
贝叶斯深度学习研究进展

贝叶斯深度学习融合了贝叶斯方法和深度神经网络的互补优势,为应对复杂问题中的不确定性建模与推断提供了强大的工具,近期在推断算法和概率编程库等方面已取得显著进展。本文将从模型、算法、概率编程库等方面介绍贝叶斯深度学习的研究进展。


背景
人工智能近期的进展显示,通过构建多层的深度网络,利用大量数据进行学习,可以获得性能的显著提升。目前,以神经网络为主的深度学习技术已经在众多领域获得应用,包括图像识别、人脸识别、自然语言处理等。但是,深度神经网络模型也面临多方面的挑战,其预测结果往往过于乐观,即“不知道自己不知道”。例如,对于分类的神经网络,模型的输出通常是一个“归一化”的向量(概率),使用者常把此概率解释成“置信度”,但实际上它并不能客观地反映不确定性[1]。如图1所示,给定“猫”和“狗”两类训练数据,学习一个分类器,左边为“猫”类,右边为“狗”类。对于一个“无穷远”的测试数据,该分类器会非常“确信”地分为“狗”(或者“猫”)。但实际上,该测试数据已经远离训练集,具有“很高”的不确定性。
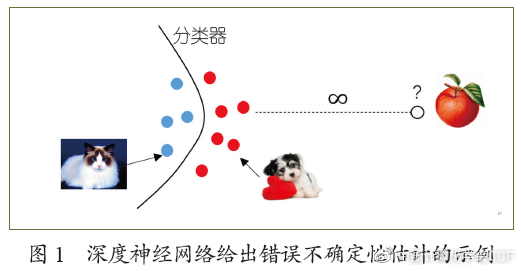

为了让人工智能系统明确边界,“知道自己不知道”,需要合理地处理不确定性。不确定性一般分为两个方面[2]:
· 偶然不确定性(aleatoric uncertainty)或数据不确定性。在真实环境下,由于随机噪声、信息缺失等因素,数据存在普遍的不确定性,例如,开放环境下的无人驾驶车辆在路测时会面临路况、交通、行人等各种未知的随机因素。在某些情况下,甚至会出现恶意的噪声,例如,在一张图片中加上少量的对抗噪声,虽然人眼无法察觉视觉效果上的区别,但足以让主流的深度神经网络产生误判[3]。
· 认知不确定性(epistemic uncertainty)或模型不确定性。现在的模型“体量”越来越大,参数数量动辄达到千万或上亿,近期甚至出现千亿参数的模型(如GPT-3)。对于超大模型,我们需要关注一个问题:训练数据中的有用信息是否足够支持学习一个最优的模型?研究结果表明,数据集中“有用”信息的增长速度通常是远低于线性的[4]。因此,有用信息的增长可能“跟”不上模型体量的增长速度。在这种情况下,会出现多个模型在训练集上表现无异,但在测试集上可能差别很大的现象。
认知不确定性描述的是我们对真实模型的“无知”程度,在给定足够多数据时,是可以被消除的。但偶然不确定性是数据中固有的,不会随着数据集增大而减弱。
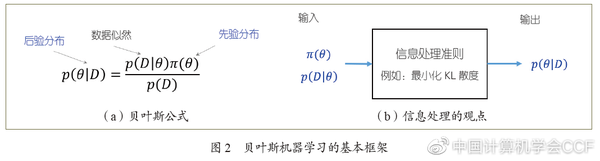
贝叶斯机器学习为处理不确定性提供了一套严谨的工具。其核心是贝叶斯定理(也称贝叶斯公式),如图2(a)所示。与传统深度学习仅关注单个模型不同,贝叶斯学习考虑了无穷多个可以拟合训练数据的模型,并基于此做出更精确的不确定性建模。具体来说,贝叶斯公式基于先验分布和似然函数推导出后验分布。先验分布是指在没看到数据之前,对模型不确定性的概率刻画;而似然函数则提供了一个对数据不确定性进行建模和推断的途径。贝叶斯公式充分结合先验分布和经验数据,综合得到模型的后验分布。
贝叶斯定理可以看作是一种信息处理系统,如图2(b)所示,其输入为先验分布和数据似然,输出为模型的后验分布。当我们选择最小化KL散度时,该准则等价于贝叶斯公式。这种基于信息论的解释可以让贝叶斯方法更广泛地得到应用,例如:正则化贝叶斯(RegBayes)[5]通过对一个特定的目标函数进行最优化,并结合适当的约束,得到更加符合学习任务的“后验分布”。RegBayes指导发展了一系列新算法,包括将最大间隔准则与贝叶斯推断融合[6、7]、将专家知识(如一阶谓词逻辑表示的知识)融入到贝叶斯推断中[8]等。

