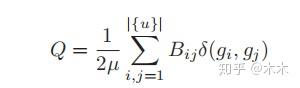
其中 \delta(x,y) 为克罗内克函数,只有x=y时为1。
至此,现在可以使用一般的模块度算法解决了,文中是使用generalized Louvain为每个group分配最有可能的group标签。
最后整体算法结构如下图所示


通过以上介绍,可以看到由于节点可能在多个micro-unit出现,因此可以为同一个节点分配多个聚类标签,而且很一般的重叠划分聚类问题相比,该方法不用设置阈值(达到某个阈值,就将这个数据划分到这个聚类)。
实验