模型
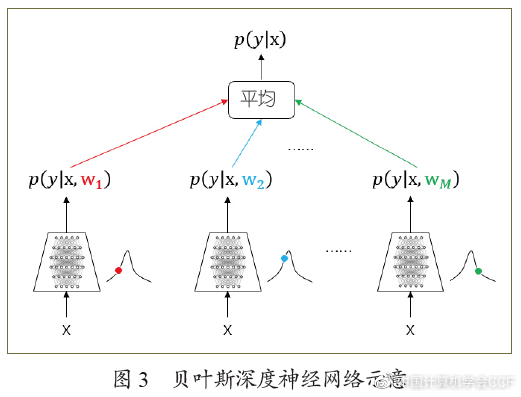
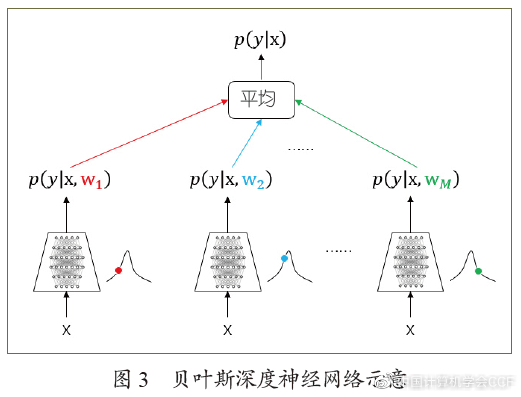
贝叶斯方法和神经网络的“联姻”由来已久,至少可以追溯到上世纪90年代。当时面临的困难和主要问题是数据缺乏和计算能力有限,很多神经网络的结构非常浅,深度模型很容易过拟合。早期探索的主要目的是希望对神经网络进行贝叶斯计算,或者利用贝叶斯方法选择合适的网络结构,克服过拟合,这种模型被称为贝叶斯神经网络(Bayesian neural networks)。其在预测时对后验分布的“无穷”多个模型进行“平均”,原理如图3所示。
举两个代表性的例子。英国皇家学会会士大卫·马凯(David MacKay)教授(导师是美国科学院院士约翰·霍普菲尔德(John Hopfield))在其博士论文中使用贝叶斯方法进行神经网络结构的选择,该论文中有一个非常著名的结论,即贝叶斯学习在一定程度上可以等价于奥卡姆剃刀准则[9]。另一篇博士论文来自多伦多大学统计系教授雷德福德·尼尔(Radford Neal)(导师是图灵奖得主杰弗里·辛顿(Geoffrey Hinton)),尼尔在他的博士论文中也是用贝叶斯方法对神经网络进行计算,并且得到一个非常漂亮的结论:在选择合适的先验分布的情况下,当神经网络的隐含层宽度(神经元个数)趋于无穷时,贝叶斯神经网络等价于高斯过程[10]。这个结论也引起很多学者对高斯过程的关注,使之成为不确定性建模与推断的主要模型之一。
在深度学习时代,随着神经网络变得越来越深,仍然可以到处看到贝叶斯方法的身影。例如,Dropout[11]是一种简单有效的训练技巧,在每轮迭代时,随机丢掉一些权重,对保留的权重进行更新,这种策略被证明是行之有效的。但在辛顿最早提出Dropout的时候,并没有解释Dropout背后的原理。后来的研究发现,Dropout实际上是一个近似的贝叶斯神经网络[12]。基于这种理解,可以通过多次采样,推导出更准确估计预测置信度的方法,称为MC-Dropout。
另外,神经网络的结构搜索是近期很受关注的一个方向。10年前就有学者研究如何用贝叶斯方法随机生成神经网络的结构[13]。具体地,该方法通过定义一个非参数化贝叶斯先验,刻画深度神经网络的结构(包括神经网络的层数、每一层神经元的个数、相邻层神经元之间的连接方式,甚至每个神经元的响应类型等),给定有限的训练数据,通过贝叶斯公式推断出后验分布,该后验分布描述了适合训练数据的各种可能的神经网络结构。当然,该方法也不完美,当时受限于算力和算法,只能学习相对浅层的网络结构。近期的一些研究进展在一定程度上克服了这个问题[14]。
除了将贝叶斯方法用于深度神经网络,贝叶斯深度学习还包括另外一个重要的内容——将深度神经网络当作强大的函数拟合器,用于贝叶斯模型。这方面的工作也称为深度贝叶斯学习(Deep Bayesian Learning),近期的典型研究进展为深度生成模型:一个简单的隐变量(如均匀分布或标准高斯分布)经过适当的函数变换之后,可以建模复杂的数据分布,如图4所示。在实际应用中,我们能拿到的是训练数据,因此,需要“逆向工程”得到对应的变换函数。当我们不清楚变换函数的形式时,可以利用深度神经网络来定义一个可行解的集合,通过无监督训练得到(近似)最优的网络。这种方法被证明非常有效,可以将简单随机变量输入神经网络进行变换,然后得到信息丰富的图片,在表示学习[15]和半监督学习[16]等领域也有广泛的应用。
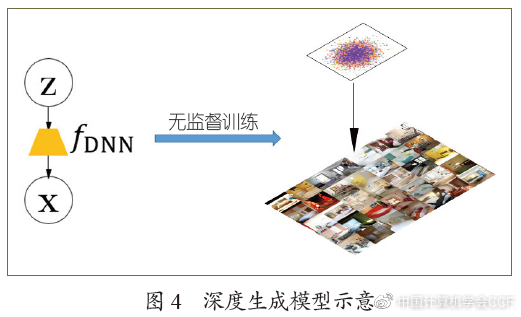

机器学习领域对深度生成模型有深入、系统的研究,可分为显式模型和隐式模型两类。显式的模型对数据产生的过程有明确的概率函数刻画,典型的例子包括变分自编码器(VAE)[16]和基于可逆变换的流(flow)模型[17]。隐式的模型不关心概率密度函数的形式,只关心样本产生的过程,例如生成对抗网络(GAN)[18]就是一个典型的隐式模型。
算法
贝叶斯深度学习模型为推断和学习算法带来了很多新的挑战,特别是深度神经网络的复杂非线性使得后验分布在高维空间中具有很多个模式 (mode)。面对这些挑战,近期算法方面取得了一些重要进展,主要有两类算法。
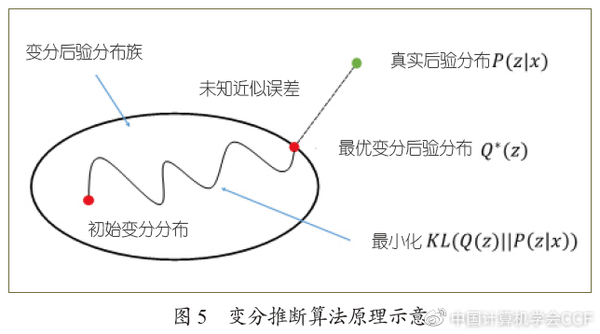
一种是变分法。因为直接计算后验分布非常困难,所以变分法的操作手段主要是找“近似”,如图5所示,假设有一个简化的概率分布Q(称为变分后验分布),这个Q在某个分布的集合中,然后通过一个最优化的问题来找到一个最优的逼近。最大期望算法(Expectation-Maximization algorithm,EM)就是一种典型的变分法。变分法实际上是将推断问题和优化结合在一起,所以会用到很多比较先进的优化技巧,可以让变分法非常高效。变分法的主要困难是要设计一个灵活的变分分布,并对变分优化的目标函数及其梯度进行有效计算或估计。这里需要重点克服随机梯度的方差过大、训练过程难以收敛的挑战,为此,近期一些工作研究了新的控制变量(control variate)技术[19]、具有解析形式的核密度估计方法[20]、基于核函数谱分解的估计方法[21],以及在泛函空间中的梯度估计方法[22],获得随机梯度的更稳定的估计。但是变分法的天然缺点是:如果Q的取值范围不够大,可能会带来无法消除的近似误差。

另一种是蒙特卡洛方法,采用的是随机采样的思想。图6为蒙特卡洛算法原理示意图,展示了模拟粒子演化的过程:粒子不断演化,如果模拟时间足够长,最终会收敛到想要的目标分布。蒙特卡洛方法在理论上可以保证精确性,但是在参数维度高的情况下效率比较低,体现在两方面:一是收敛速度比较慢,二是粒子的利用效率比较低。对于蒙特卡洛算法,近期研究基于物理学中的动力学(如哈密尔顿动力学),结合统计模型的特点,在每次迭代过程中通过随机采样获得统计量(如梯度)的某种无偏估计,并采用有效的降低方差的措施(如上述的控制变量、核密度估计等技术),在高维空间中进行快速的模型更新[23,24]。


深度概率编程库
易于使用的编程框架是推动深度神经网络得到广泛应用的一个重要力量。在国外,有早期的Caffe、Theano,以及目前被广泛使用的TensorFlow、PyTorch等;在国内,有百度、华为等公司相继推出的PaddlePaddle和MindSpore等,清华大学教授胡事民团队也发布了“计图”。以上工具均为深度神经网络的编程实现提供了良好的支持。
相对于神经网络的编程,对贝叶斯深度学习模型和算法进行有效编程更有挑战性。一方面,编程的对象是深度概率模型,模型的构成由张量、神经网络层推广到了随机变量和概率分布,需要更富有表达能力的建模方式。另一方面,如前文所述,这类模型的学习和推断算法相比神经网络中使用的随机梯度下降更复杂,除优化外,还涉及到概率分布的推断、随机变量的期望计算等操作。具备这些建模和学习能力的编程库被称为概率编程(probabilistic programming)。
与传统的贝叶斯学习不同,贝叶斯深度学习模型具有高度的非线性特性。因此,需要进行可微分的概率编程,在无需概率分布具体形式的情况下实现贝叶斯模型的学习和推断。从2014年起,学术界进行了一些探索,开发了一系列可微分的概率编程算法[15]。笔者团队是国际上最早开始研究可微分深度概率编程的团队之一,于2017年推出自主研发的“珠算”深度概率编程库(https://zhusuan.readthedocs.io),是一个构建于TensorFlow之上的Python库。和现有的主要为监督式任务设计的深度学习库不同,“珠算”的特点是根基于贝叶斯推断,因此支持各种生成模型:既包括传统的层次化贝叶斯模型,也有前文中提到的深度生成模型。
之后,企业界也对深度概率编程产生了浓厚兴趣。例如,2019年,Google在TensorFlow上添加了概率层(probability layer);Uber研究院也于2019年推出基于PyTorch的Pyro。自2019年起,“珠算”先后与华为的MindSpore、百度的PaddlePaddle等国产编程库进行融合,进一步推广深度概率编程,并取得了初步进展。
总结与展望
贝叶斯深度学习融合了贝叶斯方法和深度神经网络的互补优势,为应对复杂问题中的不确定性建模与推断提供了强大的工具,近期在推断算法和概率编程库等方面已取得显著进展。未来值得探索的方向包括:(1)进一步完善和发展更加准确高效的推断算法及可微分的概率编程库,推动贝叶斯深度学习方法在实际应用中的落地;(2)设计合理的模型应对无监督学习、小样本学习、面向噪声数据及结构化数据(如时序数据、图数据等)的学习问题等,提升数据利用效率;(3)利用贝叶斯建模的工具,对不完全信息和不确定环境进行建模,发展对抗鲁棒性强、可解释的预测和决策模型。
(参考文献略)
特别声明:中国计算机学会(CCF)拥有《中国计算机学会通讯》(CCCF)所刊登内容的所有版权,未经CCF允许,不得转载本刊文字及照片,否则被视为侵权。对于侵权行为,CCF将追究其法律责任
作者介绍

朱军CCF杰出会员、CCF青年科学家奖获得者。清华大学教授,人工智能研究院基础研究中心主任。主要研究方向为机器学习基础理论、高效算法及应用。
dcszj@tsinghua.edu.cn

陈键飞 CCF学生会员,2019年度CCF优秀博士生论文奖获得者。清华大学博士后。主要研究方向为机器学习。chrisjianfeichen@gmail.com

李崇轩CCF专业会员,2019年度CCF优秀博士生论文奖获得者。清华大学博士后。主要研究方向为统计机器学习。
chongxuanli1991@gmail.com

